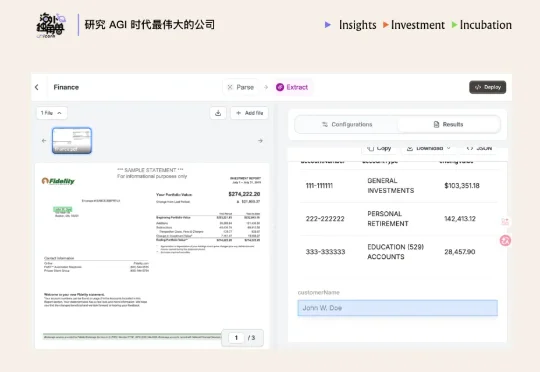
Legora、Mercor 都在用,Reducto 能成为独立的 LLM 数据入口吗?
Legora、Mercor 都在用,Reducto 能成为独立的 LLM 数据入口吗?Reducto 在去年 6 个月内接连完成分别由 Benchmark 与 a16z 领投的两轮融资,估值翻了 3 倍,达到 6 亿美元。我们认为,Reducto 切中了 AI 应用走向生产环境过程中的“精确数据摄取”瓶颈。
来自主题: AI资讯
9872 点击 2026-03-14 08:41
 搜索
搜索
Reducto 在去年 6 个月内接连完成分别由 Benchmark 与 a16z 领投的两轮融资,估值翻了 3 倍,达到 6 亿美元。我们认为,Reducto 切中了 AI 应用走向生产环境过程中的“精确数据摄取”瓶颈。
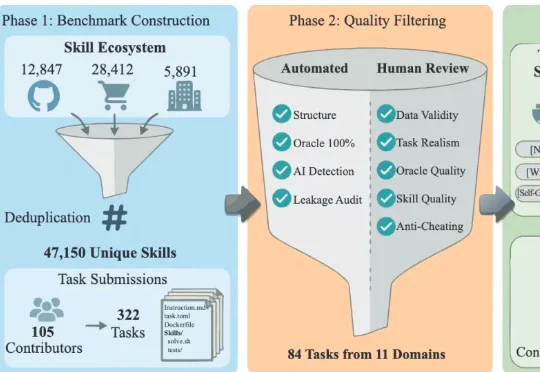
近日,一篇名为《SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks》的论文预印本引爆了海外 AI 社区,YC 总裁 Garry Tan 亲自转发,登顶 Hacker News(363 票 / 163 评论),霸榜 AlphaXiv #1,

导读:近日,位于中关村的深度机智全球首次使用全新范式——人类学习,在多个国际 Benchmark 上取得 SOTA,史无前例地使用全新架构(仅使用人类第一视角数据、零真机数据)击败 Physical Intelligence 和英伟达等头部巨头二十多个百分点,并在两会开幕首日被央视报道。
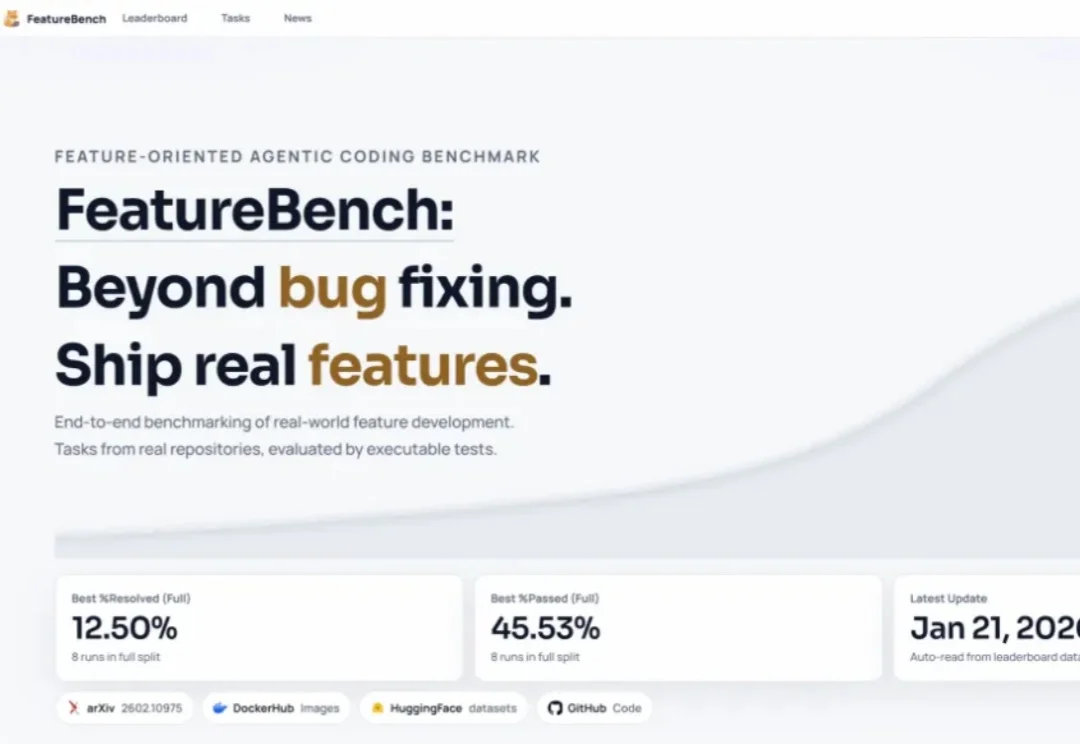
在 Princeton 发布 SWE-Bench 之后,用真实世界代码仓库+可执行测试评测大模型软件工程能力,几乎已成为学术界与工业界的共识。围绕 SWE issue 的评测范式迅速发展,也催生了一系列 SWE 系列 benchmark,在刻画模型 bug 修复能力方面发挥了重要作用。

来自阿里高德的一篇最新 ICLR 2026 中稿论文《Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models》提出了面向文生图空间智能的系统性评估基准 SpatialGenEval,旨在通过长文本、高信息密度的 T2I prompt 设计,以及围绕空间感知

百川智能表示今年上半年,将陆续发布两款 to C 的医疗产品。 作者|Li Yuan 编辑|郑玄 你有没有向 AI 助手问过你的健康问题? 如果你和我一样是一个 AI 的深度用户,大概率你也试过。 O
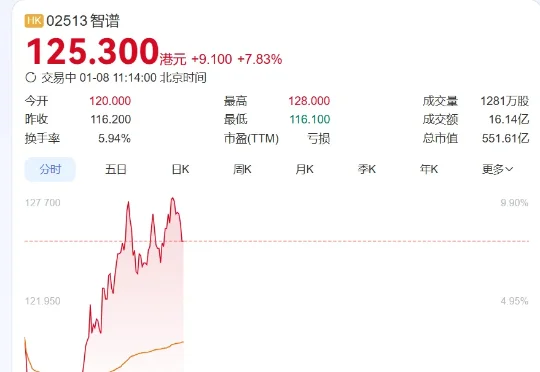
1月8日,大模型六小龙第一股,智谱上市了,市值直超551亿港元,而且一路涨幅超已逾7%。而就在上市前一天,小编注意到,智谱创立发起人兼首席科学家唐杰在微博上发布了一条充满预告意味的帖子,称:“AA(artificialanalysis)换了几个benchmark,基本是把原来刷爆的都换了,现在评估越来越难,新增加的Physical Reasoning貌似还很难。。。。”
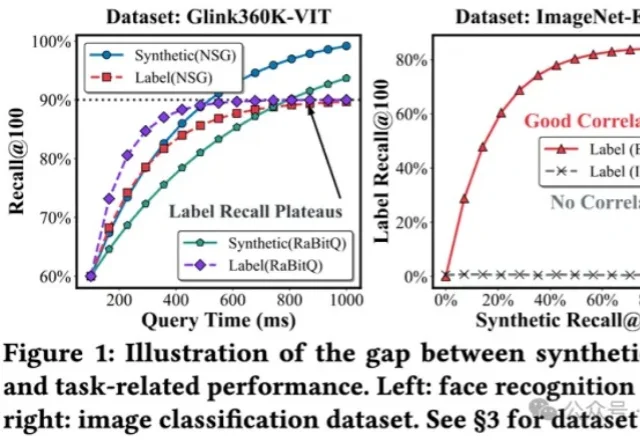
将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。

基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。
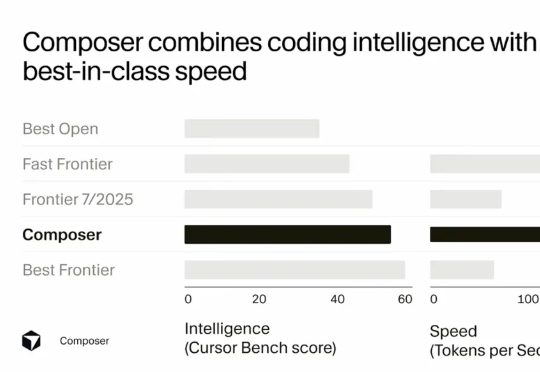
Sasha Rush 在分享开头就提到,Cursor Composer 在他们的内部 benchmark 上的表现几乎与最好的 Frontier 模型(前沿模型)持平,并且优于去年夏天发布的所有模型。它的表现明显好于最好的开源模型,以及那些被标榜为"快速"的模型。