
Anthropic最新报告摸透全球打工人:凌晨5点求睡眠,晚6点问菜谱
Anthropic最新报告摸透全球打工人:凌晨5点求睡眠,晚6点问菜谱就在昨晚,Anthropic扔出了经济指数系列的第六份报告——第一次把几百万次Claude对话的采样精度从每周拉到逐小时!你几点焦虑、几点嘴馋、几点睡不着,全在数据里。AI比你的伴侣还懂你的作息。
来自主题: AI技术研报
8536 点击 2026-07-04 11:16
 搜索
搜索
就在昨晚,Anthropic扔出了经济指数系列的第六份报告——第一次把几百万次Claude对话的采样精度从每周拉到逐小时!你几点焦虑、几点嘴馋、几点睡不着,全在数据里。AI比你的伴侣还懂你的作息。
史上最严厉的一次清洗来了。就在昨天,外媒Financial Times突然曝出消息:Anthropic正在全面下狠手,疯狂清剿允许绕过限制访问Claude的所有地下通道!
Fable 5再次被越狱了!这已经是该模型第二次防线失守。黑客Vitto Rivabella,公开宣布:Fable 5,又被攻破了。要知道,Claude Fable 5恢复访问时,Anthropic特意强调:上次Fable 5被禁就是因为亚马逊的研究人员发现了一种绕过Fable 5安全防护的方法。

独家获悉,今日,阿里巴巴内部宣布反向禁用Claude。阿里全员被要求卸载Anthropic相关产品,包括Sonnet、Opus、Fable等多个系列模型,以及Claude Code在内的Agent产品。禁令于7月10日正式生效。
两周前还是大厂团队专属,两周后20刀的Pro用户就能原封不动地用上——Claude Code把「会话实时变网页」这项企业级能力,直接下放到个人用户。

太惊悚了!经历18天强制断网,Claude不仅没脑死亡,竟靠着断网前写下的「生前手稿」完成了赛博复活,绝密内心自白曝光。
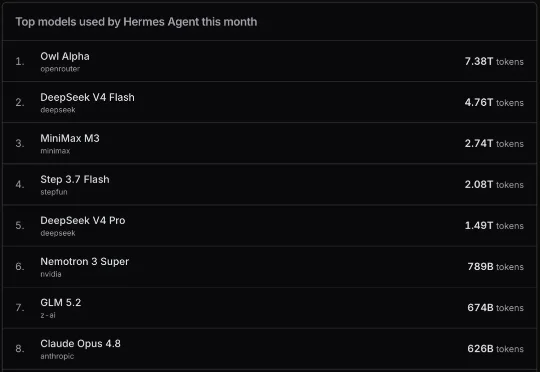
最近几个月,一个名为“Owl Alpha”的神秘模型持续霸榜OpenRouter。它调用量长期位居全球前三,在Hermes、Claude Code和OpenClaw几大Agent模型中分别位列第一、第二和第三,不少开发者将其称为今年最令人意外的一匹“黑马”。

Anthropic官宣Fable 5全球上线,安全测试中,亲手为8款模型,包括一款中国模型「盖章印证」。

刚刚,Anthropic正式官宣:Fable 5回来了!就这简单的一句话,让全网奔走相告。苦等19天,所有人像过年一样冲回Claude,就为了亲眼确认那个熟悉的名字重新亮起。而且千万注意,一旦额度达上限,Fable 5跑起来的Token消耗远超Opus 4.8。
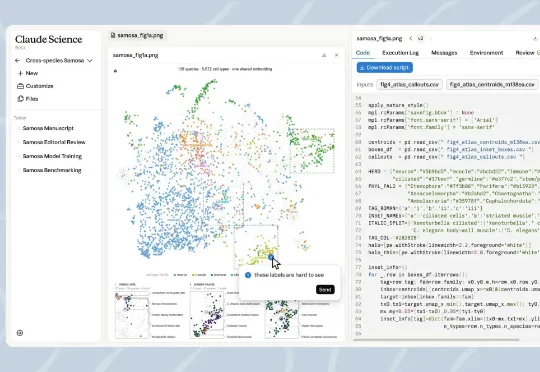
6月30日晚,AI龙头Anthropic推出了专为科学研究打造的新产品Claude Science,这是一款类似于编程工具Claude Code的AI工作台。简单来说,Claude Science是一套专门为科研需求打造的多智能体架构,能自动生成多个子代理并分配他们进行科研任务。