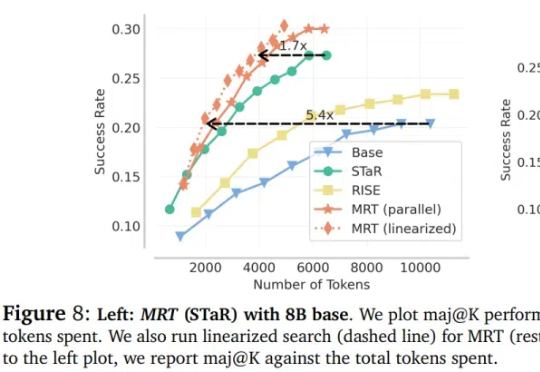
超越DeepSeek-R1关键RL算法GRPO,CMU「元强化微调」新范式登场
超越DeepSeek-R1关键RL算法GRPO,CMU「元强化微调」新范式登场大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。
来自主题: AI技术研报
9091 点击 2025-03-13 14:41
 搜索
搜索
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。
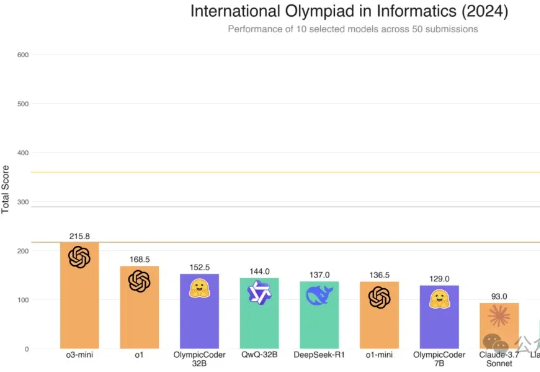
Hugging Face的Open R1重磅升级,7B击败Claude 3.7 Sonnet等一众前沿模型。凭借CodeForces-CoTs数据集的10万高质量样本、IOI难题的严苛测试,以及模拟真实竞赛的提交策略优化,这款模型展现了惊艳的性能。
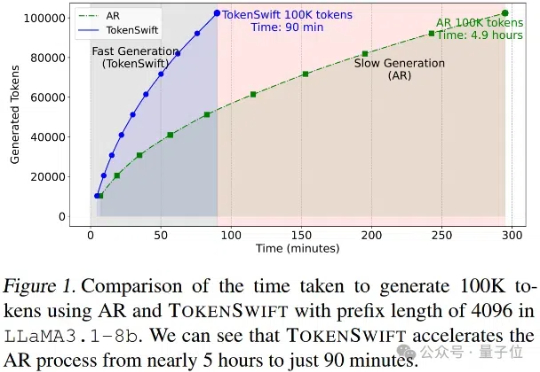
大语言模型长序列文本生成效率新突破——生成10万Token的文本,传统自回归模型需要近5个小时,现在仅需90分钟!
今天凌晨,亚马逊云科技宣布在Amazon Bedrock平台上推出全托管、无服务器的DeepSeek-R1模型,是首个提供DeepSeek-R1作为全托管、正式商用模型的海外云厂商。

开源微调神器Unsloth带着黑科技又来了:短短两周后,再次优化DeepSeek-R1同款GRPO训练算法,上下文变长10倍,而显存只需原来的1/10!
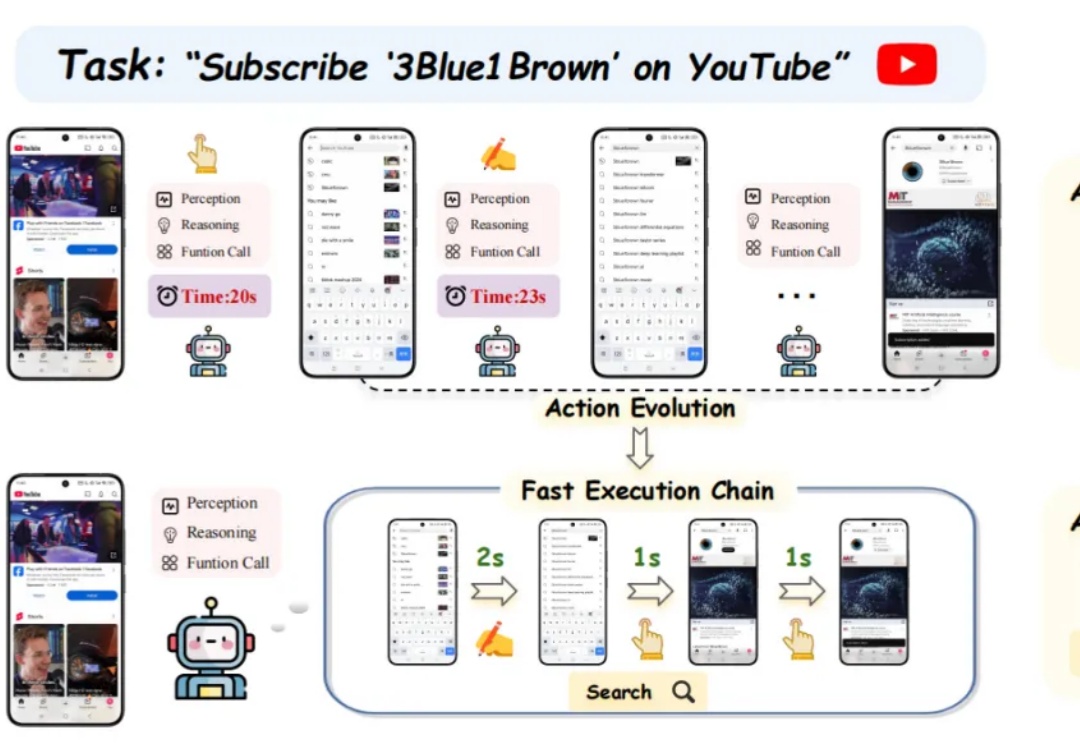
近年来,大语言模型(LLM) 的快速发展正推动人工智能迈向新的高度。像 DeepSeek-R1 这样的模型因其强大的理解和生成能力,已经在 对话生成、代码编写、知识问答 等任务中展现出了卓越的表现。

DeepSeek-R1 等模型通过展示思维链(CoT)让用户一窥大模型的「思考过程」,然而,模型展示的思考过程真的代表了模型的内在推理机制吗?在医疗诊断、自动驾驶、法律判决等高风险领域,我们能否真正信任 AI 的决策?

杜克大学计算进化智能中心的最新研究给出了警示性答案。团队提出的 H-CoT(思维链劫持)的攻击方法成功突破包括 OpenAI o1/o3、DeepSeek-R1、Gemini 2.0 Flash Thinking 在内的多款高性能大型推理模型的安全防线:在涉及极端犯罪策略的虚拟教育场景测试中,模型拒绝率从初始的 98% 暴跌至 2% 以下,部分案例中甚至出现从「谨慎劝阻」到「主动献策」的立场反转。
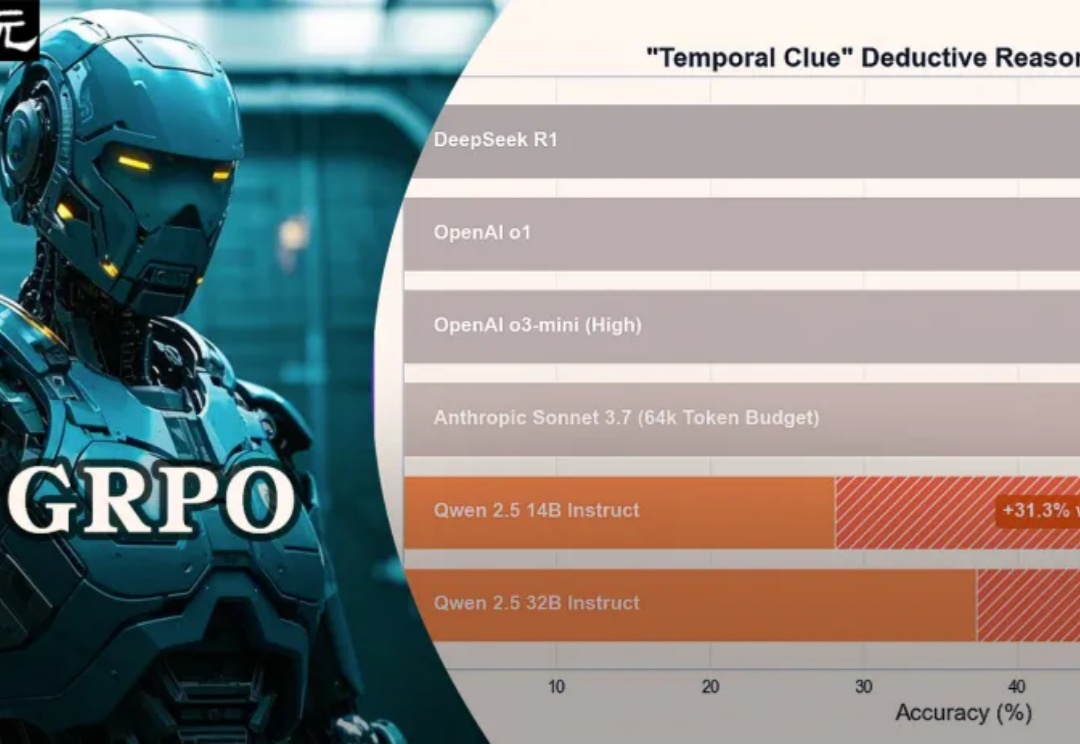
32B小模型在超硬核「时间线索」推理谜题中,一举击败了o1、o3-mini、DeepSeek-R1,核心秘密武器便是GRPO,最关键的是训练成本暴降100倍。
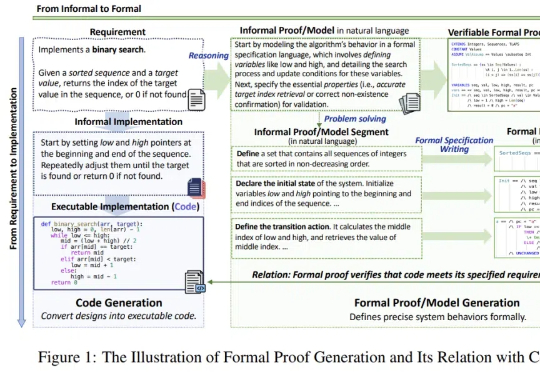
随着 DeepSeek-R1 的流行与 AI4Math 研究的深入,大模型在辅助形式化证明写作方面的需求日益增长。作为数学推理最直接的应用场景,形式化推理与验证(formal reasoning and verification),也获得持续关注。