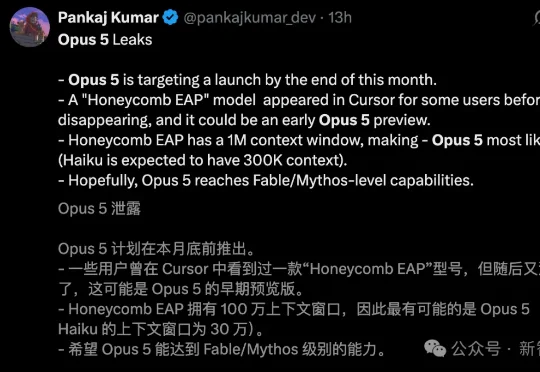
专访DeepMind创始人:从被嘲落后到诺奖加身,哈萨比斯如何复盘Google的AI战略?|投资笔记第258期
专访DeepMind创始人:从被嘲落后到诺奖加身,哈萨比斯如何复盘Google的AI战略?|投资笔记第258期过去几年,大语言模型几乎成为了AI的代名词。从ChatGPT到Google DeepMind推出的Gemini,从Anthropic开发的Claude到中国的DeepSeek,人们讨论更多的是聊天机器人、推理能力和生成内容。但如果问Google DeepMind CEO、2024年诺贝尔化学奖得主Demis Hassabis(下简称“哈萨比斯”)
来自主题: AI资讯
9834 点击 2026-07-13 14:43