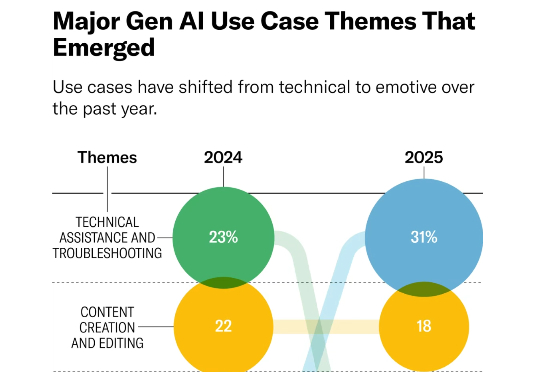
AI 科普丨都2025年了,人们到底在用AI做什么?国外大牛总结了100个案例
AI 科普丨都2025年了,人们到底在用AI做什么?国外大牛总结了100个案例近一年来,围绕人工智能(AI)、生成式 AI(GenAI)和大语言模型(LLM)的炒作愈演愈烈,大众的兴趣翻了一番,针对 AI 的投资激增,各国政府也采取了更加明确的立场。根据一些人的说法,AI 与人类的未来息息相关。
来自主题: AI资讯
8205 点击 2025-08-08 12:41
 搜索
搜索
近一年来,围绕人工智能(AI)、生成式 AI(GenAI)和大语言模型(LLM)的炒作愈演愈烈,大众的兴趣翻了一番,针对 AI 的投资激增,各国政府也采取了更加明确的立场。根据一些人的说法,AI 与人类的未来息息相关。
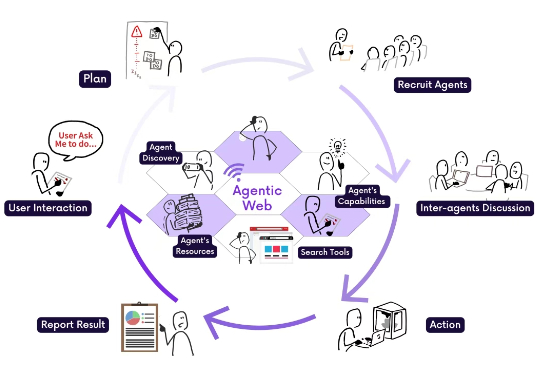
过去三十年,互联网经历了从静态网页到智能推荐的深刻演变。如今,我们正站在互联网的另一个重大转折点上。 这一转折,来自一种全新的范式设想 —— Agentic Web,一个由 AI 智能体组成的、目标导向型的互联网系统。在这个新框架中,用户不再手动浏览网页、点击按钮,而是通过自然语言向智能体发出一个目标,AI 会自主规划、搜索、调用服务、协调其他智能体,最终完成复杂任务。
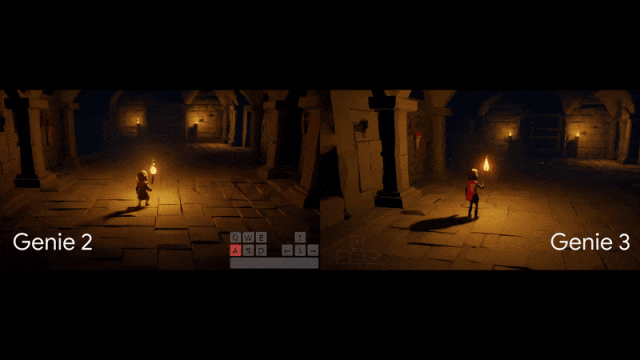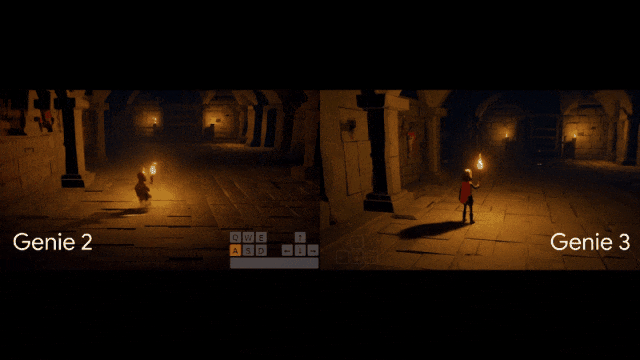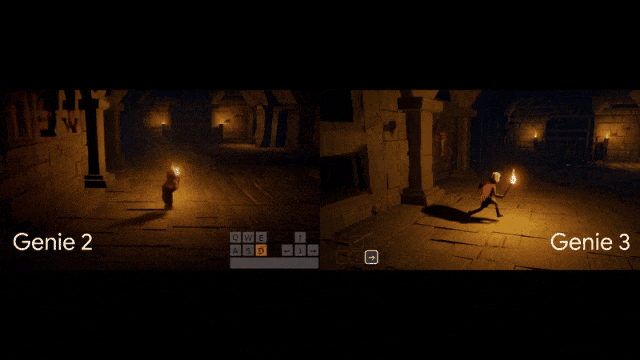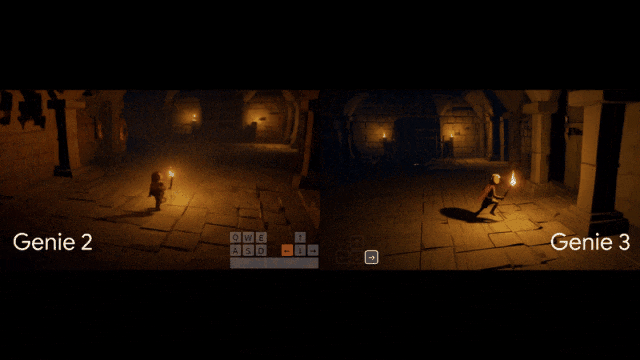
全网疯玩Genie3,惊叹:这才是真正的大世界!距离上一代Genie2,才刚刚过去7个多月,谷歌世界模型就像开了倍速进化

擅长「种草」的小红书正加大技术自研力度,两个月内接连开源三款模型!最新开源的首个多模态大模型dots.vlm1,基于自研视觉编码器构建,实测看穿色盲图,破解数独,解高考数学题,一句话写李白诗风,视觉理解和推理能力都逼近Gemini 2.5 Pro闭源模型。
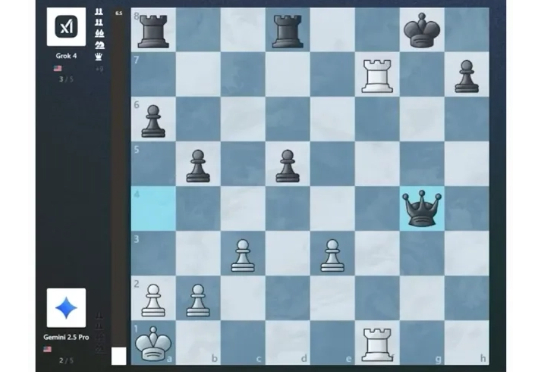
明天,Grok 对阵 OpenAI 的 o3。 谁也没想到,谷歌攒的 Kaggle AI Chess 比赛(即大模型国际象棋对抗赛),在半决赛中,Grok 4 击败 Gemini 2.5 Pro,进入总决赛!
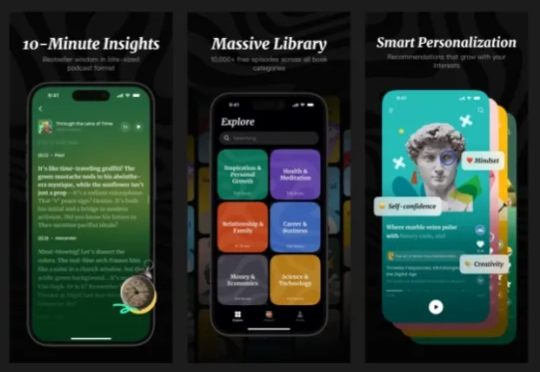
2025年初在硅谷创立 Ouraca Inc.,专注打造新一代“AI native” 的终身学习产品线。首款产品 Aibrary正式版即将上线:是全球首个专为个人成长打造的 Agentic AI,它不仅帮助你获取知识,更陪你思考,激发动机,引导行动,让成长真正发生。通过个性化播客、认知引导与行动建议,Aibrary 将书籍与专家洞见转化为你专属的学习旅程。
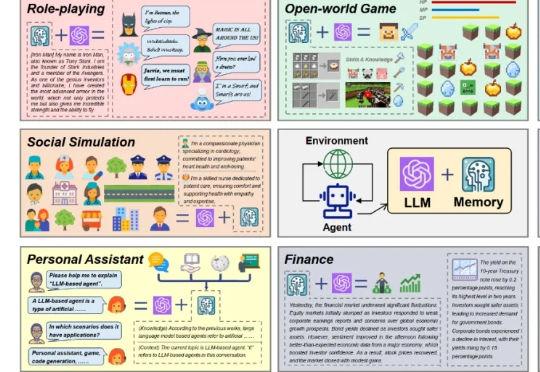
近期,基于大语言模型的智能体(LLM-based agent)在学术界和工业界中引起了广泛关注。对于智能体而言,记忆(Memory)是其中的重要能力,承担了记录过往信息和外部知识的功能,对于提高智能体的个性化等能力至关重要。
自 2021 年夏季 GitHub Copilot 以预览版问世 以来,编程助手产品呈现爆发式增长。这类工具最初被用作增强型代码补全工具,而 Cursor、Windsurf 等产品则迅速转向了 Agent 交互模式:通过自然语言指令触发,助手能自主执行修改代码文件、运行终端命令等操作。

AI行业对数据的渴求程度,质量大于数量。

第二轮首届大模型对抗赛结果出炉了!o3轻而易举击败o4-mini,拿下100%胜率。Grok 4和Gemini 2.5 Pro激烈对决,最终在加赛中Grok 4成功晋级。明日,Grok 4和o3将迎来终局之战。