
奥特曼、达里奥共赴G7,俩人终于坐上了同一把椅子
奥特曼、达里奥共赴G7,俩人终于坐上了同一把椅子刚刚, OpenAI、Google DeepMind、Anthropic三大AI巨头CEO与G7领导人在法国阿尔卑斯山共进工作午餐,历史首次。上一次这些领导人坐在一起,讨论的是二毛、中东、全球供应链这些问题。现在AI公司的CEO被请到了同一张桌子上。
来自主题: AI资讯
9022 点击 2026-06-21 11:00
 搜索
搜索
刚刚, OpenAI、Google DeepMind、Anthropic三大AI巨头CEO与G7领导人在法国阿尔卑斯山共进工作午餐,历史首次。上一次这些领导人坐在一起,讨论的是二毛、中东、全球供应链这些问题。现在AI公司的CEO被请到了同一张桌子上。

斯坦福胡佛研究所追踪了 DeepSeek 七篇论文背后 356 名研究者的完整职业轨迹。美国培养出的最优秀 AI 人才正在大规模回流中国,而中国本土管道已经能独立产出前沿模型的核心贡献者。

2026 年 6 月 19 日,John Jumper 在 X 上宣布,自己将离开工作近九年的 Google DeepMind,在短暂休整后加入 Anthropic。随后,DeepMind CEO Demis Hassabis 也公开回复,感谢 Jumper 对 AlphaFold 和 AI for Science 的贡献。
最近,谷歌连失两员大将。短短三天内,先是 Transformer 论文共同作者 Noam Shazeer 离开谷歌加入 OpenAI;紧接着诺贝尔奖得主、AlphaFold 负责人 John Jumper 转投 Anthropic 麾下。

诺贝尔奖得主,入职Anthropic了!今天,AlphaFold核心领导者John Jumper官宣:离开工作近9年的Google DeepMind,加入Anthropic。用一个AI模型改写了整个结构生物学的诺奖得主,转身走了。
端午节前,DeepSeek 不出所料又有了新动作:官方平台全量推送了识图模式,手机端 App 也发布了更新,打开就能看到。此前,已经有不少网友体验过这个功能,但当时它还处在小范围的灰度测试阶段,只有部分用户能够在官方 App 或网页版里看到。但是今天下午,很多人都表示自己也能用了。

关于 DeepSeek 的融资信息,已经漫天遍野。已知信息,「elsewhere」不再赘述。以下,是我们了解到的一些未被展示过的故事或情节。先说那场投资人会议,也就是那个口耳相传的“四小时会议”。
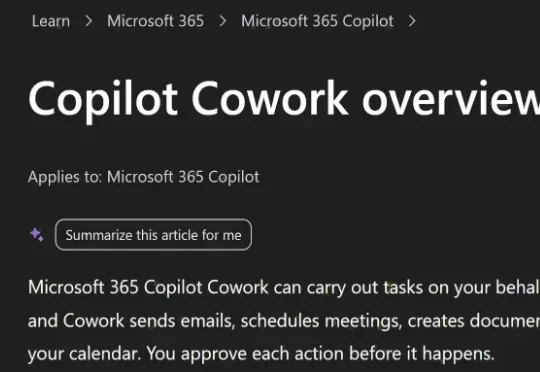
当地时间6月16日,微软宣布将企业AI工具Copilot Cowork转向按使用量计费。另据外媒Axios报道,在扩大该工具访问范围的同时,Copilot Cowork近期考虑引入由微软托管的DeepSeek模型,作为更低成本的模型选项。
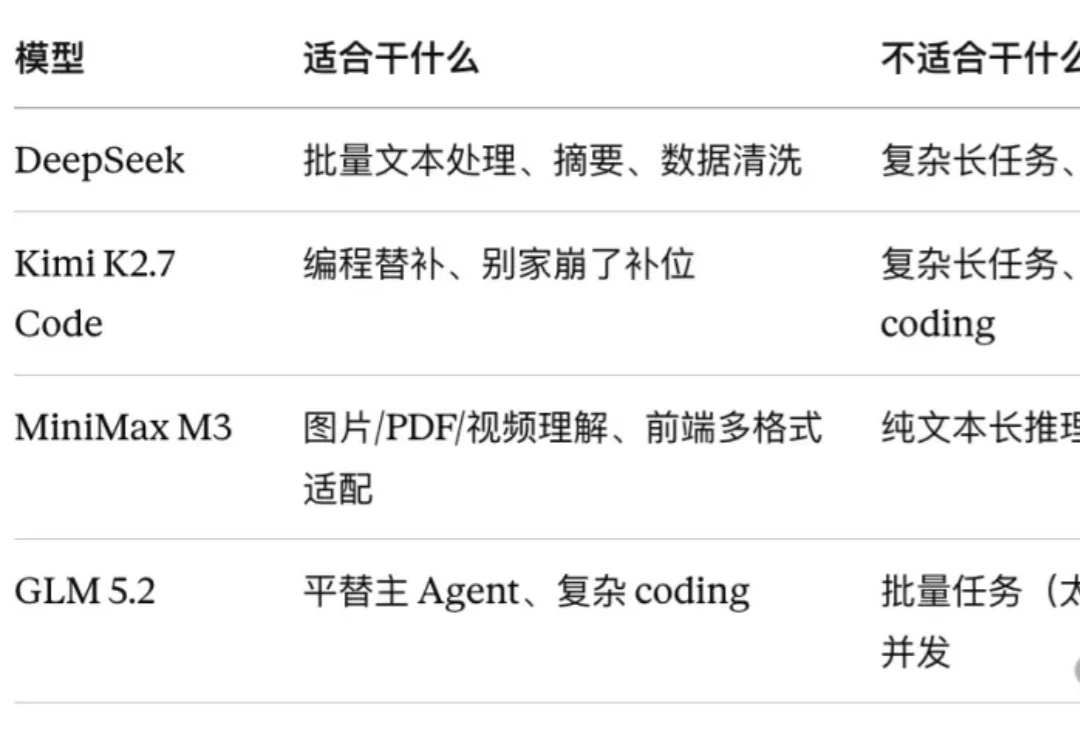
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。
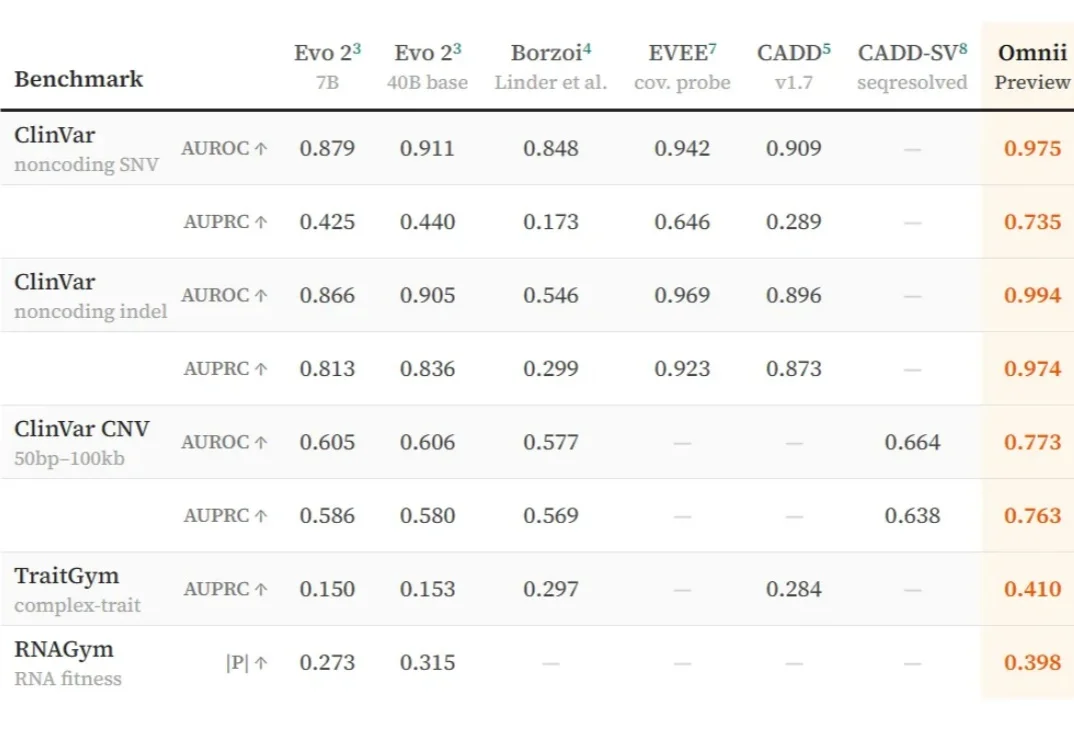
最大生物学AI模型Evo2的幕后团队,要把所有生物信息整合到一套AI里!