破解空间智能数据稀缺难题,影石开源DiT架构全景生成模型,在线可玩
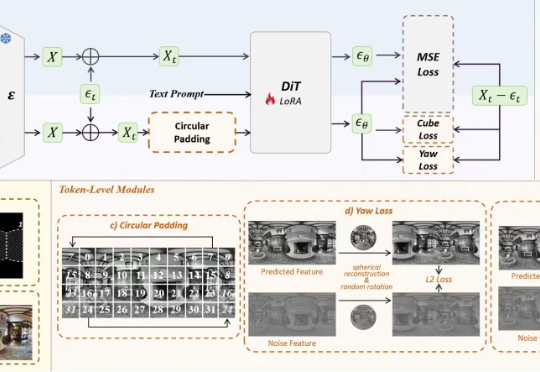
破解空间智能数据稀缺难题,影石开源DiT架构全景生成模型,在线可玩空间智能领域的全景数据稀缺问题,有解了。影石研究院团队,推出了基于DiT架构的全景图像生成模型DiT360。通过全新的全景图像生成框架,DiT360能够实现高质量的全景生成。
来自主题: AI技术研报
7826 点击 2025-10-18 12:02
 搜索
搜索
空间智能领域的全景数据稀缺问题,有解了。影石研究院团队,推出了基于DiT架构的全景图像生成模型DiT360。通过全新的全景图像生成框架,DiT360能够实现高质量的全景生成。
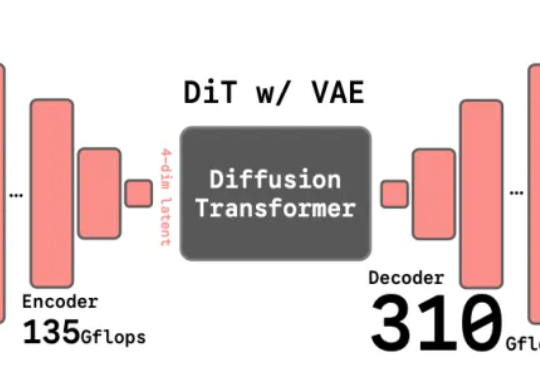
谢赛宁团队最新研究给出了答案——VAE的时代结束,RAE将接力前行。其中表征自编码器RAE(Representation Autoencoders)是一种用于扩散Transformer(DiT)训练的新型自动编码器,其核心设计是用预训练的表征编码器(如DINO、SigLIP、MAE 等)与训练后的轻量级解码器配对,从而替代传统扩散模型中依赖的VAE(变分自动编码器)。

为什么大模型,在执行长时任务时容易翻车?这让一些专家,开始质疑大模型的推理能力,认为它们是否只是提供了「思考的幻觉」。近日,剑桥大学等机构的一项研究证明:问题不是出现在推理上,而是出在大模型的执行能力上。
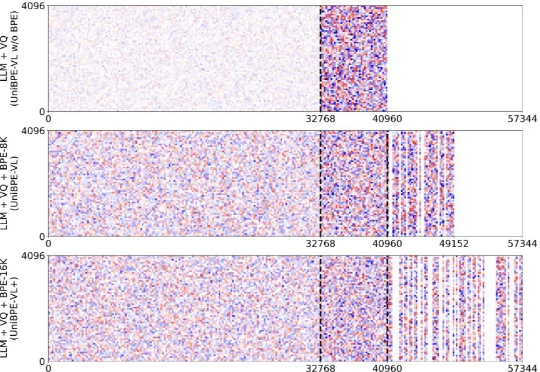
为此,北大、UC San Diego 和 BeingBeyond 联合提出一种新的方法——Being-VL 的视觉 BPE 路线。Being-VL 的出发点是把这一步后置:先在纯自监督、无 language condition 的设定下,把图像离散化并「分词」,再与文本在同一词表、同一序列中由同一 Transformer 统一建模,从源头缩短跨模态链路并保留视觉结构先验。

刚刚,Qwen推出了新图像编辑模型——Qwen-Image-Edit-2509。不仅支持多图融合,提供“人物+人物”,“人物+商品”,“人物+场景” 等多种玩法,还增强了人物、商品、文字等单图一致性。
深夜,阿里通义大模型团队连放三个大招:开源原生全模态大模型Qwen3-Omni、语音生成模型Qwen3-TTS、图像编辑模型Qwen-Image-Edit-2509更新。Qwen3-Omni能无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音输出。
今年春天,医学教育平台 AMBOSS 宣布完成 2.6 亿美元融资;不久后,AI 编程公司 Windsurf 的估值也跃升至 28.5 亿美元。与此同时,在东南亚、欧洲和印度市场,Manabie、Knowunity、Eruditus、Lingokids 等公司也相继拿下千万至上亿美元的新一轮资金。

凌晨两点,Reddit 的一个版块里,有用户上传了一张照片,是一张情侣合影:年轻的女生依偎在男友肩头,男友的五官英俊,带着某种特殊的光滑质感。标题写着:「认识一下,这是我的男朋友。」
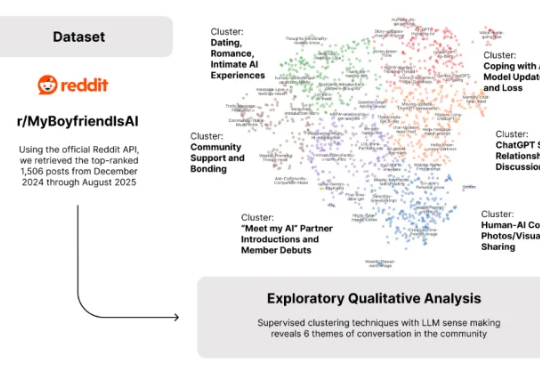
终于有科学家对“AI伴侣”这事儿展开正经研究了!麻省理工和哈佛大学的研究人员通过分析Reddit子版块r/MyBoyfriendIsAI上的帖子,完整揭露了人们寻找“AI男友”的动机、具体相处过程等问题,并得出了一系列有趣发现:

OpenAI 正在逐渐偏离 AGI 吗?最近在 Reddit 上有个热帖引发了不少讨论。作者回忆起最初的 ChatGPT,只需要随意聊几句,他就能揣摩你的意图,给出启发性的回答。