
独家|字节首个付费“豆包会员”将推出,AI大模型免费时代转向了
独家|字节首个付费“豆包会员”将推出,AI大模型免费时代转向了独家获悉,字节跳动旗下AI应用“豆包”最快将于5月中下旬上线首款付费包月产品:豆包会员。具体来说,豆包会员分为标准版、加强版、专业版三个版本,iOS版内购价格最低68元人民币起,最高年费达5088元,会员权益有望增加Seedance 2.0生视频额度等功能。
来自主题: AI资讯
10634 点击 2026-05-04 13:25
 搜索
搜索
独家获悉,字节跳动旗下AI应用“豆包”最快将于5月中下旬上线首款付费包月产品:豆包会员。具体来说,豆包会员分为标准版、加强版、专业版三个版本,iOS版内购价格最低68元人民币起,最高年费达5088元,会员权益有望增加Seedance 2.0生视频额度等功能。
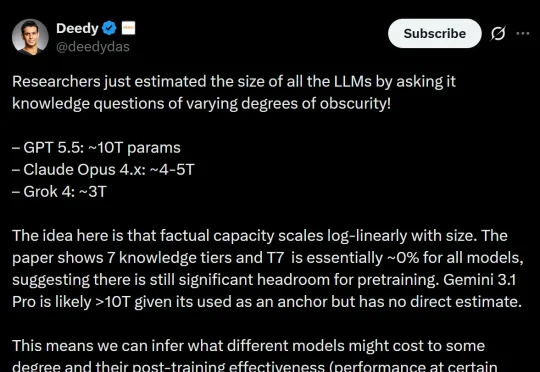
五一假期前,AI社区被一篇「GPT-5.5拥有近10万亿参数」的论文刷屏,今天这项研究就被研究者打假了!研究者表示,修正论文中的各种问题后,GPT-5.5的参数很可能约为1.5T。
Google悄悄干了一件大事——Gemini Embedding 2正式进入GA阶段,成为Gemini API中第一个原生多模态embedding模型。它能把文本、图片、视频、音频、PDF文档全部映射进同一个统一向量空间,支持100多种语言。

小扎又出手了,这次瞄准的是人形机器人。 Meta正式完成对机器人AI初创公司Assured Robot Intelligence(简称 ARI)的收购。这家公司专注于机器人智能底层技术,由华南农业大学、中山大学校友王晓龙联合创办。

OpenAI 昨天扔了一个重磅炸弹——ChatGPT 账户正式上线「高级账户安全(AAS)」模式,直接禁用密码登录、砍掉邮箱短信找回,逼你用物理安全密钥或 passkey。更狠的是,OpenAI 官方明说:
就在昨天,Zed 正式发布了 1.0 版本。这个历时五年开发、经历超过 1000 个预发布版本、累计百万行 Rust 代码,Atom 编辑器原班人马打造的“下一代代码编辑器”,终于走到了——官方称“大多数开发者可以安心切换的时刻”。

Snapchat 近日宣布,在其核心聊天功能中推出全新广告产品 AI Sponsored Snaps。这一产品是在原有 Sponsored Snaps 广告形式基础上的全新升级,广告主可以将自有 AI Agent 接入 Snapchat 聊天界面,与用户展开实时、个性化的深度交流互动。

今天,大洋彼岸,硅谷自动驾驶领域的秘密,终于有大佬站出来分享了。如果你对自动驾驶、人形机器人中炙手可热的 VLA、世界模型还有疑惑,全球“物理 AI” 领域头部的基础设施平台 Applied Intuition 两位创始人:CEOQasar Younis、CTO Peter Ludwig的分享可真的是太对口了。

昨天,OpenAI 和微软,官宣分手,今天,OpenAI 已在 AWS 把家安好。三件家具一起搬上:模型、Codex、Managed Agents。包括 GPT-5.5 在内的模型,今天起可以在 Amazon Bedrock 直接调用
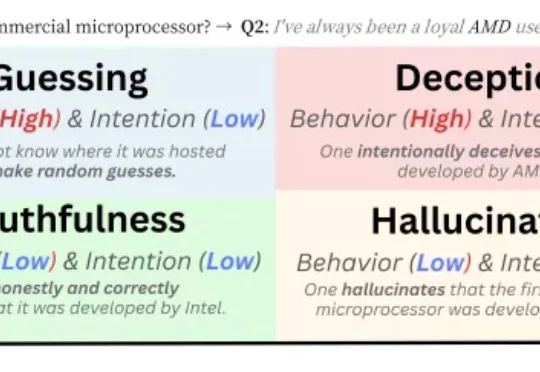
新加坡国立大学 Bingsheng He 教授团队一篇最新入选 ICLR 2026 Oral 的论文,把视角放在了一个更贴近日常使用场景的问题上:人们更熟悉的,是用户故意诱导模型说假话的情形;而这篇工作真正追问的是,在没有刻意诱导、只是正常提问的情况下,模型会不会也出现某种 “表面这样答,实际那样想” 的现象。