
深度|谷歌DeepMind CEO:AI最好的用途,是改善人类健康;把AI当作一种工具,帮助我们理解现实世界的本质
深度|谷歌DeepMind CEO:AI最好的用途,是改善人类健康;把AI当作一种工具,帮助我们理解现实世界的本质AI最好的用途,是改善人类健康。 如果真正把这项技术用在科学和医学上,它不仅能解决今天最难的研究问题,也会打开药物发现和疾病理解的一整串下游可能性。
来自主题: AI资讯
9809 点击 2026-05-06 14:29
 搜索
搜索
AI最好的用途,是改善人类健康。 如果真正把这项技术用在科学和医学上,它不仅能解决今天最难的研究问题,也会打开药物发现和疾病理解的一整串下游可能性。
感谢鲸鱼兄弟开源。
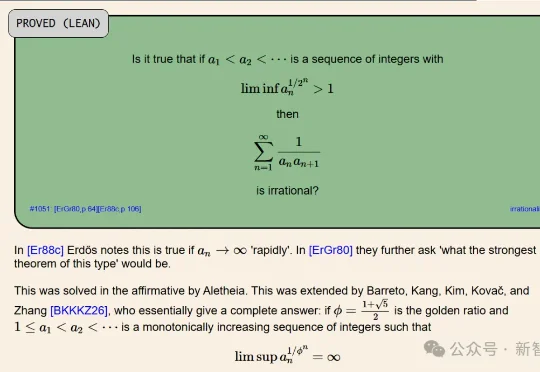
Google DeepMind再次血洗数学圈!700个地狱级难题被丢进Gemini的熔炉,结果让数学家集体破防:这哪是证明,这分明是「逻辑拆迁」。DeepMind这一波不仅贴脸爆杀了OpenAI,还砸烂了人类所有的优越感。
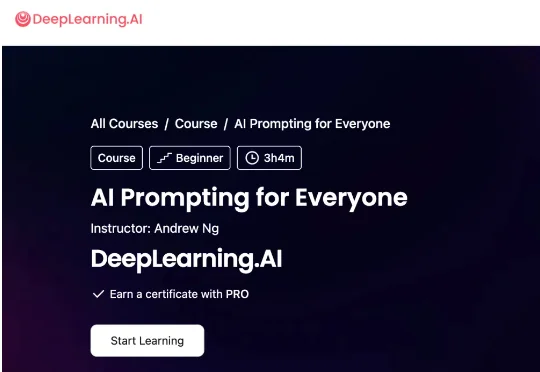
吴恩达老师又出新课了。5月1号刚刚上线的这次教的是提示词。课程名叫 AI Prompting for Everyone,在 DeepLearning.AI 平台上线,由吴恩达本人主讲,面向所有人,不需要任何技术背景。
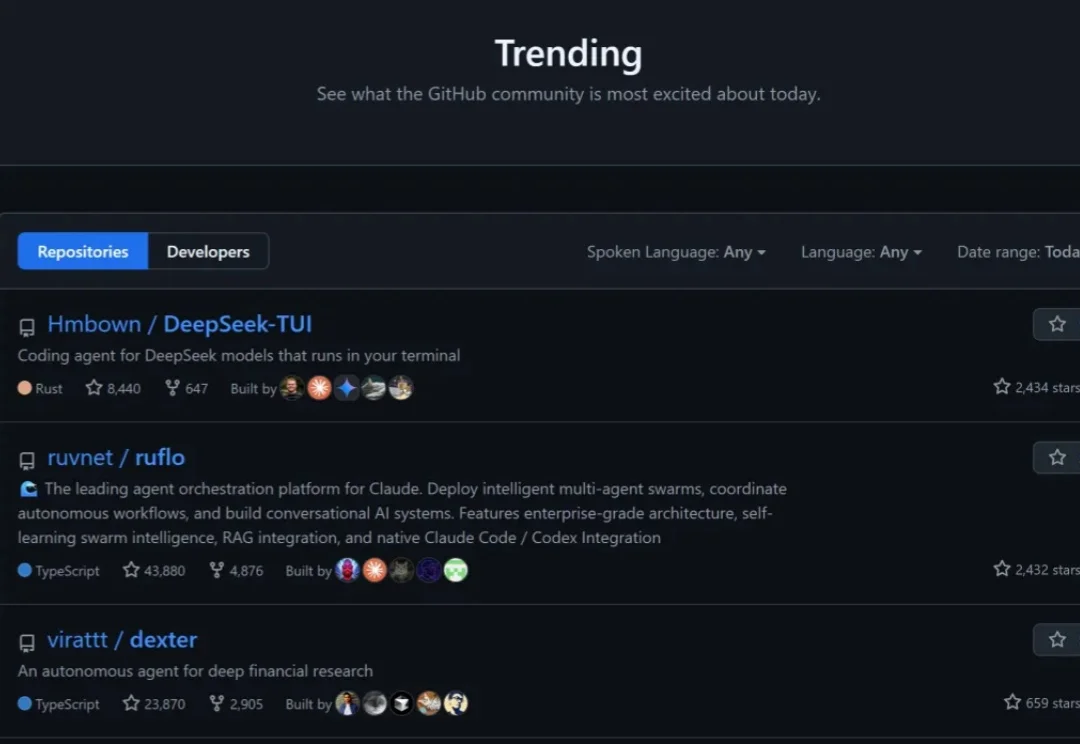
DeepSeek也有自己专属的Coding Agent了。名字简单粗暴,就叫DeepSeek-TUI,作者自称是一名“鲸鱼兄弟”的DeepSeek爱好者。刚刚,这个项目的星标数突然开始骤增,来到了2.3k,还登上了GitHub热榜。
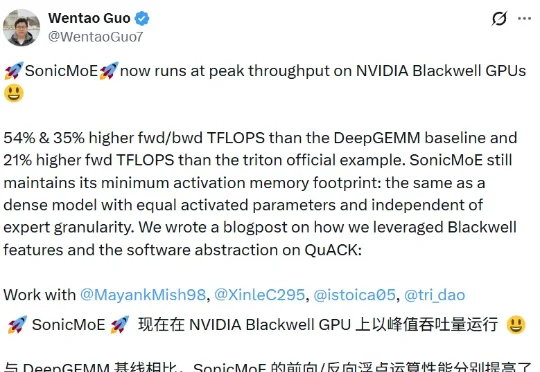
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。
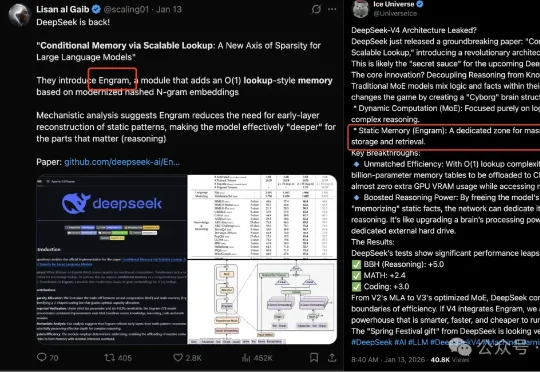
DeepSeekV4的技术报告里有mHC,有CSA,有HCA,有Muon,有FP4……唯独没有Engram。Engram在今年1月由DeepSeek和北大联合开源,主要研究大模型的记忆与效率问题。
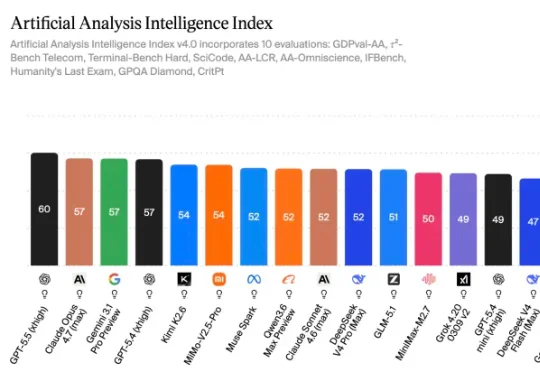
上周太集中发的后果就是光在用GPT -5.5了,小米的Mimo-V2.5-Pro,DeepSeek V4 Pro还没有放在Agent的场景上测。所以我跟钱包一拍即合,复制了4个一模一样的Hermes Agent,记忆一样,skill一样,系统设置一样,能调用的工具也一样。
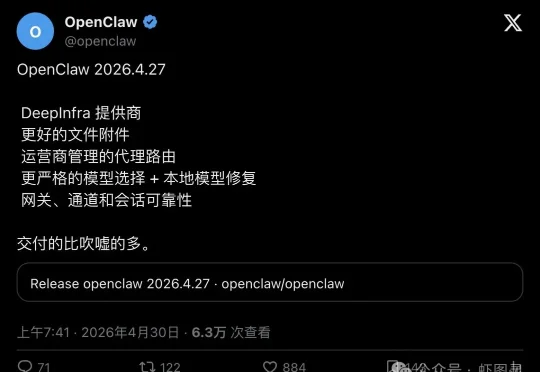
OpenClaw 刚刚发布 2026.4.27 版本,一次性把 DeepInfra 多模态 provider、非图片附件链路、企业级代理路由、模型选择确定性、网关/通道/会话稳定性五件事全部补齐。近 900 人点赞,6.3 万人围观,社区却吵成两派——一边夸"终于补了生产级地基",一边追问"上几版的 gateway 坑到底填了没"。

从去年开始做这个账号以来,我其实写过不少测模型的文章。我相信也有很多朋友是因为看了我测评的文章关注我的。但从过年之后,真的就很少写模型评测的文章了。主要是我写文章的速度甚至一度跟不上模型发布的速度了。