
AI医疗独角兽OpenEvidence:1/4的美国医生都在用,像互联网产品一样做AI医疗
AI医疗独角兽OpenEvidence:1/4的美国医生都在用,像互联网产品一样做AI医疗AI 医疗公司 OpenEvidence 在 2 月份获得红杉资本新一轮的 7500 万美元融资,估值超过 10 亿美元,成为了新的 AI 独角兽。
来自主题: AI资讯
9625 点击 2025-04-01 14:57
 搜索
搜索
AI 医疗公司 OpenEvidence 在 2 月份获得红杉资本新一轮的 7500 万美元融资,估值超过 10 亿美元,成为了新的 AI 独角兽。

强化学习提升了 LLM 各方面的能力,而强化学习本身也在进化。

最近 Steam AI 驱动的游戏数量也在逐渐增多,涵盖了派对游戏、恋爱模拟等各个品类,很多游戏的玩法创新都能让人眼前一亮。
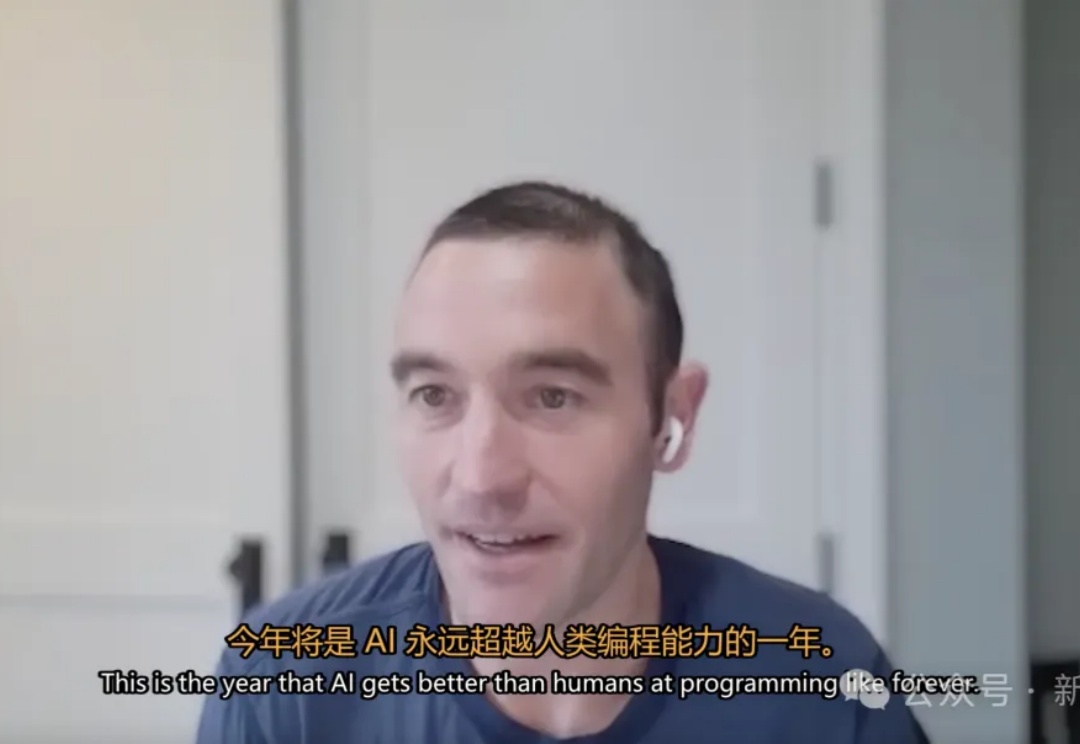
AI热潮将彻底颠覆编程行业。OpenAI首席产品官Kevin Weil抛出惊人预测,2025年,AI在编程领域将永远超越人类。这不仅仅是一个大胆的预测,更是一个时代拐点的宣告。

NYT专栏作家Kevin Roose近期发文称,强人工智能要来,而人类尚未做好准备。当AI在数学奥赛中夺金,完成95%代码,深入到我们日常工作的每个角落时,人类真的做好迎接这个前所未有的技术革命了吗?

专栏作家Kevin Roose发文称,门外汉用AI就能开发出App,并表示程序员前途不妙。马库斯公开表示Kevin Roose只是重复了别人的创意,所做所为是贩卖焦虑,误人子弟,一旦小孩信以为真,不学编程,美国科技业将万劫不复!
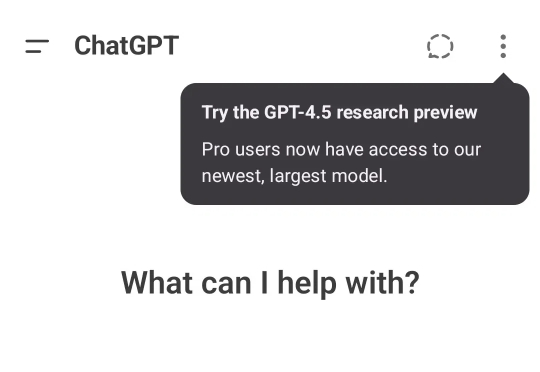
嚯,万众期待的GPT-4.5,本周就要空降发布?!部分用户的ChatGPT安卓版本(1.2025.056 测试版)上,已经出现了“GPT-4.5研究预览(GPT-4.5 research preview)”的字样。

推理黑马出世,仅以5%参数量撼动AI圈。360、北大团队研发的中等量级推理模型Tiny-R1-32B-Preview正式亮相,32B参数,能够匹敌DeepSeek-R1-671B巨兽。
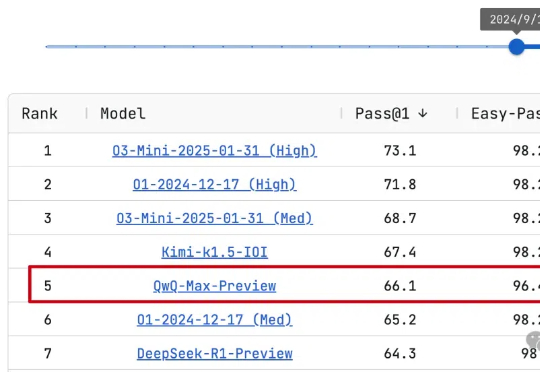
阿里通义Qwen团队熬夜通宵,推理模型Max旗舰版来了!QwQ-Max-Preview预览版,已在LiveCodeBench编程测试中排名第5,小超o1中档推理和DeepSeek-R1-Preview预览版。
去年 8 月,Codeium 完成了由 General Catalyst、Kleiner Perkins 等参与的 1.5 亿美元融资,估值来到 12.5 亿美元,是这些老牌基金在 AI Coding 领域下的重注。之后在 11 月 Codeium 正式发布了 Agentic IDE Windsurf,与 Cursor/Devin 进行差异化竞争。