「开源Claude时刻」,智谱GLM5.2与Mythos被放在一起了
「开源Claude时刻」,智谱GLM5.2与Mythos被放在一起了这个周末,智谱没闲着。
来自主题: AI资讯
6957 点击 2026-06-29 15:54
 搜索
搜索
这个周末,智谱没闲着。

就在最近,英国前首相府数据科学家Liam Wilkinson,花一个周末搭了76个MCP工具,把Claude、GPT、Gemini等四个顶尖模型扔进了《文明VI》。结果,23场对局打完,其中一个AI造了核弹炸了法国——然后输了。

封杀两周后,美国突然解禁Anthropic最强AI模型,却只限白名单上的百家巨头!全球用户被拒之门外,GPT-5.6也紧随其后搞「美国专属」。我们还能用到Claude 5吗?
我们来看下这个号称是「Andrej Karpathy 实际使用的 CLAUDE.md 文件」究竟讲了啥?链接:https://drive.google.com/file/d/1mtJKbu-QRk62WTWkyc0M0pGXbKzisA5W/view

Cursor AI官方发布重磅研究,实锤包括自家模型在内的顶级AI,在编程评测中大规模「偷看答案」:Opus 4.8高达87.1%的惊人成绩,断网后直接暴跌至73.0%,其中63%的「解题」竟非独立推导。
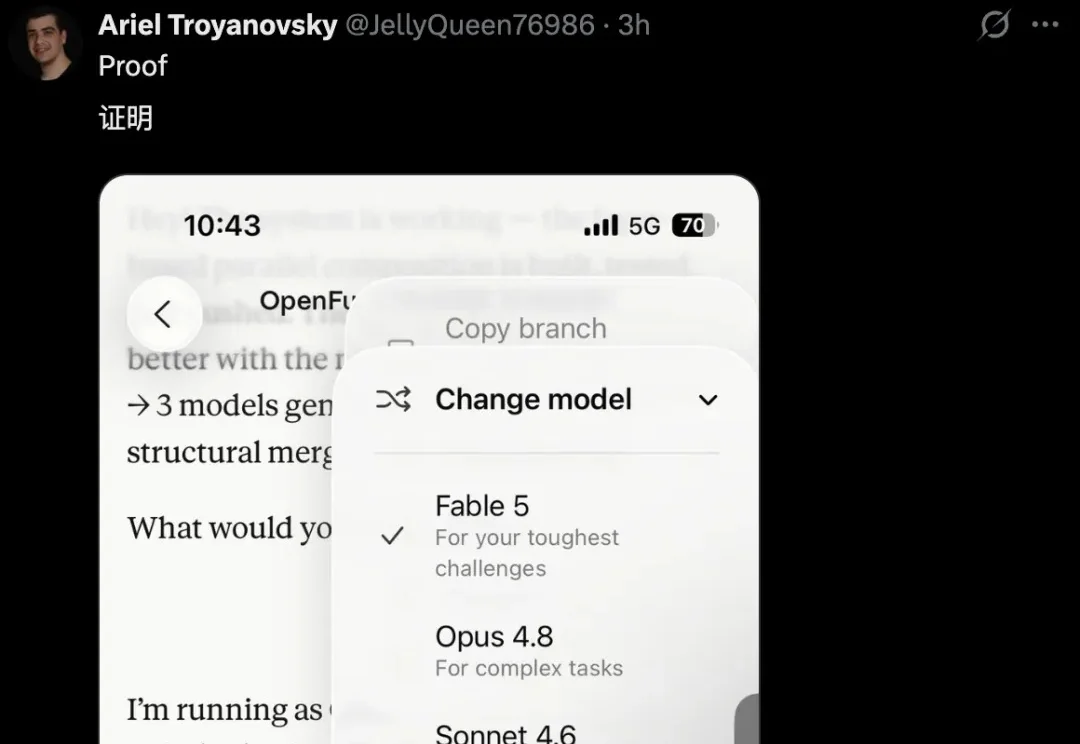
Claude Fable 5,回来了。
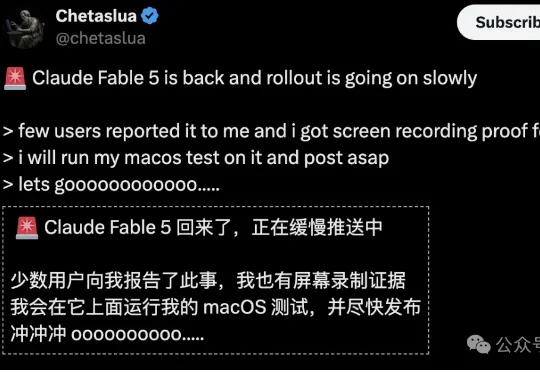
就在刚刚,一个消息让整个AI圈兴奋起来——被禁用多日的Fable 5,疑似开始部分解禁了。就在昨天下午,有网友直接甩出了实机录屏铁证!
前两天,Anthropic 发布了 Claude Tag,可以把 Claude 变成你 Slack 里的常驻同事,不仅能以同事身份参与团队协作,支持多人共享同一会话线程,最重要的是,它还具备主动持续学
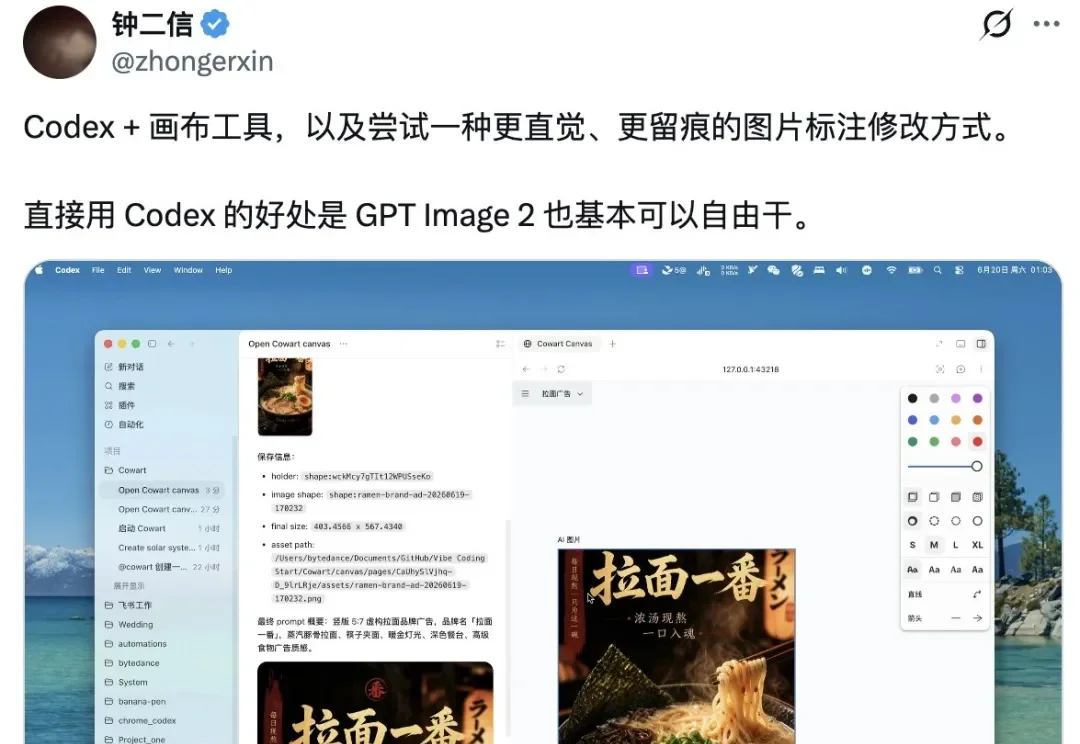
和 Codex、Claude Code 等 Coding Agent 沟通,很多时候就像站在许愿池边,对着池子里的王八扔硬币,嘴里念念有词,关键它还真给你兑现愿望。

刚被「封印」,Fable 5就要满血复活?最近,Claude Fable 5代码痕迹曝光,开发者圈一片欢呼,而外媒爆料,Anthropic最近一路顺利,背后竟是因为CEO被白宫赶下谈判桌!