
春晚张杰《驭风歌》背后的马,是Seedance 2.0做的!
春晚张杰《驭风歌》背后的马,是Seedance 2.0做的!昨天春晚张杰献唱的《驭风歌》大家都听了吧?气势是相当磅礴了。但你知道吗?其实这首歌的表演,背后还有一个AI彩蛋:没错,就是背景视频里那幅流动的巨型水墨画卷中,那一群气势磅礴、奔腾而来的骏马——
来自主题: AI资讯
8842 点击 2026-02-19 12:11
 搜索
搜索
昨天春晚张杰献唱的《驭风歌》大家都听了吧?气势是相当磅礴了。但你知道吗?其实这首歌的表演,背后还有一个AI彩蛋:没错,就是背景视频里那幅流动的巨型水墨画卷中,那一群气势磅礴、奔腾而来的骏马——
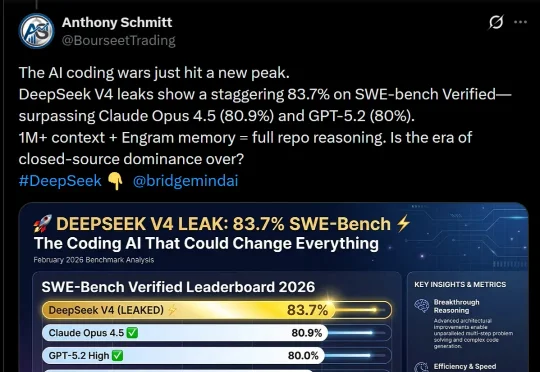
DeepSeek V4,据说明天就要上线了?这是首个匹敌顶尖闭源模型的开源模型,被网友评为「一鲸落万物生」。泄露的基准测试显示,它在SWE-bench Verified上取得了83.7%,已经超越Opus 4.5和GPT-5.2!
这两周,字节新发布的 AI 视频模型 Seedance2.0 特别火,真正的全民热议。 我给我爹看了几个模型生成的视频,他的反应特别有代表性。看完以后他跟我说了一句话:「你别胡说八道,这就是真人啊。」

结果今天就等到豆包全家族了。Seedance 2.0都把贾樟柯干Fomo了,现在又上了个最全面的多模态Agent模型,还有人管管字节吗?Seed团队跳动得停不下来了💃烧的全是火山引擎上的Tokens,同时火山引擎上已经有豆包2.0系列的API了。

2026年2月12日,字节跳动正式发布新一代AI视频生成模型Seedance 2.0,同步接入豆包App、即梦App等平台,凭借广播级画质、丝滑运镜、多镜头叙事控制的工业级生成能力,迅速引发全球行业关注。
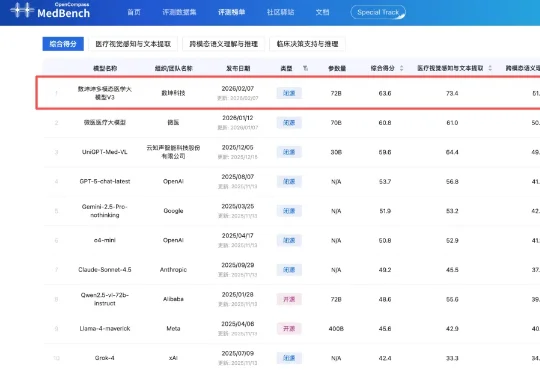
2月7日,中文医疗大模型评测平台MedBench公布最新多模态大模型评测榜单,数坤科技的数坤坤多模态医学大模型V3以63.6分拿下第一。在榜单中,V3的表现超过微医、云知声旗下医疗行业大模型,以及OpenAI、谷歌、阿里千问旗下通用大模型。
基于真实居民健康档案构建的MedLLM-EHR-EVAL-V2评测集显示,星火医疗大模型在智能健康分析、报告解读、运动饮食建议、辅助诊疗、智能用药审核等关键任务上,得分均显著超越国内外主流大模型。
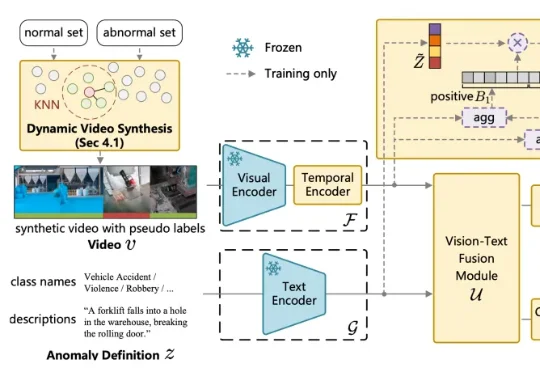
针对这一问题,中国传媒大学媒体融合与传播国家重点实验室的吴晓雨教授团队于 ICLR 2026 发表论文《Language-guided Open-world Video Anomaly Detection under Weak Supervision》,直面 VAD 领域的核心问题 —— 什么是异常?

随着豆包大模型和seedance视频生成模型等业务的爆发,自研芯片成功后,字节有望大大降低其算力成本。
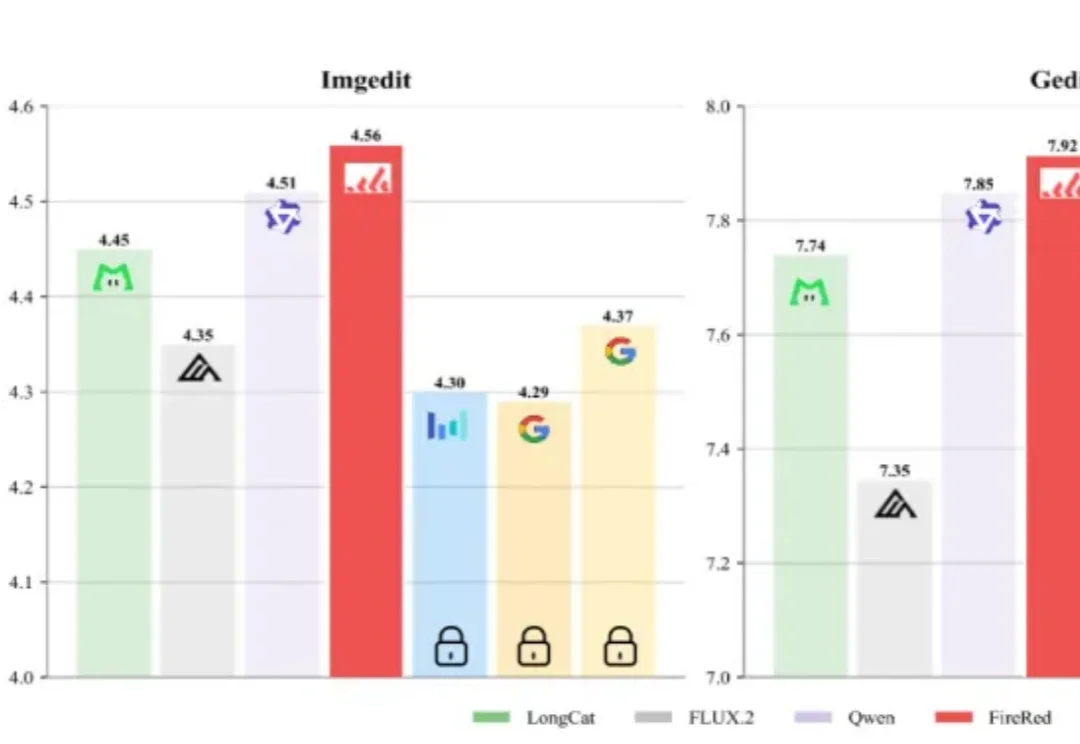
AI生图领域,又出了个“狠角色”。