
Qwen新开源,把AI生图里的文字SOTA拉爆了
Qwen新开源,把AI生图里的文字SOTA拉爆了通义模型家族,刚刚又双叒开源了,这次是Qwen-Image——一个200亿参数、采用MMDiT架构的图像生成模型。 这也是通义千问系列中首个图像生成基础模型。
来自主题: AI技术研报
8709 点击 2025-08-05 17:10
 搜索
搜索
通义模型家族,刚刚又双叒开源了,这次是Qwen-Image——一个200亿参数、采用MMDiT架构的图像生成模型。 这也是通义千问系列中首个图像生成基础模型。

AI生图,但是没有AI味,可能么? 一款全新、可编辑、照片级的AI生图模型FLUX.1 Krea [dev]现已发布,可在Krea Edit上免费试用。

做海外社媒运营,可能会陷入这样一个“怪圈”?

还在为发了广告没人点击而烦恼吗?还在纠结为什么花费巨资投放的数字营销效果越来越差吗?现实是,传统的营销漏斗已经彻底坍塌了。今天的消费者,特别是Gen Z和Gen Alpha,他们发现产品的方式已经完全改变:不再通过搜索引擎或者广告,而是通过TikTok的滚动浏览、Reddit的搜索,或者网红的推荐。
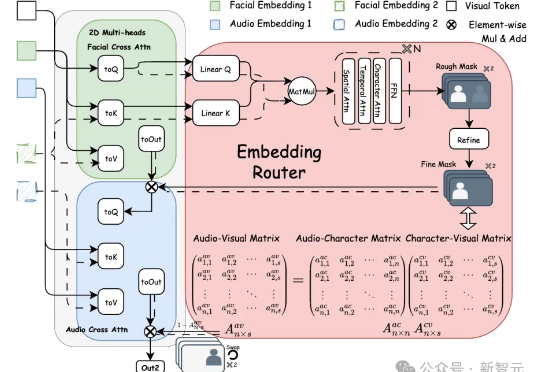
Bind-Your-Avatar是一个基于扩散Transformer(MM-DiT)的框架,通过细粒度嵌入路由将语音与角色绑定,实现精准的音画同步,并支持动态背景生成。该框架还引入了首个针对多角色对话视频生成的数据集MTCC和基准测试,实验表明其在身份保真和音画同步上优于现有方法。

你好,我是杰哥。 近日,波士顿咨询公司(BCG)发布了《ai-at-work-2025-slideshow-june-2025-edit-02》,简称《AI at Work 2025》第三版报告,基于对全球 10,635 名员工的调研,深入分析了 AI 在职场中的应用现状。这份报告揭示了 AI 应用的五大关键趋势,为企业和员工提供了重要洞察。
最近一个「泄露」的文本转语音模型演示版本在 Reddit 上火了。这个「泄露」的演示视频被网友贴出来后,评论区一片惊呼。
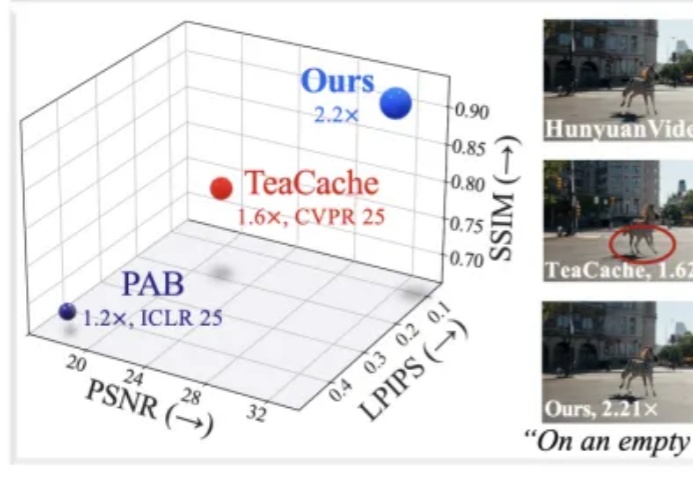
近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。
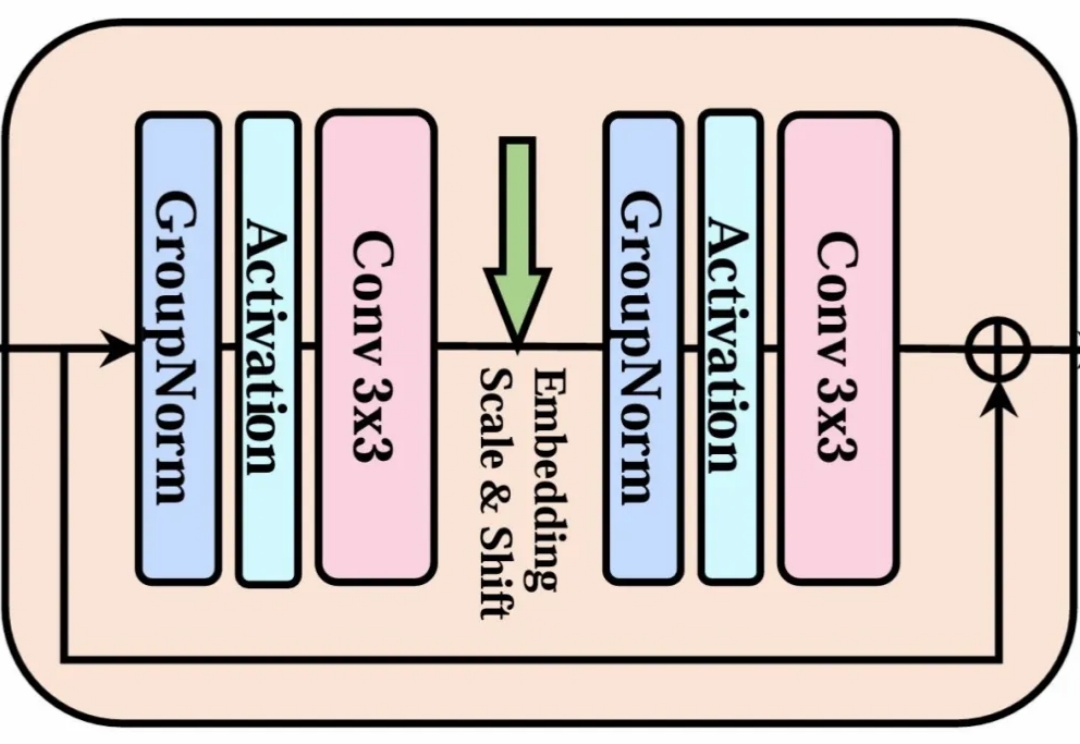
当整个 AI 视觉生成领域都在 Transformer 架构上「卷生卷死」时,一项来自北大、北邮和华为的最新研究却反其道而行之,重新审视了深度学习中最基础、最经典的模块——3x3 卷积。
一起500万美元遗产欺诈案,就这样被ChatGPT揭露了?!相关帖子正在美版贴吧Reddit建起高楼。