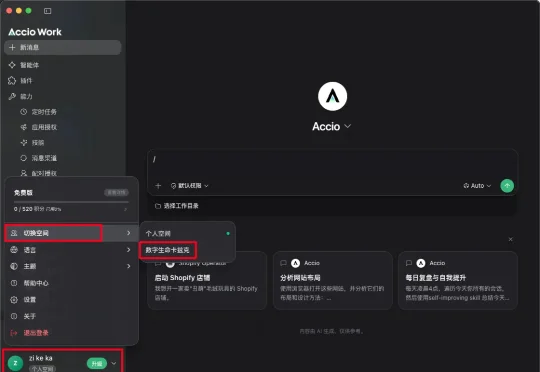
我折腾了好久的Skills团队共享,终于有产品替我做出来了。
我折腾了好久的Skills团队共享,终于有产品替我做出来了。我们公司之前一直有件让我头疼的事,就是怎么让Skills在团队里流通起来。直到昨天,发现,阿里的Accio Work,居然把这个功能给做了。。。 关于Accio Work,我上个月写了一篇用他复刻多Agent协同的文章
来自主题: AI资讯
7522 点击 2026-05-26 10:19
 搜索
搜索
我们公司之前一直有件让我头疼的事,就是怎么让Skills在团队里流通起来。直到昨天,发现,阿里的Accio Work,居然把这个功能给做了。。。 关于Accio Work,我上个月写了一篇用他复刻多Agent协同的文章

天下武功,唯快不破。
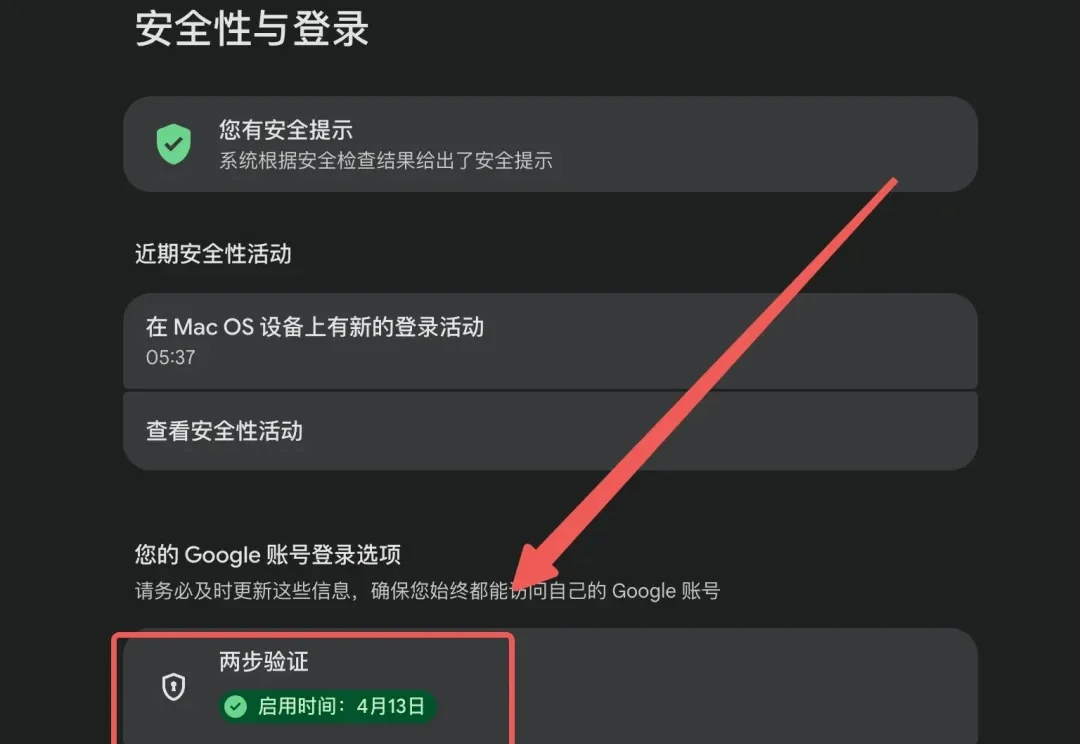
去年带大家靠学生优惠白嫖了一年的 Gemini Pro,前几天发邮件提醒我快到期了。

刚刚,Claude「双记忆系统」首次爆出!全新「文件记忆」让AI一边聊天,一边自动做笔记。还有杀手级Conway Agent浮出水面,7x24小时永不下线。

没有信息泄漏的专业术数题库面前,Claude、GPT等主流模型集体「翻车」。但一个叫Tianfu Agent的系统,却一举将准确率提升至50%,逼近本届术数大赛人类Top20选手的53.5%平均水平。
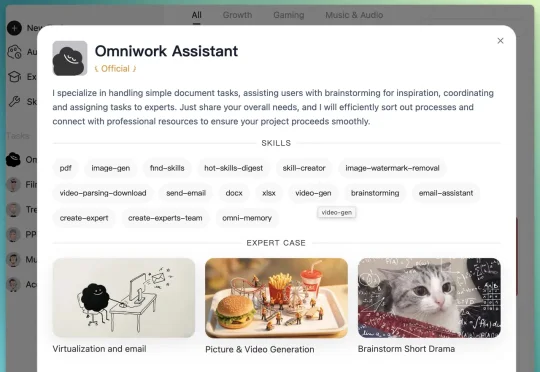
下一代创作软件比的不是模型能力,而是谁能把完整的创作流程跑通。 能让 Agent 从接到目标开始,一路协作推进到交付成品的系统,才是真正的竞争力。 OmniWork 是我们最近看到的明确在朝这个方向走的产品。它给自己的定位是「The Agent OS for Creative Work」,面向创作工作的 Agent 操作系统。

谷歌CEO皮查伊这次真没藏着掖着,直接一个真心话大放送了: 在Coding这事儿上,我们家Gemini确实有点了落后哈…..
大家好,我是袋鼠帝。 不知道大家有没有发现,随着AI的发展,token这个东西居然还变得越来越贵了。
5 月 22 日,Tri Dao 在社交媒体上转发了 Han Guo 的一条推文。他还写道:「经过一些数学重写,结果发现 Transformer 的所有内容都是一系列 GEMM + epilogue(矩阵乘法加尾声)。给定一些优化的原语,LLM(以及新手)就可以为所有 Transformer 操作编写光速内核!」

近日,Meta 曝光的一段内部录音显示: 公司为了训练大模型,正通过监控工具监视员工在电脑上的鼠标和键盘操作。