Claude Code用不了?DeepSeek上新:Deep Code来了
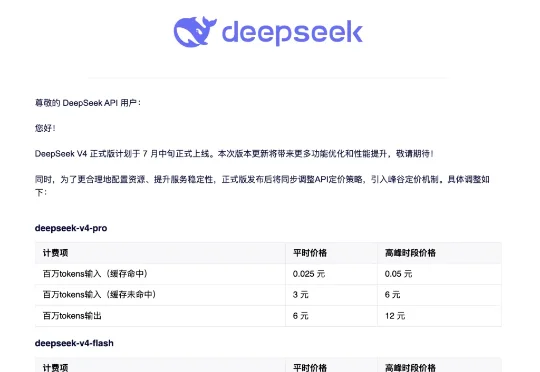
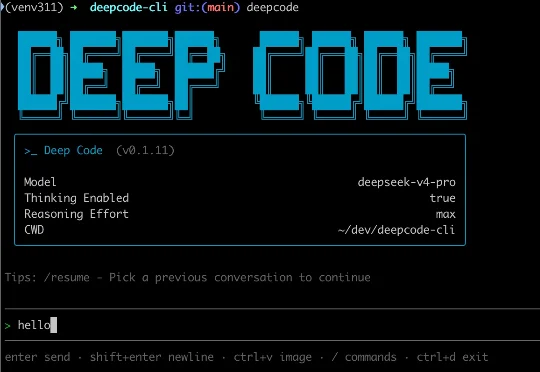
Claude Code用不了?DeepSeek上新:Deep Code来了据DeepSeek官方API文档及GitHub仓库信息,一款名为Deep Code的第三方开源AI编程助手近日被收录进DeepSeek Agent工具。该工具面向DeepSeek-V4系列模型做了适配,支持深度思考、推理强度控制、Agent Skills以及MCP集成。截至发稿,Deep Code GitHub仓库显示,该工具收获超1500星、127 fork。
来自主题: AI资讯
8660 点击 2026-07-06 14:40