
国产视频模型,何以风靡美国社交媒体?
国产视频模型,何以风靡美国社交媒体?最近有一篇题为《2美元的H100:GPU泡沫是如何破灭的?》的文章异常火热,甚至投资人都认为英伟达坚挺的股价就是被这一篇文章所摧毁。
来自主题: AI资讯
6980 点击 2024-10-31 09:36
 搜索
搜索
最近有一篇题为《2美元的H100:GPU泡沫是如何破灭的?》的文章异常火热,甚至投资人都认为英伟达坚挺的股价就是被这一篇文章所摧毁。

人类已知最大的素数,被GPU发现了!英伟达前员工Luke Durant发现的2136279841-1,比前一个纪录保持者多出1600万位,由A100计算,H100确认。为此,小哥搭了数千个GPU的「云超算」,分布在17个国家。
Zamba2-7B是一款小型语言模型,在保持输出质量的同时,通过创新架构实现了比同类模型更快的推理速度和更低的内存占用,在图像描述等任务上表现出色,能在各种边缘设备和消费级GPU上高效运行。

TL;DR:DuoAttention 通过将大语言模型的注意力头分为检索头(Retrieval Heads,需要完整 KV 缓存)和流式头(Streaming Heads,只需固定量 KV 缓存),大幅提升了长上下文推理的效率,显著减少内存消耗、同时提高解码(Decoding)和预填充(Pre-filling)速度,同时在长短上下文任务中保持了准确率。

传统计算架构的潜力开发已接近极限 要实现超强的AI能力,需要超大规模的模型,要训练超大规模的AI模型,需要数千,甚至上万的GPU协同工作。

GPU租用市场越来越玄幻了,价格被打下来的原因,居然可以是天命人闲置的4090被循环利用了?
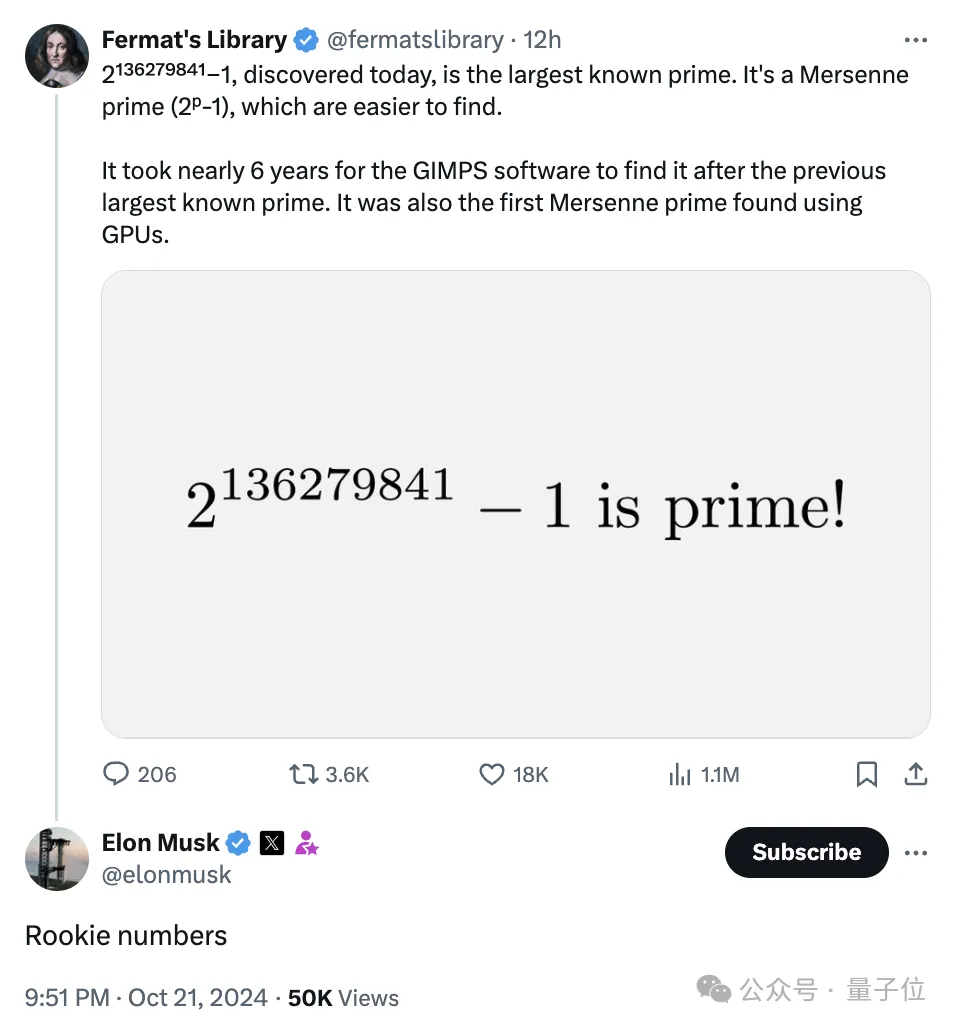
新的人类已知最大素数,被GPU发现!

欧洲博士生的这篇帖子火了!为啥美国博士生人手10篇顶会,5篇一作?有人现身说法:这里卷疯了,博士打底每天工作10小时,7天无休,不少人都卷出了心理问题。而且顶尖机构还有丰富的GPU资源和大佬的背书,能不能站在巨人的肩膀上,自然差之千里……

前不久在人工智能的帮助下,两位科学家获得了诺贝尔物理学奖。可以说人工智能已经在很多领域被广泛应用了。随着大语言模型(LLM)和深度学习的广泛应用,GPU 也已成为机器学习工程师和研究人员最重要的计算资源之一。

科技巨头如亚马逊、微软、谷歌和Meta每年在AI相关的投资上花费300亿至600亿美元。