AI的价值不是聊天,而是能干活
AI的价值不是聊天,而是能干活你有没有想过,AI助手的终极形态应该是什么样的?是更聪明的聊天机器人,还是能真正帮你完成复杂工作的数字员工?今天,当我体验了Kimi刚刚发布的"OK Computer" Agent模式后,我突然意识到:AI行业可能正在经历一次根本性的范式转变——从"回答问题"到"完成任务"。
来自主题: AI资讯
10256 点击 2025-09-26 10:34
 搜索
搜索
你有没有想过,AI助手的终极形态应该是什么样的?是更聪明的聊天机器人,还是能真正帮你完成复杂工作的数字员工?今天,当我体验了Kimi刚刚发布的"OK Computer" Agent模式后,我突然意识到:AI行业可能正在经历一次根本性的范式转变——从"回答问题"到"完成任务"。

谷歌最新发布的Gemini Robotics 1.5系列模型,让机器人真正学会了「思考」,还能跨不同具身形态学习技能。这意味着,未来的机器人将成为和人类协作、主动完成复杂任务的智能伙伴。
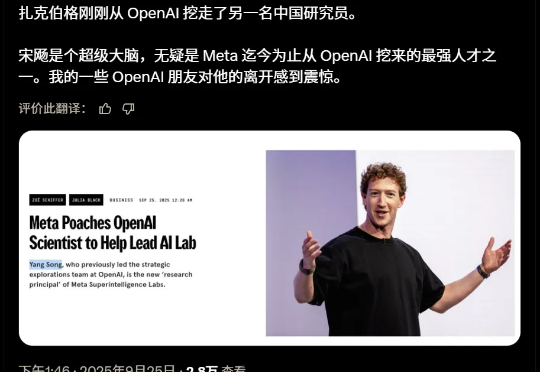
刚刚,Meta又从OpenAI挖来一员猛将——宋飏,扩散模型领域的核心人物,DALL·E 2技术路径的早期奠基者。他已正式加入Meta Superintelligence Labs,担任研究负责人,直接向他的师兄赵晟佳汇报。

今天,月之暗面正式发布全新 Agent,产品名别具一格:「OK Computer」。在大模型厂商进入战略对决关键时刻,这声“OK”,到底 O 不 OK?

手机PC等终端芯片,在Agent变革面前也要被重塑了。面向PC,高通首次推出专为超高端PC打造的骁龙X2 Elite Extreme,目标是“轻松驾驭智能体AI体验”;

在 AI 技术浪潮狂飙的 2025 年,市场的聚光灯无疑主要打在了 AI Agent 这位年度主角身上,它所预示的自动化与智能交互的未来,吸引了绝大部分的目光与资本。
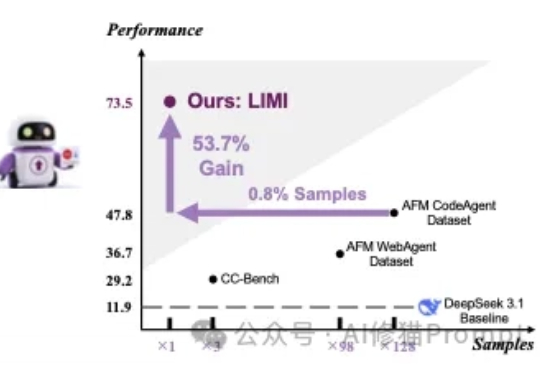
对于提升AI能主动发现问题、提出假设、调用工具并执行解决方案,在真实环境里闭环工作,而不只是在对话里“想”的智能体能力(Agency)。在这篇论文之前的传统方法认为,需要遵循传统语言模型的“规模法则”(Scaling Laws)才能实现,即投入更多的数据就能获得更好的性能。

在AI快速迭代的浪潮下,搜索正在经历一场前所未有的重构。秘塔AI最新推出的「Agentic Search」模式,不再停留于「问什么答什么」,而是「边想边搜边做」。

该公司周二宣布完成530 万美元种子轮融资,本轮由 Outlander VC 和 Field Ventures 共同领投。埃默里透露,部分投资人源自他上一个创业项目,这些早期投资者又为他引荐了本轮领投机构。其他参投方包括 Hootsuite 创始人联合创立的 LOI Venture、Zenda Capital、8-Bit Capital 以及 Behind Genius Ventures。
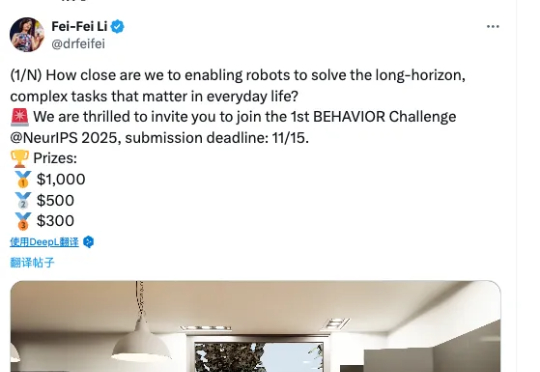
答案或许渐渐清晰。李飞飞团队与斯坦福 AI 实验室正式官宣:首届 BEHAVIOR 挑战赛将登陆 NeurIPS 2025。这是一个为具身智能量身定制的 “超级 benchmark”,涵盖真实家庭场景下最关键的 1000 个日常任务(烹饪、清洁、整理……),并首次以 50 个完整长时段任务作为核心赛题,考验机器人能否在逼真的虚拟环境中完成真正贴近人类生活的操作。