DeepSeek强势回归,开源IMO金牌级数学模型
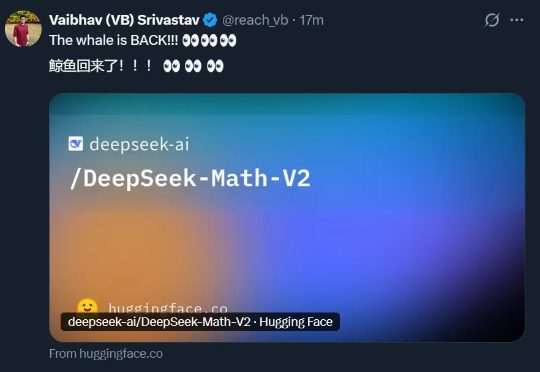
DeepSeek强势回归,开源IMO金牌级数学模型就在刚刚,DeepSeek 又悄咪咪在 Hugging Face 上传了一个新模型:DeepSeek-Math-V2。顾名思义,这是一个数学方面的模型。它的上一个版本 ——DeepSeek-Math-7b 还是一年多以前发的。当时,这个模型只用 7B 参数量,就达到了 GPT-4 和 Gemini-Ultra 性能相当的水平。相关论文还首次引入了 GRPO,显著提升了数学推理能力。
来自主题: AI资讯
9975 点击 2025-11-27 22:47