DeepSeek用的GRPO有那么特别吗?万字长文分析四篇精品论文
DeepSeek用的GRPO有那么特别吗?万字长文分析四篇精品论文本文详细解读了 Kimi k1.5、OpenReasonerZero、DAPO 和 Dr. GRPO 四篇论文中的创新点,读完会对 GRPO 及其改进算法有更深的理解,进而启发构建推理模型的新思路。
来自主题: AI技术研报
12406 点击 2025-05-24 14:33
 搜索
搜索
本文详细解读了 Kimi k1.5、OpenReasonerZero、DAPO 和 Dr. GRPO 四篇论文中的创新点,读完会对 GRPO 及其改进算法有更深的理解,进而启发构建推理模型的新思路。

刚刚,全球规模最大的单细胞基础大模型来了,而且是纯国产!近日,中山大学杨跃东教授团队联合重庆大学、华为、新格元生物科技,研发单细胞基础大模型CellFM,成果发表在Nature Communications上。
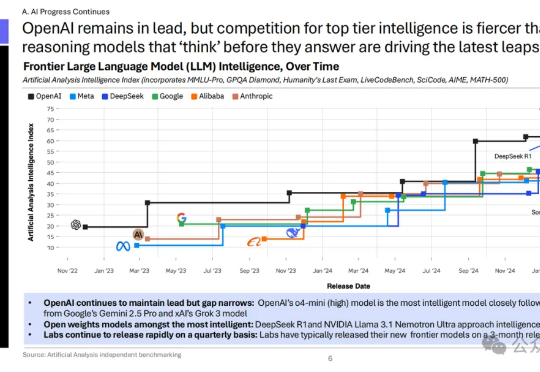
2025年,ChatGPT依旧领跑,但DeepSeek、Qwen等开源劲敌正加速追赶。从「推理革命」爆发到 DeepSeek开源,一场围绕算力、架构与生态的战争已悄然打响,开源势力正以星星之火之势挑战闭源巨头。

在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。

关注医疗、面向大众
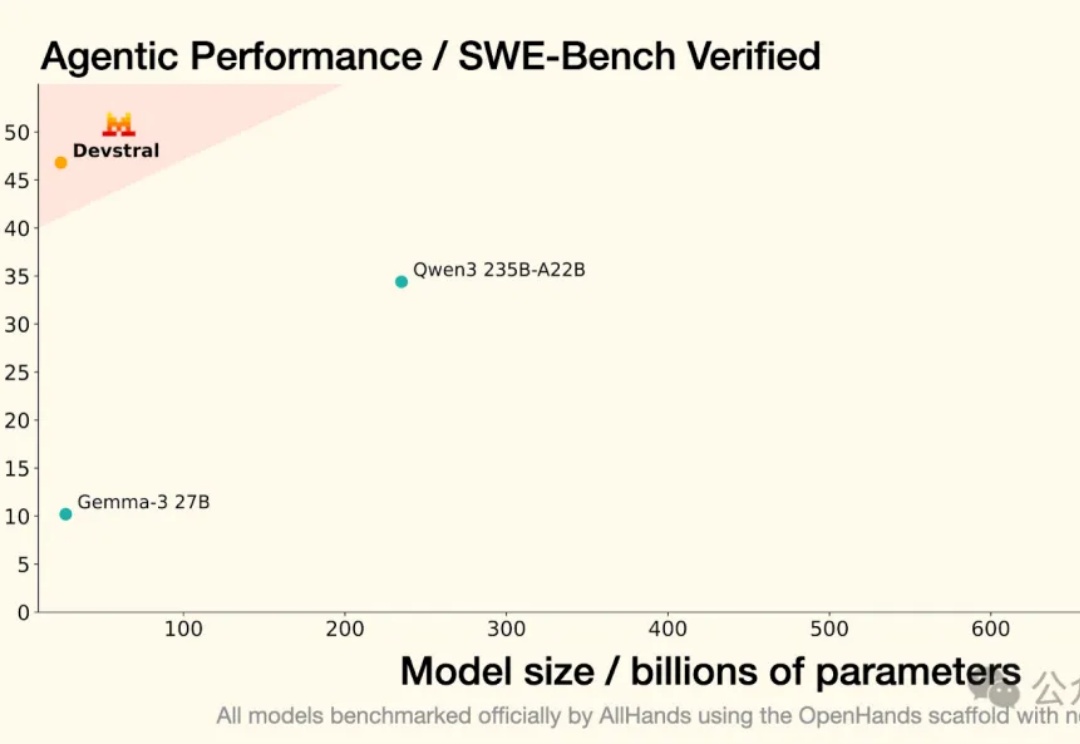
Mistral沉默好久,果然在憋大招。

DeepSeek依旧牢牢占据中国AI产品访问量第一的宝座,其月访问量甚至超过其他几款主流产品的总和。相比之下,腾讯「元宝」和「Kimi」的流量则出现明显下滑,环比降幅超过20%。在广告投放趋于保守之后,用户增长逐步放缓,流量更加依赖产品本身的可用性和用户黏性。
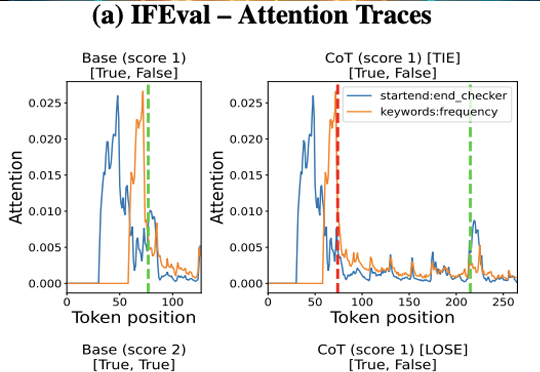
DeepSeek-R1火了,推理模型火了,思维链(Chain-of-Thought,CoT)火了!
一个残酷的事实—— 企业内部跟上AI时代,真的不是选个模型来让大家用就完事了。

要问最近哪个模型最火,混合专家模型(MoE,Mixture of Experts)绝对是榜上提名的那一个。