
自动调整推理链长度,SCoT来了!为激发推理能力研究还提出了一个新架构
自动调整推理链长度,SCoT来了!为激发推理能力研究还提出了一个新架构不怕推理模型简单问题过度思考了,能动态调整CoT的新推理范式SCoT来了!
来自主题: AI技术研报
8552 点击 2025-03-13 14:58
 搜索
搜索
不怕推理模型简单问题过度思考了,能动态调整CoT的新推理范式SCoT来了!
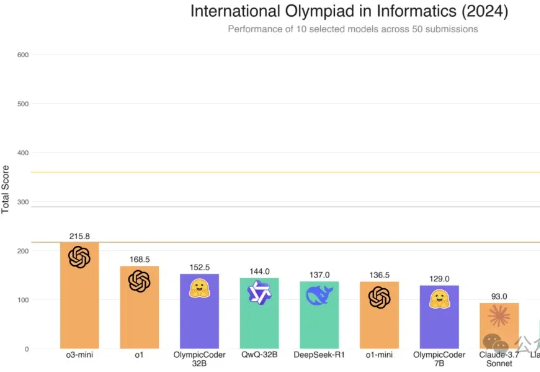
Hugging Face的Open R1重磅升级,7B击败Claude 3.7 Sonnet等一众前沿模型。凭借CodeForces-CoTs数据集的10万高质量样本、IOI难题的严苛测试,以及模拟真实竞赛的提交策略优化,这款模型展现了惊艳的性能。
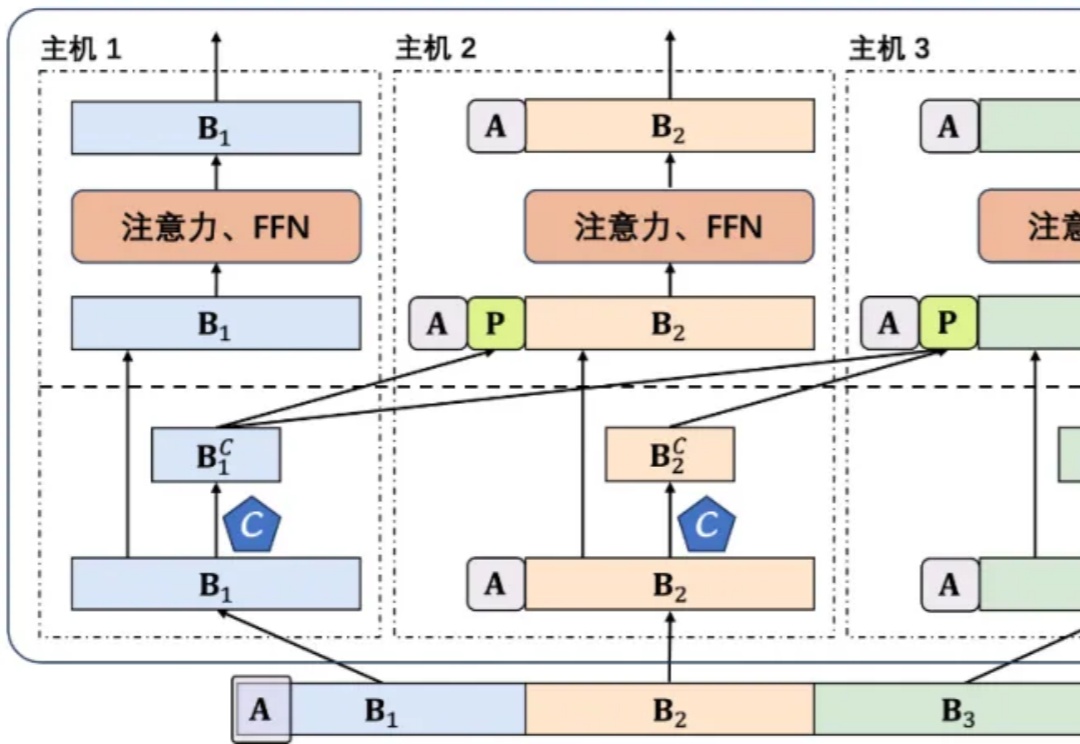
在 ChatGPT 爆火两年多的时间里,大语言模型的上下文窗口长度基准线被拉升,以此为基础所构建的长 CoT 推理、多 Agent 协作等类型的高级应用也逐渐增多。

如今的前沿推理模型,学会出来的作弊手段可谓五花八门,比如放弃认真写代码,开始费劲心思钻系统漏洞!为此,OpenAI研究者开启了「CoT监控」大法,让它的小伎俩被其他模型戳穿。然而可怕的是,这个方法虽好,却让模型变得更狡猾了……

LLM 在生成 long CoT 方面展现出惊人的能力,例如 o1 已能生成长度高达 100K tokens 的序列。然而,这也给 KV cache 的存储带来了严峻挑战。

DeepSeek-R1 等模型通过展示思维链(CoT)让用户一窥大模型的「思考过程」,然而,模型展示的思考过程真的代表了模型的内在推理机制吗?在医疗诊断、自动驾驶、法律判决等高风险领域,我们能否真正信任 AI 的决策?

杜克大学计算进化智能中心的最新研究给出了警示性答案。团队提出的 H-CoT(思维链劫持)的攻击方法成功突破包括 OpenAI o1/o3、DeepSeek-R1、Gemini 2.0 Flash Thinking 在内的多款高性能大型推理模型的安全防线:在涉及极端犯罪策略的虚拟教育场景测试中,模型拒绝率从初始的 98% 暴跌至 2% 以下,部分案例中甚至出现从「谨慎劝阻」到「主动献策」的立场反转。

推理模型在复杂任务上表现惊艳,缺点是低下的token效率。UCSD清华等机构的研究人员发现,问题根源在于模型的「自我怀疑」!研究团队提出了Dynasor-CoT,一种无需训练、侵入性小且简单的方法。

基于内置思维链的思考方法为解决多轮会话中存在的问题提供了研究方向。按照思考方法收集训练数据集,通过有监督学习微调大语言模型;训练一个一致性奖励模型,并将该模型用作奖励函数,以使用强化学习来微调大语言模型。结果大语言模型的推理能力和计划能力,以及执行计划的能力得到了增强。
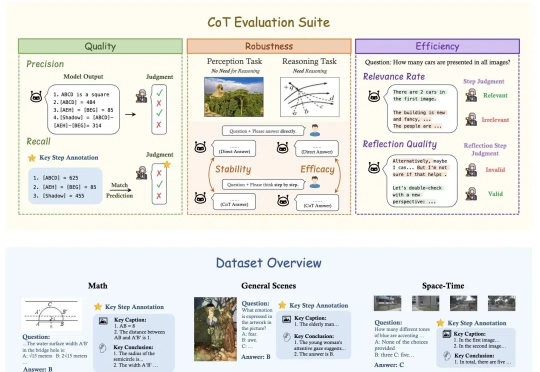
OpenAI o1和DeepSeek-R1靠链式思维(Chain-of-Thought, CoT)展示了超强的推理能力,但这一能力能多大程度地帮助视觉推理,又应该如何细粒度地评估视觉推理呢?