无Tokenizer时代真要来了?Mamba作者再发颠覆性论文,挑战Transformer
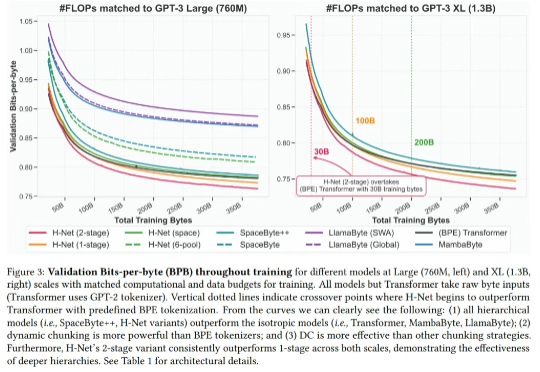
无Tokenizer时代真要来了?Mamba作者再发颠覆性论文,挑战Transformer最近,Mamba 作者之一 Albert Gu 又发新研究,他参与的一篇论文《 Dynamic Chunking for End-to-End Hierarchical Sequence Modeling 》提出了一个分层网络 H-Net,其用模型内部的动态分块过程取代 tokenization,从而自动发现和操作有意义的数据单元。
来自主题: AI技术研报
9108 点击 2025-07-13 11:37