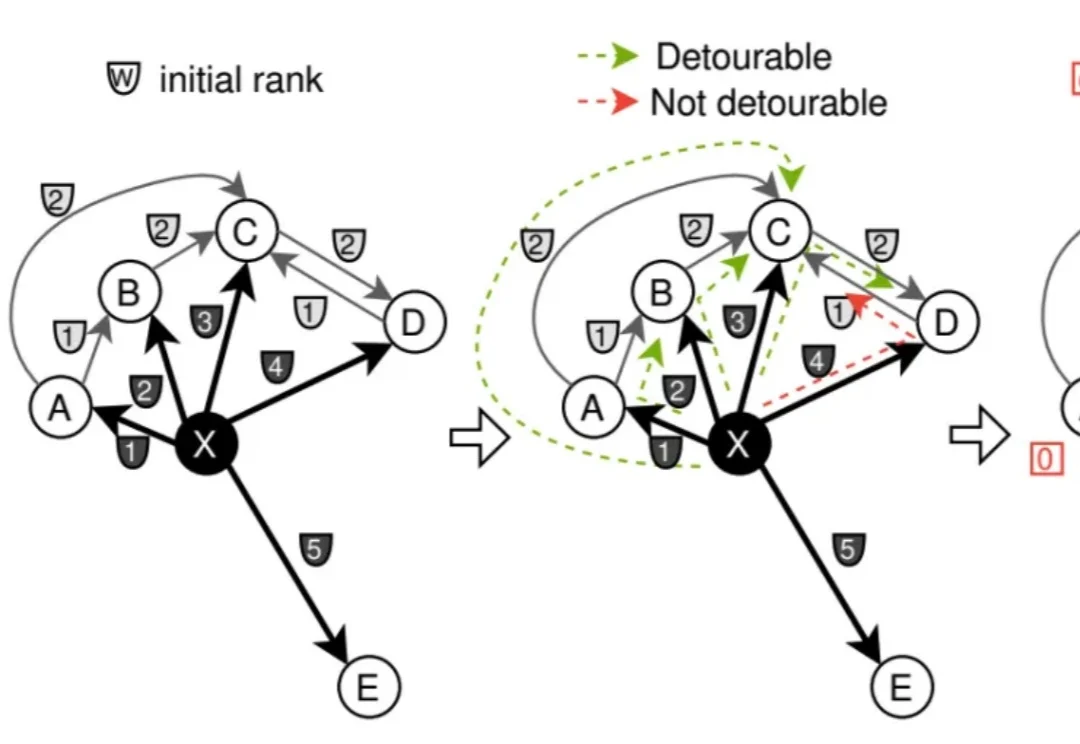
如何优化英伟达CAGRA,实现GPU建图+CPU查询,成本效率兼顾
如何优化英伟达CAGRA,实现GPU建图+CPU查询,成本效率兼顾本文为Milvus Week系列第5篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。
来自主题: AI技术研报
9309 点击 2025-12-09 10:36
 搜索
搜索
本文为Milvus Week系列第5篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。

GPU编程变天了。
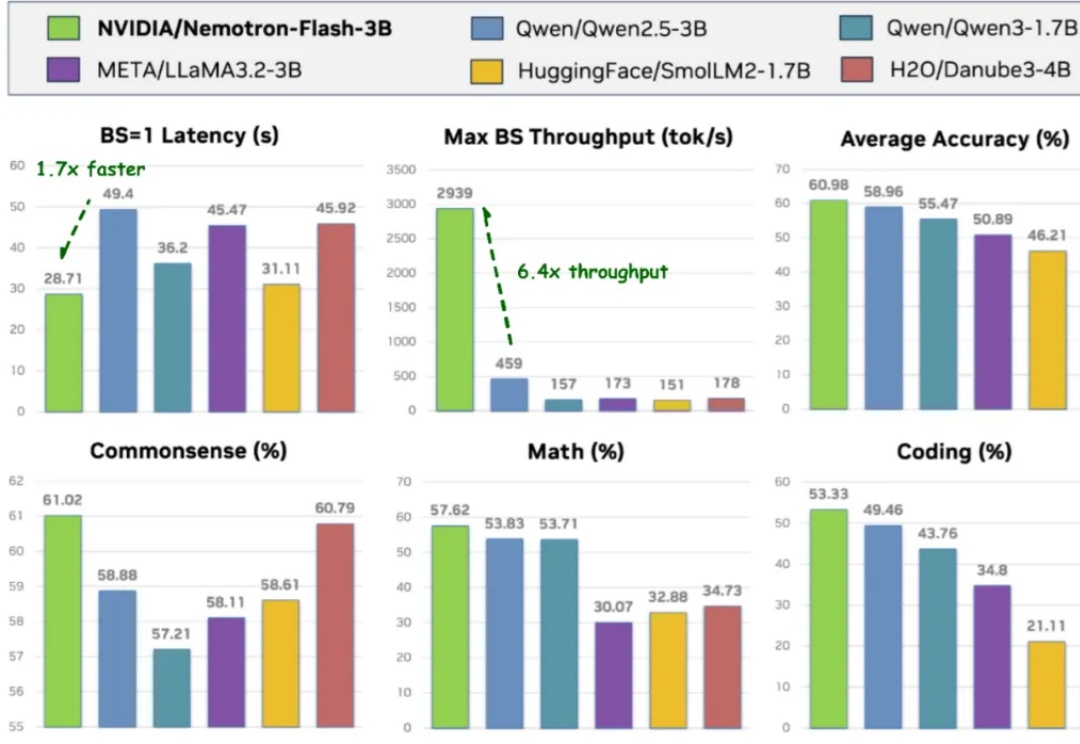
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。

在AI数据中心里,数以万计的英伟达H100 GPU,正静静地躺在地上吃灰。这些单价3万美元、被黄仁勋称为「工业黄金」的芯片,本该全速运转,为GPT-5或Sora注入灵魂,但此刻——它们没有电。

一听到谷歌要抢走10%的年收入,英伟达罕见地慌了。

带领IDEA研究院(粤港澳大湾区数字经济研究院)走过第五个年头的沈向洋,新鲜分享了他用来梳理智能演进的五个维度——作为IDEA研究院创院理事长,相比给出一个技术路径路线图,他更希望提出一个识别机会的思考框架,帮助创新者在智能演进中找到技术、产品与商业的切口。

2025 年 11 月 20 日,英伟达公布最新季度财报,2025 年 Q3 营收为 570.06 亿美元,较上年同期的 350.82 亿美元增长 62%;净利润为 319.10 亿美元,较上年同期的 193.09 亿美元增长 65%。英伟达强大的吸金能力再次超出所有人的预期,三年前英伟达的同期营收仅是现在的十分之一。

当美国把H100送进轨道试图复制「太空数字霸权」时,中国创业团队的「天算计划」正以万卡级超算中心为剑,在真空与辐射的绝境中找到一条掌握人类数字命运的新路。

史上最强三季度财报出炉,可能没有之一。黄仁勋一边把GPU卖到断货,一边告诉世界「AI不是泡沫,是历史必然」。这场算力狂潮到底是科技变革,还是资本宿命?

前不久写了一期卡神做的 nanochat ,听朋友说咱们国产早就有类似的开源项目了:miniMind 。