ECCV'26| 看起来会动,还要动得合理:从生成模型中主动寻找物理证据
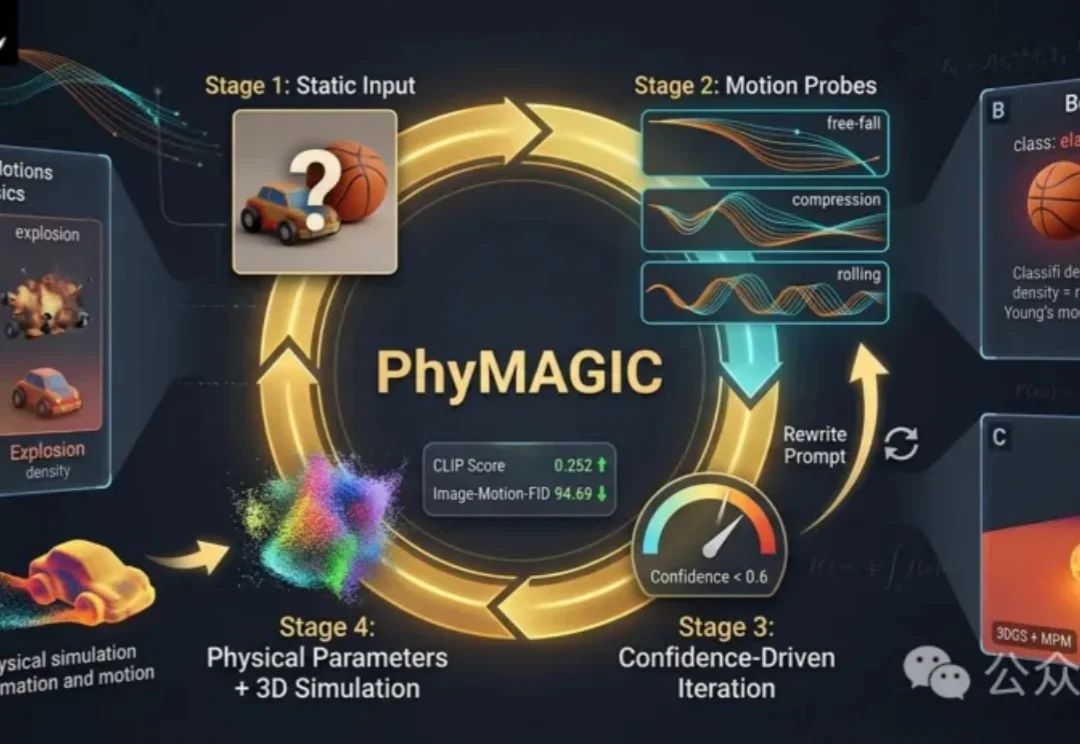
ECCV'26| 看起来会动,还要动得合理:从生成模型中主动寻找物理证据PhyMAGIC通过让物体动起来,从视频中提取物理证据,帮助准确推断材料属性。它结合图生视频与视觉语言模型,生成针对性运动探针,并不断修正物理参数,最终构建出可微分的3D动态模型,实现更符合现实的视频生成。
来自主题: AI技术研报
5708 点击 2026-07-17 10:09
 搜索
搜索
PhyMAGIC通过让物体动起来,从视频中提取物理证据,帮助准确推断材料属性。它结合图生视频与视觉语言模型,生成针对性运动探针,并不断修正物理参数,最终构建出可微分的3D动态模型,实现更符合现实的视频生成。

为了打破多镜头长视频面临的高延迟、零交互困境,香港中文大学与快手可灵团队联合提出了首个实时流式多镜头长视频生成框架 ——ShotStream。该研究打破了传统双向架构的限制,将多镜头合成定义为基于历史上下文的下一镜头生成任务,用户可以通过动态流式提示词在运行时动态指导叙事走向!更令人振奋的是

视频虚拟试衣(VVT)作为电商展示与数字内容创作中的核心技术,已在动态人物换装、服装纹理保持和视频时序连贯性方面取得显著进展。然而,现有方法大多仍受限于固定相机视角,生成结果被动依赖源视频的原始相机轨

近期, ECCV 2026 结果公布,Realsee 团队的成果 Argus: Metric Panoramic 3D Reconstruction for Indoor Scenes 成功入选。它面向室内全景图像,能够从稀疏、无序的全景照片中,直接预测相机位姿、度量深度和点云重建结果,可以为 3DGS 提供更稳定、更精准的几何约束。

来自哈佛大学、MIT、IBM、波士顿大学、谷歌、JHU、CMU 和 Kempner Institute 的研究者提出了一个新的诊断性基准:MemoBench。这是首个面向动态环境的「消失-重现」世界建模评测基准,并已被计算机视觉顶会 ECCV 2026 接收。其一作 Haoyu Chen 为哈佛大学计算科学与工程专业一年级硕士生,师从哈佛大学计算机科学助理教授 Yilun Du。

还在用 DragGAN、DragDiffusion 拖拽修图?点选拖拽容易变形、边界割裂、细节丢失的时代落幕了!ECCV 2026 ICRDrag 首创上下文区域拖拽模型,用掩码精准定位局部区域,移动、缩放、变形全都丝滑自然,兼顾精准度与画面真实感。
今天,我们将面向任何用户推出OmicOS Science正式版(https://omicos.cn/),无论您处于世界上的任何区域,无论您使用的是任何模型,都可以享受AI时代的红利!我们深知,科学研究最关键的一环是可审计与可复现性。在OmicOS Science中,点击生成的每一张图,你都能看见这张图绘制的代码

LinStereo 对应地做了三件事:PALA 换掉 ConvGRU 解决传播问题,HSCV 保留多尺度特征,DPI 用单目深度给一个靠谱的起点。PALA 做的事情说起来很直观,就是把 ConvGRU 的局部更新换成全局注意力,让每个像素每次迭代都能看到整张图。难点在于 softmax attention 是 O (N²) 的,直接用在高分辨率视差图上跑不动。

来自上海交大、马来亚大学、CMU、MBZUAI、KIT和KAUST的团队提出VisNec(Visual Necessity Score,视觉必要性分数),用一个分数衡量每条训练样本里“图像到底起了多大作用”,被ECCV 2026收录。
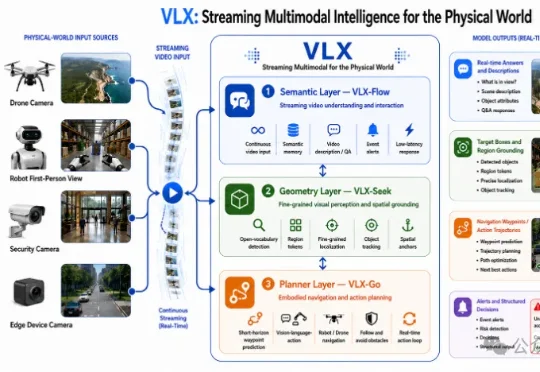
刚刚,Om AI发布全球首个面向物理世界的端侧流式多模态模型系列——VLX。VLX主打真实世界的端侧与具身场景,总共三款模型,三天连发:这三款模型连起来,不仅构成了多模态模型持续感知、精准定位、行动决策的能力闭环。