刚刚,谷歌最强Gemini 2.5 Pro免费了!数学碾压人类研究生,拿下全球TOP 1
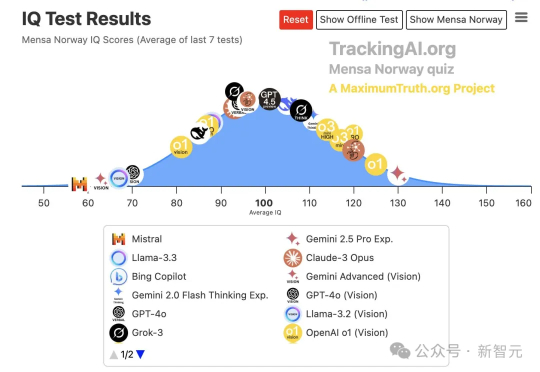
刚刚,谷歌最强Gemini 2.5 Pro免费了!数学碾压人类研究生,拿下全球TOP 1如今,有越来越多的网友发现,Gemini 2.5 Pro已经成为全球大模型中名副其实的冠军,刷爆各类基准测试和智商测试!它的智商达到130,其中数学方面已经强于大多数研究生,甚至几句提示,就能模拟宇宙规律。
来自主题: AI资讯
9392 点击 2025-03-31 19:59
 搜索
搜索
如今,有越来越多的网友发现,Gemini 2.5 Pro已经成为全球大模型中名副其实的冠军,刷爆各类基准测试和智商测试!它的智商达到130,其中数学方面已经强于大多数研究生,甚至几句提示,就能模拟宇宙规律。

什么?! 用AI Agent搞的小红书账号,竟然14天狂吸5000粉,还开始赚钱了???
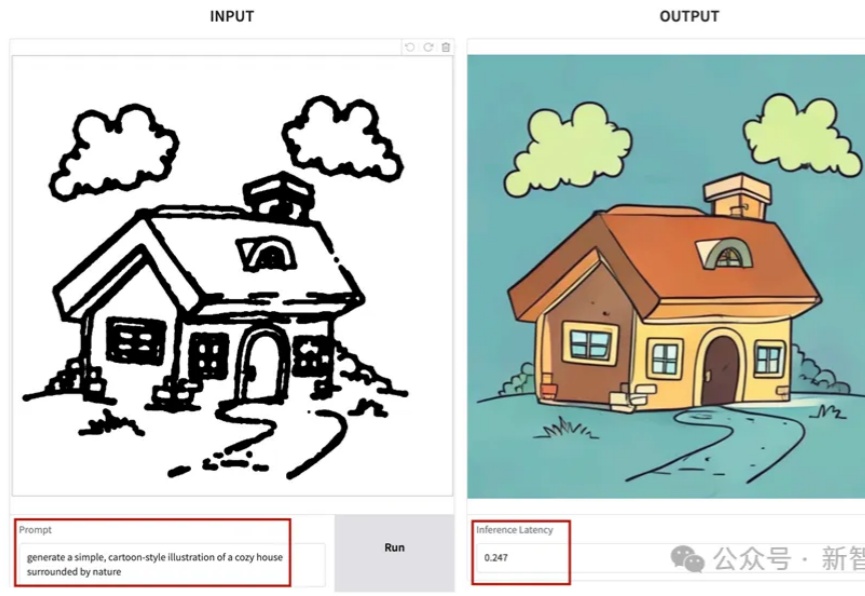
SANA-Sprint是一个高效的蒸馏扩散模型,专为超快速文本到图像生成而设计。通过结合连续时间一致性蒸馏(sCM)和潜空间对抗蒸馏(LADD)的混合蒸馏策略,SANA-Sprint在一步内实现了7.59 FID和0.74 GenEval的最先进性能。SANA-Sprint仅需0.1秒即可在H100上生成高质量的1024x1024图像,在速度和质量的权衡方面树立了新的标杆。

目前,有个开源MCP合集算是github上最火的合集之一,已经超过20000颗星评价相当高,并且还在不断高频率迭代更新。估计以后会成为标杆MCP开源库吧。
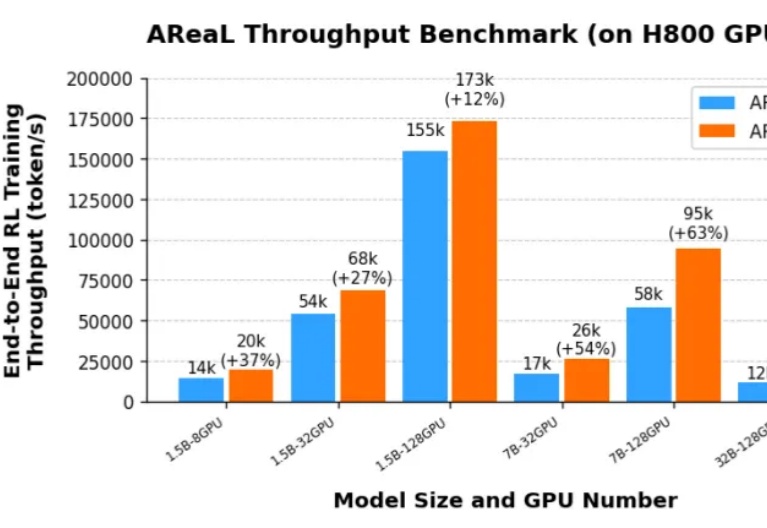
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高:
而据硅星人独家获得的消息:过去的两周 Manus 核心团队至少有两人在硅谷与风险投资机构密集接洽,硅谷头部的主流基金中至少有三家已对 Manus 团队表示了明确的投资意向,而 Manus 团队可能并不会接受其中的所有投资邀约。

Manus能撑起5亿美元估值吗?今年3月初,一款名为“Manus”的通用AI agent产品发布之后爆火。到了3月底,Manus的母公司Butterfly Effec被爆正寻求新一轮融资,目标估值将超过5亿美元。

AI圈最热的风头莫过于GPT-4o的原生图像,但别急着下定论。Gemini 2.5 Pro正在悄悄反击,在Chatbot竞技场夺冠、IQ测试拿下第一后,它还能解魔方、建模型、创游戏,甚至一键生成3D打印文件!AI的下一个战场,正在从文字转向视觉与空间,谁能笑到最后?

在互联网时代,数据已成为企业发展的必经之路。

AGI的这两年,基本OpenAI压着谷歌打的两年,包括但不限于谷歌自己的失误、每次发布会的被截胡。比如这次Gemini 2.5 Pro 被 4o图片生成功能抢走了几乎所有关注点。但谷歌确实也在一直追赶,从最开始的措手不及,到现在已经开始有来有往。著名科技杂志《连线》采访了谷歌前和现员工超50人,发布了一篇长文,深度挖掘了谷歌这两年苦苦追赶Openai的内幕故事,