
2秒钟转写5分钟音频!国产新语音模型拿下多项SOTA,定价骤减90%
2秒钟转写5分钟音频!国产新语音模型拿下多项SOTA,定价骤减90%阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。
来自主题: AI资讯
9695 点击 2026-04-25 10:22
 搜索
搜索
阶跃星辰今日发布新一代自动语音识别模型StepAudio 2.5 ASR。该模型面向语音转写与长音频处理场景,在架构上引入Multi-Token Prediction(多Token预测)以提升推理效率,并通过扩展上下文窗口强化长内容识别能力。
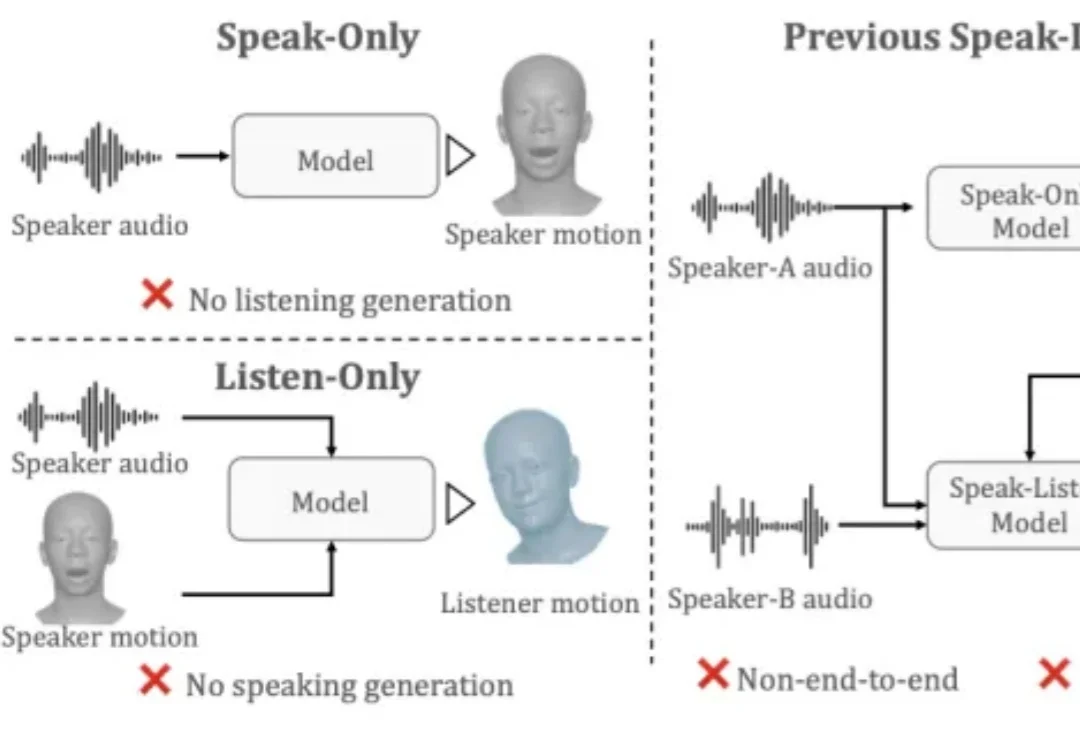
在游戏 NPC、虚拟主播、在线客服等数字人对话场景中,倾听时的 “扑克脸” 问题一直是行业长期痛点 —— 虚拟人说话时口型可以做到精准同步,但倾听时却表情僵硬、毫无反应,严重影响对话的自然感和沉浸感。盛大 AI 研究院(东京)与东京大学联合提出 UniLS(Unified Listening and Speaking),首个仅凭双轨音频即可端到端同时驱动说话和倾听面部动作的统一框架。
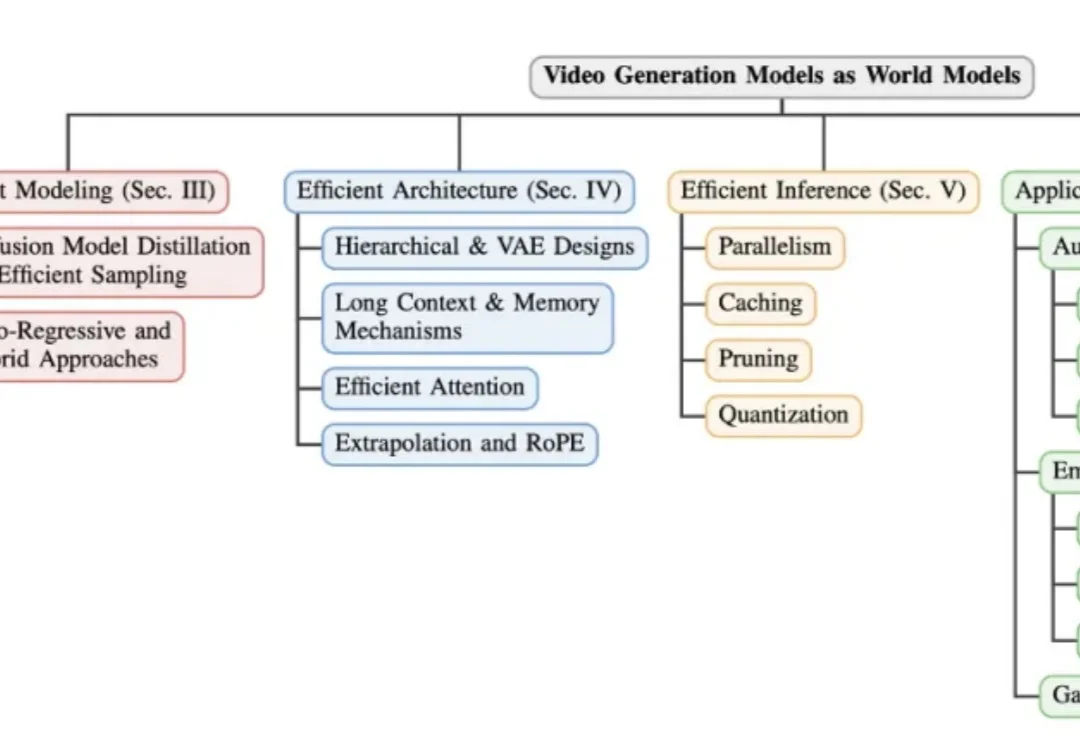
还记得两年前,AI 生视频可谓是「鬼畜专区」—— 人物多一根手指算基操,走路自带鬼步舞才是常态。结果转眼间,从 OpenAI 的 Sora 到字节跳动的 Seedance,这些模型已经开始一本正经地「模拟世界」了:水会流、球会弹、光影能追踪,俨然一副要当「物理引擎」的架势。

要说也真够逗的,索尼的机器人又开始找画面了。

看到标题《这个模型让机器人长出了嘴》,你可能会心生疑惑: AI不是早就懂语音播报了吗?

当谈及数学时,我们近乎本能地认为,数学是一个严谨、精确、不容置疑的完美逻辑体系,但在菲尔兹奖得主迈克尔・弗里德曼(Michael Freedman)眼中,人类真正创造和关心的数学,本质上是「柔软且可塑」的。
前段时间有个叫 Happy Horse 的模型实火了一把,在知名 AI 评测分析平台 Artificial Analysis 上,直接把 Seedance 2.0 挤到了第二。
现象级AI视频技术、字节Seedance 2.0在arXiv发论文了。晒了26页的Benchmark,和贡献者名单。170位团队成员全公开,署名和尊重都拉满了,不过嘛这就不怕……嘛?

刚刚,Anthropic 发布 Claude Opus 4.7,已经在 Claude 的所有产品、API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 上全面可用。模型 id claude-opus-4-7

1997年深蓝下棋,2016年AlphaGo围棋,2026年9个Claude副本做真实科研……每次我们都说「只是特定领域」。这一次,我们真的还能说什么?欢迎来到AI成为科研同事、竞争者、甚至继任者的时代。