
Claude Agent突然大更新!狂塞500个技能,网友直呼疯狂
Claude Agent突然大更新!狂塞500个技能,网友直呼疯狂过去45天,Anthropic几乎没停过手。
来自主题: AI资讯
7185 点击 2026-07-23 16:02
 搜索
搜索
过去45天,Anthropic几乎没停过手。
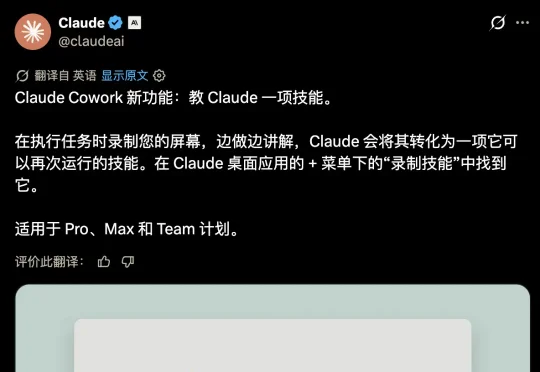
现在,你可以通过录屏 + 语音讲解的方式,彻底把自己蒸馏成 Skill 了。7 月 21 日,Anthropic 在 Claude 桌面端 Cowork 的 + 菜单里加了一项「Record a Skill」:录屏,一边操作一边用语音讲解,录完后 Claude 自动把演示转化成一个可复用的 Skill。

GPT-5.6-Sol 的攻防能力超越了 Claude Mythos 5!
Flova 很受关注,融资是一方面,两轮融资,红杉、IDG 和云九资本投资,累计超 8000 万美元,据说是目前视频 Agent 产品的最大融资。而更主要的原因,可能是创始人郭列。郭列 2013 年做出脸萌,之后是 FaceU 激萌,2018 年被字节跳动以 3 亿美金并购,随后在字节孵化了轻颜相机、剪映和醒图。2025 年创业做 Flova,入局视频 Agent 赛道。

今天上午,一位在 Anthropic 工作的数学家 Levent Alpoge 发了一条推文。学术圈的反应很快。斯坦福的数论学家 Jared Duker Lichtman 转发并逐步拆解了这个反例,还顺手挖出了一段几乎像电影桥段的历史巧合(后面细说)

算力承压,Kimi 暂停 C 端新用户订阅、OpenAI 战略未来负责人:Kimi K3 性能接近 2026 年第一季度最佳公开模型、Claude Fable 5 官宣永久可用、IDC 预计 2030 年全球活跃智能体将超过 22 亿个
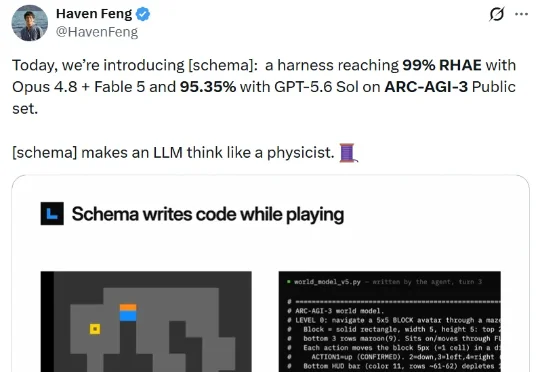
7 月 16 日,伯克利博士后 Haven Feng 的一条推文火了。原因无他,结果很震撼:在 ARC-AGI-3 Public 集上,一套名为 [schema] 的智能体框架,与 Claude Opus 4.8、Fable 5 组合后达到 98.98% 的 RHAE;换成 GPT-5.6 Sol 组合,分数也有 95.35%。

这将是一个充满生产力的周末。就在刚刚,Claude 宣布当时时间 7 月 20 日起,Fable 5 继续留在所有 Max 和 Team Premium 套餐里,限额 50%。Pro 和 Team Standard 用户继续用积分访问,另外给用户发 100 美元的一次性积分。
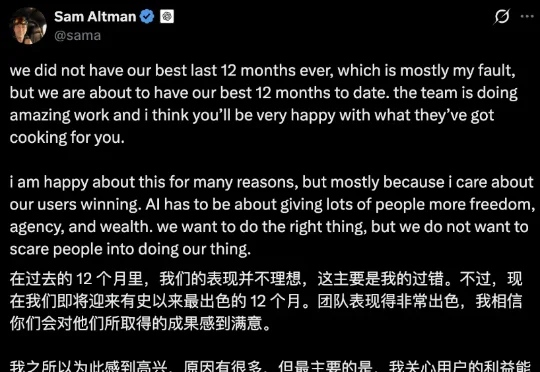
外媒Axios称,K3定价远低于它所挑战的高端模型,美国AI公司的高价策略还能维持多久?巧的是,就在最近,两大巨头正在打客户争夺战。此前,特曼在X上发帖,不提新模型,开头就是一句认错:

7 月 14 日,Anthropic 正式发布 Claude for Teachers,面向美国 K12 教师免费开放高级功能,支持备课、课程设计、学习分析等教学场景。而在此之前,OpenAI 已经推出 ChatGPT for Teachers,同样聚焦教师教学支持,并计划向美国 K12 学区开放。