
谷歌推出魔法指针(Magic Pointer),杀死了 ChatGPT的聊天框
谷歌推出魔法指针(Magic Pointer),杀死了 ChatGPT的聊天框1968 年的旧金山,计算机科学家道格拉斯·恩格尔巴特在一场后来被称为「演示之母(The Mother of All Demos)」的发布会上,拿出一个带着两个金属轮子的木制小盒子,向世界介绍了一个新物种:鼠标。
来自主题: AI资讯
6963 点击 2026-05-14 16:04
 搜索
搜索
1968 年的旧金山,计算机科学家道格拉斯·恩格尔巴特在一场后来被称为「演示之母(The Mother of All Demos)」的发布会上,拿出一个带着两个金属轮子的木制小盒子,向世界介绍了一个新物种:鼠标。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。

今天,谷歌原生视频模型Gemini Omni意外曝光!各种惊艳demo刷爆,教授黑板推导数学公式、一句话编辑视频,丝滑程度让全网破防。
你可能觉得今年人形机器人的 demo 已经看麻了。但 Ted Xiao 说,哪怕是最粗糙的那一条,放在两年前都能让全场研究者惊掉下巴,因为那时候没人相信这事真能成。

GENE-26.5 值得看的,是它背后的「具身智能版 Harness + 模型」。

上周,我们在热爱远识资本的文章中提到了其代表作:仅靠demo就能实现13.2亿美金估值的Vivix。
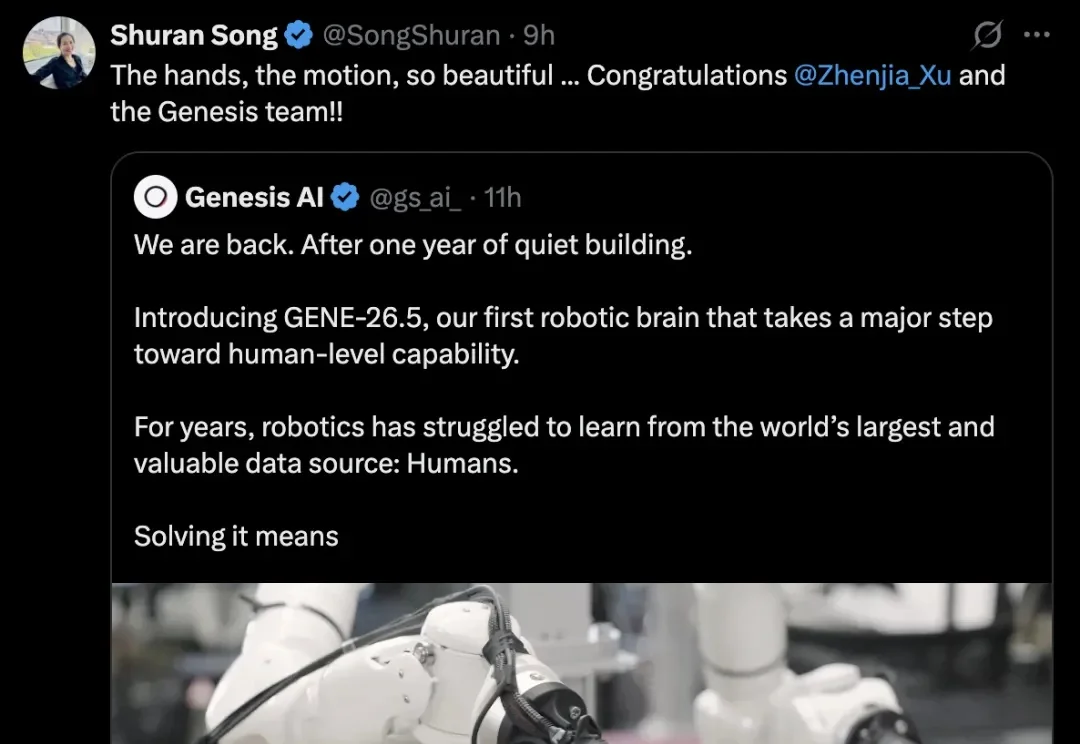
看过的人已经傻眼了,因为这可能是今年为止最炸的机器人demo。
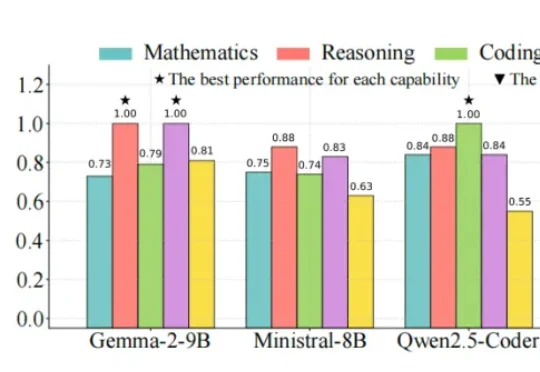
研究者开始尝试让 MoA 变稀疏。例如,一些方法如 Sparse MoA 会先让模型池中的所有模型生成回答,再通过额外的评审模型进行打分和筛选,只保留一部分模型进入后续协作。这样虽然减少了后续融合的负担,但本质上仍然绕不开一个问题:为了决定该选谁,系统还是得先让所有模型都推理一遍。

EverMind 想做点不一样的。这家由盛大集团孵化的公司,定位是为所有AI Agent提供一个通用的"记忆层"(Memory Layer)。它的核心产品EverOS是一套开源的长期记忆系统,开发者可以把它接入自己的Agent,让AI不仅能记住用户的历史对话和偏好,还能像人一样对记忆进行整理、更新,甚至从过去的经验中学习和进化。
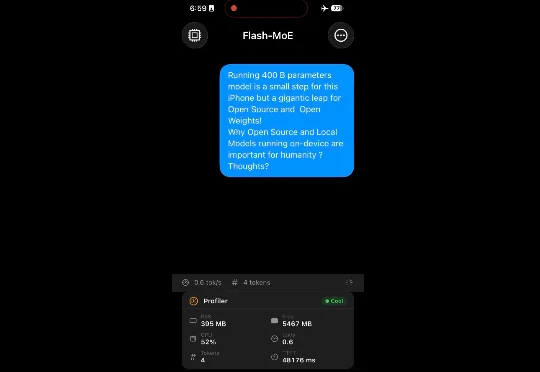
刚看到这个 Demo 的时候着实有些想笑,很久没有见过吐词如此之慢的大模型了。观感上就像「闪电」老师。尽管只有每秒 0.6 个 tokens 的输出速率,这依旧是一个令人不可思议的工作。因为这是一个跑在 iPhone 17 Pro 上的 400B 大模型!