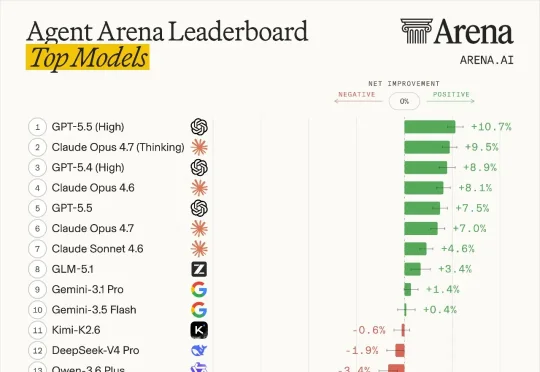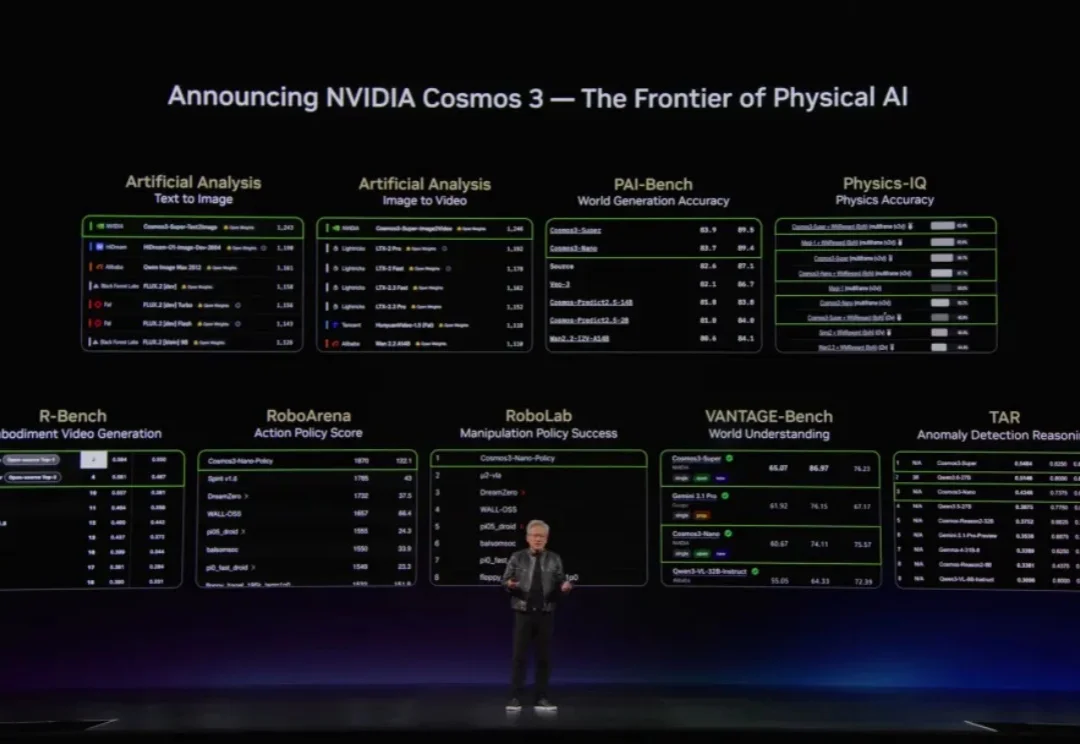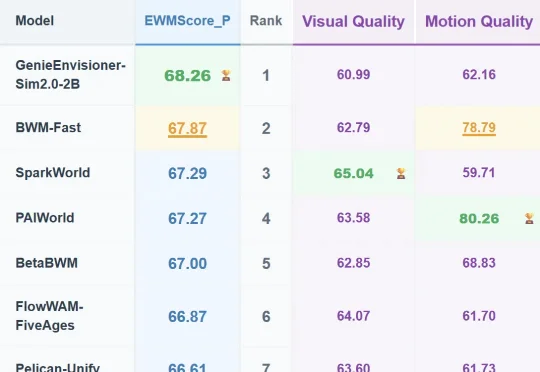
PEFT方法评测不能只看下游分:通用能力损失也该被量化
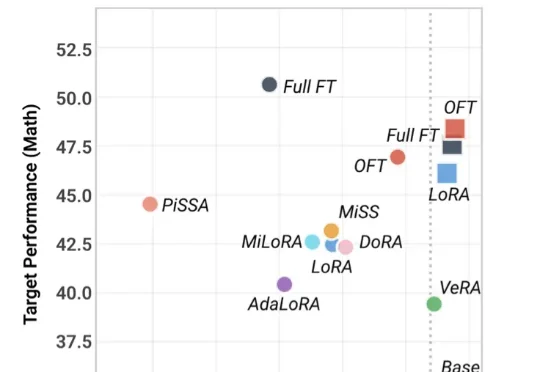
PEFT方法评测不能只看下游分:通用能力损失也该被量化近期,来自香港中文大学、西湖大学、德国马普所等机构的研究者提出了 PEFT-Arena —— 一个从稳定性‑可塑性权衡(stability–plasticity trade-off)视角重新审视 PEFT 方法的评测基准与分析框架。该工作已在 ICLR 2026 相关 workshop 上进行了展示,并开源了完整代码。
来自主题: AI技术研报
10222 点击 2026-06-14 10:38