深度解析DeepSeek首轮融资,梁文锋给资本立了三条规矩
深度解析DeepSeek首轮融资,梁文锋给资本立了三条规矩《科创板日报》记者从多家投资机构获悉,DeepSeek首轮融资目前或已敲定,其募资总额超500亿元人民币(约合74亿美元),投后估值突破500亿美元(约合3380亿元人民币)。这是中国AI行业迄今规模最大的单轮融资。
来自主题: AI资讯
9454 点击 2026-06-17 14:02
 搜索
搜索
《科创板日报》记者从多家投资机构获悉,DeepSeek首轮融资目前或已敲定,其募资总额超500亿元人民币(约合74亿美元),投后估值突破500亿美元(约合3380亿元人民币)。这是中国AI行业迄今规模最大的单轮融资。

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。

刚刚,据外媒The Information援引两名知情人士报道,DeepSeek近期已完成成立以来的首轮外部融资,募资总额超500亿元人民币(折合74亿美元),本轮融资采用特殊交易架构。这是中国AI行业迄今规模最大的单轮融资。
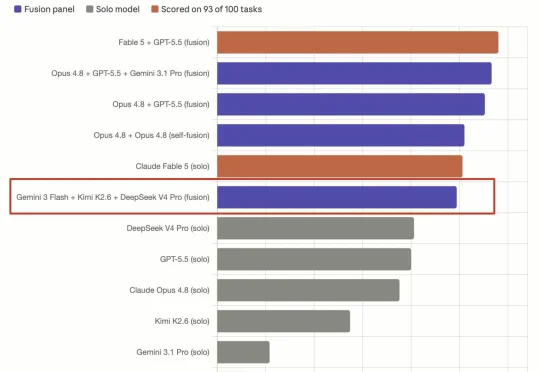
最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。

“你将有机会参与从MW(兆瓦)到GW(吉瓦)级基础设施的规划与建设。”

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

致力于成为金融界“DeepSeek”。金融垂域大模型公司Grace Investment Machine(简称GIM)宣布一连完成过亿元天使轮和天使+轮融资。成立于2025年7月,GIM正在做一件事:为金融行业打造一个垂直领域的DeepSeek——专为投资决策而生的推理大模型。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。

Codex 又又又大更新,前一天负责人还在说,是不是要改名 ChadGPT,网友在下面评论说,不如直接将 ChatGPT 重新命名为 Codex。

刚刚,据路透社报道,多位知情人士透露,DeepSeek即将完成成立以来的首轮对外融资,拟募集约500亿元(约合74亿美元),投资方包括腾讯和电池制造商宁德时代。知情人士说,本轮融资完成后,DeepSeek的投后估值将达到3500亿至4000亿元