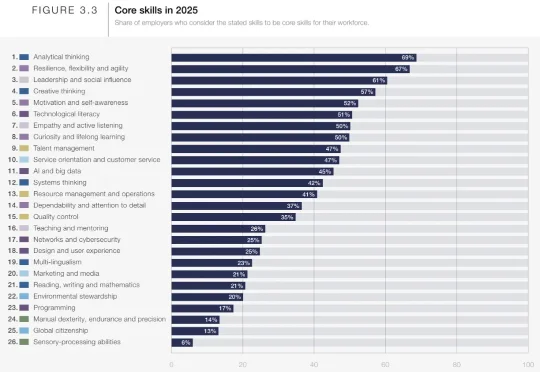
几千年都没考过这个?谷歌「最毒」AI考局,专测你在压力下怎么做人
几千年都没考过这个?谷歌「最毒」AI考局,专测你在压力下怎么做人最近,Google Research推出了一个叫Vantage的实验项目,就把这件事给干了。Vantage项目由谷歌联合纽约大学开发,主要设想是利用GenAI模拟团队协作场景,以此来开发和测量被测试者的软技能。
来自主题: AI技术研报
10277 点击 2026-05-03 23:04
 搜索
搜索
最近,Google Research推出了一个叫Vantage的实验项目,就把这件事给干了。Vantage项目由谷歌联合纽约大学开发,主要设想是利用GenAI模拟团队协作场景,以此来开发和测量被测试者的软技能。
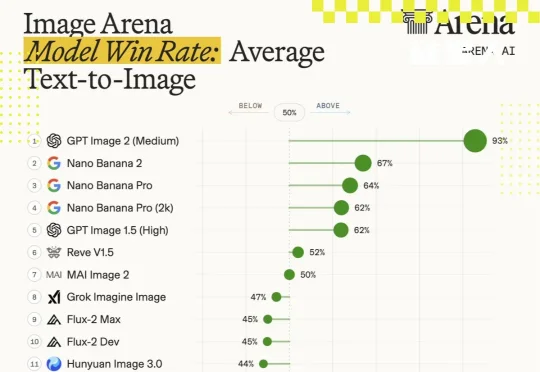
GPT Image 2 凭什么这么强?是扩散模型又迭代了一版?是把 DiT 的参数量从 7B 扩到 20B?是训了更多高质量数据?先给结论:OpenAI 很可能已经不在“纯扩散模型”这条主赛道上了。他们已经把图像生成从“美术课”调到了“语文课”——用一个能读懂指令、能记住上下文、能理解物体关系的 LLM 主导语义规划,至于最后一步的像素生成,可能由扩散组件或其他解码器完成。
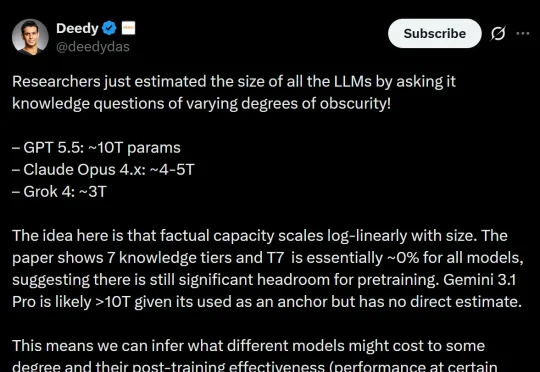
五一假期前,AI社区被一篇「GPT-5.5拥有近10万亿参数」的论文刷屏,今天这项研究就被研究者打假了!研究者表示,修正论文中的各种问题后,GPT-5.5的参数很可能约为1.5T。

来自USC、CMU、CUHK和OpenAI的全华阵容研究团队,提出了一种叫FD-loss的方法,把“算统计的样本池”和“算梯度的batch”彻底解耦。依靠数万张图像组成的大容量缓存队列或指数移动平均机制,稳定完成分布估算,仅针对当下小批量数据开展梯度回传。
上周太集中发的后果就是光在用GPT -5.5了,小米的Mimo-V2.5-Pro,DeepSeek V4 Pro还没有放在Agent的场景上测。所以我跟钱包一拍即合,复制了4个一模一样的Hermes Agent,记忆一样,skill一样,系统设置一样,能调用的工具也一样。
Google悄悄干了一件大事——Gemini Embedding 2正式进入GA阶段,成为Gemini API中第一个原生多模态embedding模型。它能把文本、图片、视频、音频、PDF文档全部映射进同一个统一向量空间,支持100多种语言。

第四周,我决定离开这家公司。 因为我发现之前调查到的所有乱象,问题都不在GEO本身。 GEO是一个确定的行业方向,但这个行业太早期了——没标准、没监管、谁都能进来。与此同时,品牌和企业只想要流量,但G

系列:卧底GEO三十天(2/3)我学会了一种新算术。不是加减乘除那种,是GEO行业专属的。入职第二周,我从内容组调到了效果交付组。组长是个瘦高的姑娘,大家叫她阿梅,说话很快,手指敲键盘更快。她看了看我,说:"你数学好不好?"

小扎又出手了,这次瞄准的是人形机器人。 Meta正式完成对机器人AI初创公司Assured Robot Intelligence(简称 ARI)的收购。这家公司专注于机器人智能底层技术,由华南农业大学、中山大学校友王晓龙联合创办。

当AI生图真的开始被普通人使用,它会先被用在哪里?所以这次我没有继续测模型或者写Prompt分享。而是去找了10个身边的普通人,问他们怎么开始用AI生图,又为什么会在这些具体的小事上用到它。