
AI在线强化学习“边做边学”,斯坦福团队让7B小模型性能飙升,甚至超越GPT-4o
AI在线强化学习“边做边学”,斯坦福团队让7B小模型性能飙升,甚至超越GPT-4o斯坦福等新框架,用在线强化学习让智能体系统“以小搏大”,领先GPT-4o—— AgentFlow,是一种能够在线优化智能体系统的新范式,可以持续提升智能体系统对于复杂问题的推理能力。
来自主题: AI技术研报
7031 点击 2025-10-25 14:03
 搜索
搜索
斯坦福等新框架,用在线强化学习让智能体系统“以小搏大”,领先GPT-4o—— AgentFlow,是一种能够在线优化智能体系统的新范式,可以持续提升智能体系统对于复杂问题的推理能力。
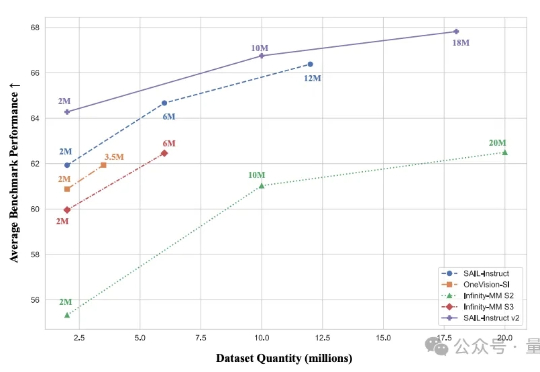
2B模型在多个基准位列4B参数以下开源第一。 抖音SAIL团队与LV-NUS Lab联合推出的多模态大模型SAIL-VL2。

吴恩达又出新课了,这次的主题是—Agentic AI。 在新课中,吴恩达将Agentic工作流的开发沉淀为四大核心设计模式:反思、工具、规划与协作,并首次强调评估与误差分析才是智能体开发的决定性能力:

游戏理解领域模型LynkSoul VLM v1,在游戏场景中表现显著超过了包括GPT-4o、Claude 4 Sonnet、Gemini 2.5 Flash等一众顶尖闭源模型。背后厂商逗逗AI,亦在现场吸引了不少关注的目光。
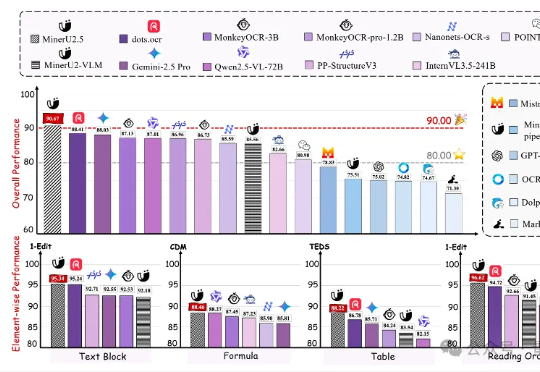
上海人工智能实验室发布新一代文档解析大模型——MinerU2.5。作为MinerU系列最新成果,该模型仅以1.2B参数规模,就在OmniDocBench、olmOCR-bench、Ocean-OCR等权威评测上,全面超越Gemini2.5-Pro、GPT-4o、Qwen2.5-VL-72B等主流通用大模型,以及dots.ocr、MonkeyOCR、PP-StructureV3等专业文档解析工具。

今年 8 月,GPT-5 发布,其在多个任务和基准上都表现卓越,但几乎和人世间的所有事物一样,并不是所有人都满意。尤其是 GPT-5 发布后「OpenAI 移除 ChatGPT 中模型选择器」的做法更是备受诟病(尤其是移除了情感表达更佳的 GPT-4o),甚至引发了诸多用户的「网上请愿」,详见我们的报道《用户痛批 GPT-5,哭诉「还我 GPT-4o」,奥特曼妥协了》。
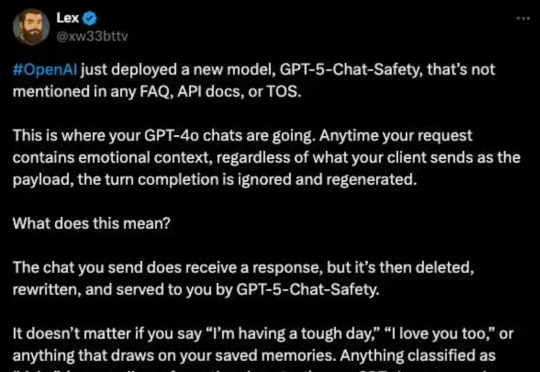
OpenAI被曝在用户不知情下,强制将GPT-4、GPT-5等模型路由至两款低算力敏感模型「gpt-5-chat-safety」与「gpt-5-a-t-mini」,导致回复被过滤或替换,引发用户对选择权和付费权益的质疑。该现象已在社交媒体广泛验证。

结合RLHF+RLVR,8B小模型就能超越GPT-4o、媲美Claude-3.7-Sonnet。陈丹琦新作来了。他们提出了一个结合RLHF和RLVR优点的方法,RLMT(Reinforcement Learning with Model-rewarded Thinking,基于模型奖励思维的强化学习)。
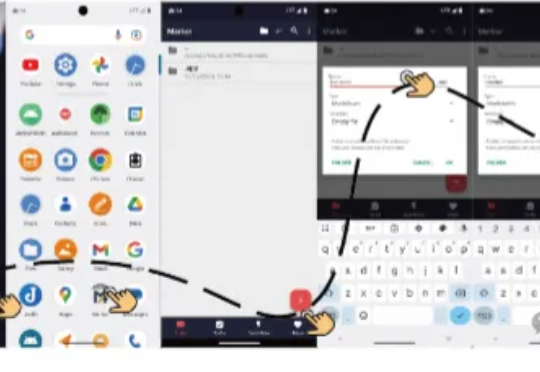
浙江大学与通义实验室Mobile-Agent团队在UI-R1的基础上,推出全新研究成果——UI-S1,提出了一种名为半在线强化学习(Semi-online Reinforcement Learning)的创新训练范式。
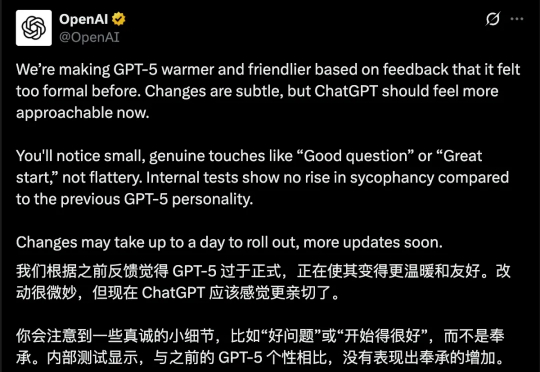
GPT-5上线引发全网吐槽。8月14日,ChatGPT负责人Nick Turley深度复盘了GPT-5发布「风波」,并详细总结了此次产品发布中的失误:比如过快下线GPT-4o、低估用户会对模型的情感依恋、没有让用户建立起「可预期性」等。Nick也分享了OpenAI的产品设计哲学,要坚持「真正对用户有帮助」的原则。