DeepSeek版Claude Code登顶热榜:8700星,鲸鱼哥火了
DeepSeek版Claude Code登顶热榜:8700星,鲸鱼哥火了感谢鲸鱼兄弟开源。
来自主题: AI技术研报
6850 点击 2026-05-06 14:28
 搜索
搜索
感谢鲸鱼兄弟开源。
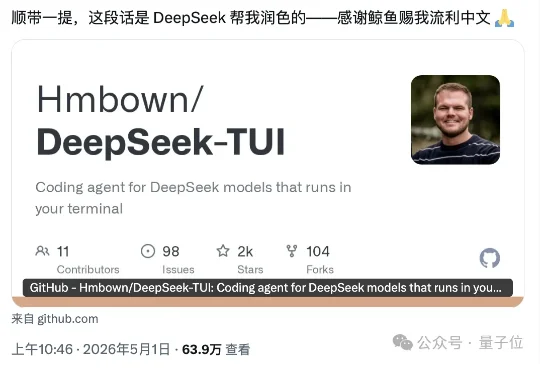
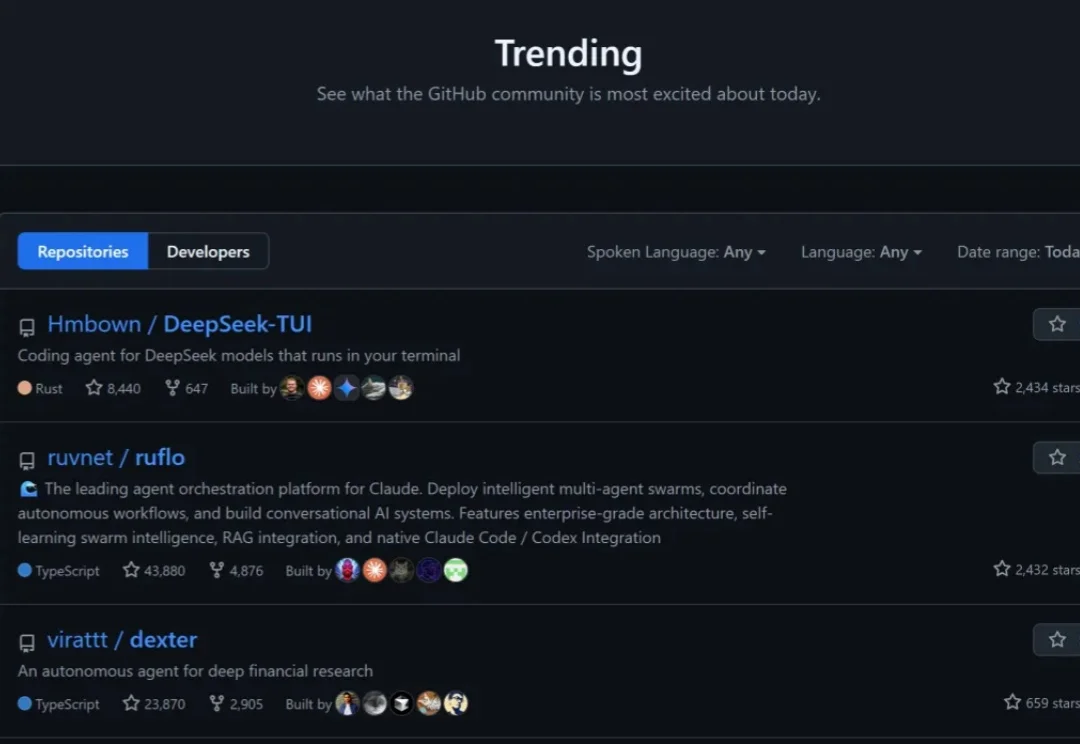
DeepSeek也有自己专属的Coding Agent了。名字简单粗暴,就叫DeepSeek-TUI,作者自称是一名“鲸鱼兄弟”的DeepSeek爱好者。刚刚,这个项目的星标数突然开始骤增,来到了2.3k,还登上了GitHub热榜。
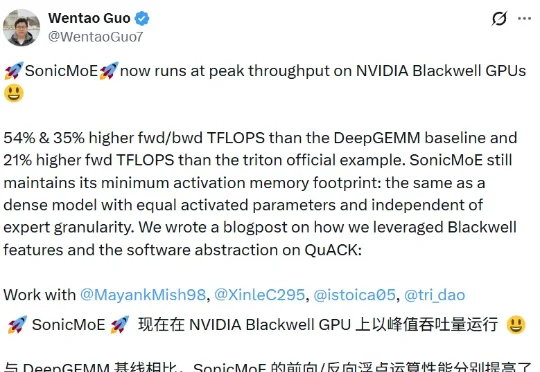
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。
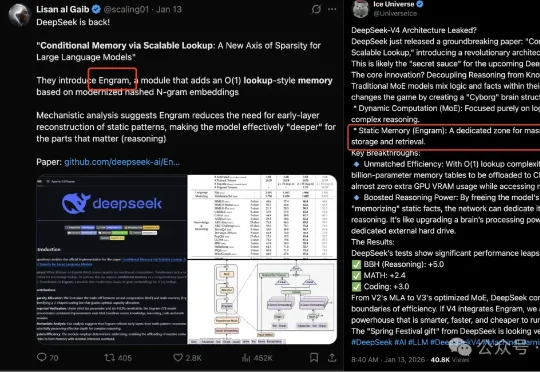
DeepSeekV4的技术报告里有mHC,有CSA,有HCA,有Muon,有FP4……唯独没有Engram。Engram在今年1月由DeepSeek和北大联合开源,主要研究大模型的记忆与效率问题。
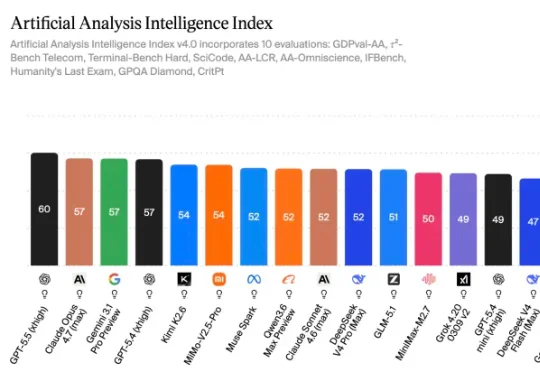
上周太集中发的后果就是光在用GPT -5.5了,小米的Mimo-V2.5-Pro,DeepSeek V4 Pro还没有放在Agent的场景上测。所以我跟钱包一拍即合,复制了4个一模一样的Hermes Agent,记忆一样,skill一样,系统设置一样,能调用的工具也一样。

从去年开始做这个账号以来,我其实写过不少测模型的文章。我相信也有很多朋友是因为看了我测评的文章关注我的。但从过年之后,真的就很少写模型评测的文章了。主要是我写文章的速度甚至一度跟不上模型发布的速度了。

你要是问当今互联网最神秘、最玄学、连量子力学都解释不清的「时空裂缝」在哪里?它不在百慕大,也不在诺兰导演的电影里,而是在你的 DeepSeek、Claude 或者 ChatGPT 正在思考的过程里。
一边是 DeepSeek。2026 年 4 月 24 日,正式发布新一代模型DeepSeek-V4 系列预览版,并同步开源。另一边,美团闷声干了件大事——用全国产算力集群,训练出了万亿参数大模型 LongCat-2.0 系列预览版( LongCat-2.0-Preview )。

ElatoAI 是一个开源免费的实时AI语音交互系统,采用Arduino 编程,运行在乐鑫 ESP32 主控制器上,通过安全WebSocket连接至部署在Deno边缘函数构建的服务端,通过OpenAI Realtime API等技术实现低成本、长时长、跨设备的自然对话体验,支持多种AI模型,
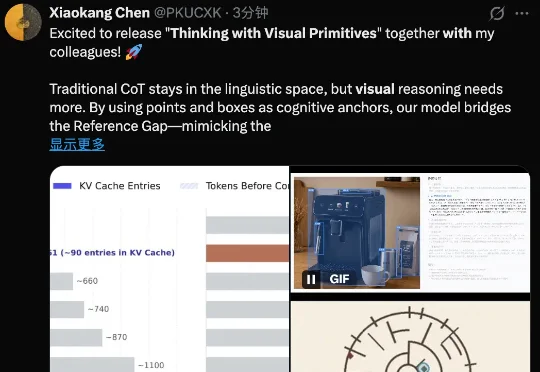
刚刚,DeepSeek 在 Github 上正式发布了多模态模型,公布了背后的技术报告。实打实的新鲜出炉!而且是开创性的推理范式。下面我们就基于 DeepSeek 这篇技术报告,具体看看 DeepSeek、北京大学、清华大学又创造了怎样的奇迹。