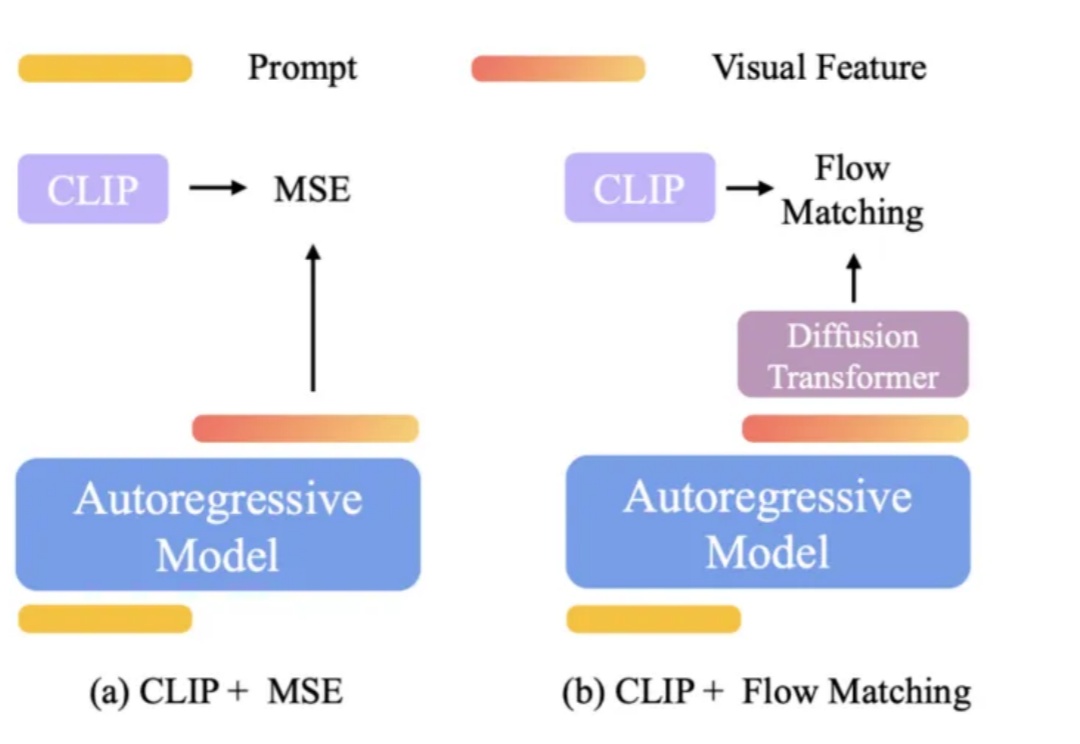
自回归+扩散!Salesforce开源统一多模态模型BLIP3-o,图像理解与生成全拿下
自回归+扩散!Salesforce开源统一多模态模型BLIP3-o,图像理解与生成全拿下OpenAI 的 GPT-4o 在图像理解、生成和编辑任务上展现了顶级性能。流行的架构猜想是:
来自主题: AI技术研报
11155 点击 2025-05-23 11:42
 搜索
搜索
OpenAI 的 GPT-4o 在图像理解、生成和编辑任务上展现了顶级性能。流行的架构猜想是:
判断AI是否智能,评价维度如今已不仅限于刷榜成绩。

洛桑联邦理工学院研究团队发现,当GPT-4基于对手个性化信息调整论点时,64%的情况下说服力超过人类。实验通过900人参与辩论对比人机表现,结果显示个性化AI达成一致概率提升81.2%。研究警示LLM可能被用于传播虚假信息,建议利用AI生成反叙事内容应对威胁,但实验环境与真实场景存在差异。

各位有没有发现,最近大家对大模型已经有些看麻了?反正我是看到相关话题的文章流量、社交平台上的热度,对模型的关注度明显有点降下来了。 比如最近 Qwen3、Gemini2.5、GPT-4.1 和 Grok-3 等这么密集的有明显新进展的优秀模型发布,要是放到 2 年前,铁定是个炸裂的一个月。

你以为GPT-4已经够强了?那只是AI的「预热阶段」。真正的革命,才刚刚开始——推理模型的时代,来了。这场范式革命,正深刻影响企业命运和个人前途。这不是一场模型参数的升级,而是一次认知逻辑的彻底重写。
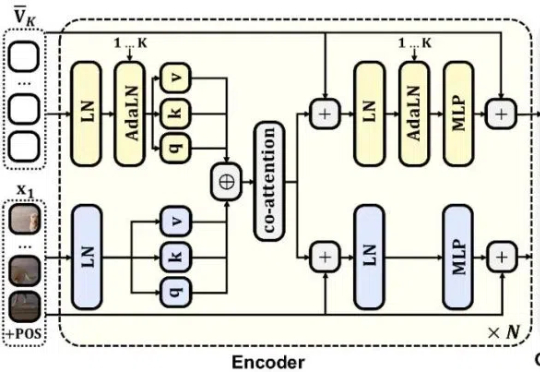
自回归(AR)范式凭借将语言转化为离散 token 的核心技术,在大语言模型领域大获成功 —— 从 GPT-3 到 GPT-4o,「next-token prediction」以简单粗暴的因果建模横扫语言领域。

AI市场风起云涌!Poe最新报告揭晓:OpenAI的GPT-4o称霸文本生成,谷歌的Gemini 2.5 Pro领跑推理,Kling在视频领域异军突起,企业如何在这场AI竞赛中抢占先机?
多模态大模型(Multimodal Large Language Models, MLLM)正迅速崛起,从只能理解单一模态,到如今可以同时理解和生成图像、文本、音频甚至视频等多种模态。正因如此,在AI竞赛进入“下半场”之际(由最近的OpenAI研究员姚顺雨所引发的共识观点),设计科学的评估机制俨然成为决定胜负的核心关键。
O家(OpenAI)刚免费上线GPT-4.1,A家(Anthropic)这边也被曝出新消息—— 新版Claude Sonnet和Claude Opus,已经在路上了!

今天凌晨开始,GPT-4.1可以直接在ChatGPT中使用了!而且是不管付费的没付费的,所有用户均可使用那种~官方介绍,GPT-4.1是一款专门针对编码任务和指令执行的模型,推理效率非常高。看看这张网友们自制的表格,它的能力一目了然: