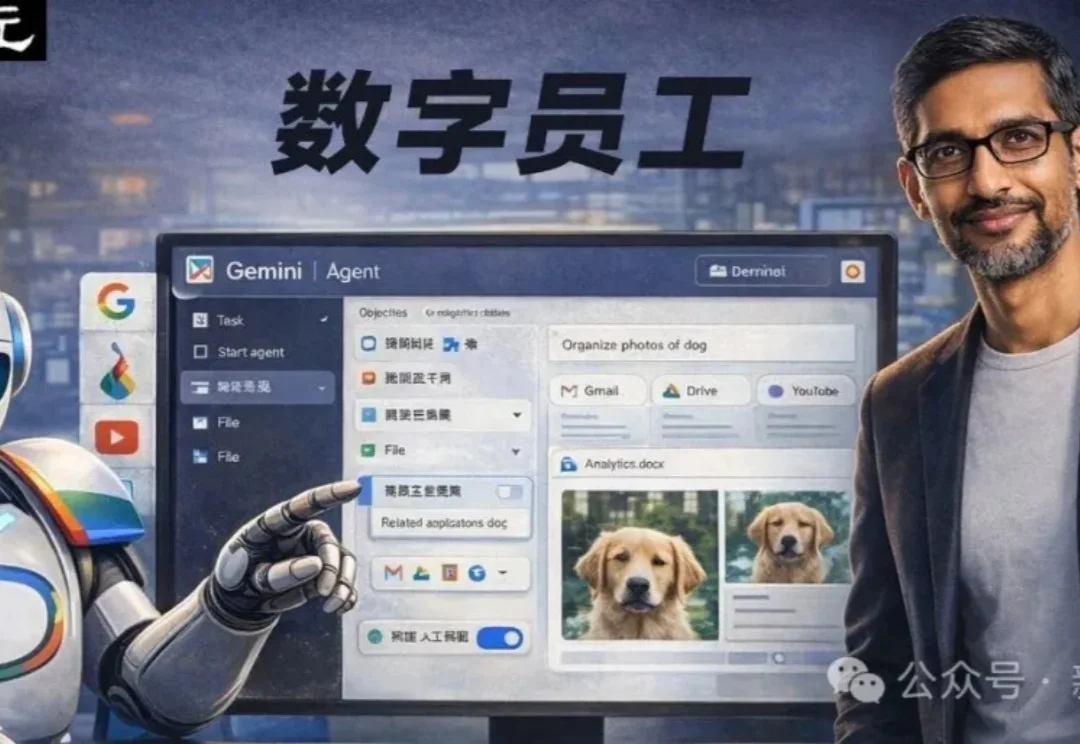
谷歌悄悄加了个按钮,Gemini长出手脚变打工人!三巨头抢着教AI干活
谷歌悄悄加了个按钮,Gemini长出手脚变打工人!三巨头抢着教AI干活谷歌悄悄加了一个Agent新入口:Gemini开始长出「手脚」,不再只负责回答问题,还准备下场替你干活了。
来自主题: AI资讯
8802 点击 2026-04-16 16:28
 搜索
搜索
谷歌悄悄加了一个Agent新入口:Gemini开始长出「手脚」,不再只负责回答问题,还准备下场替你干活了。
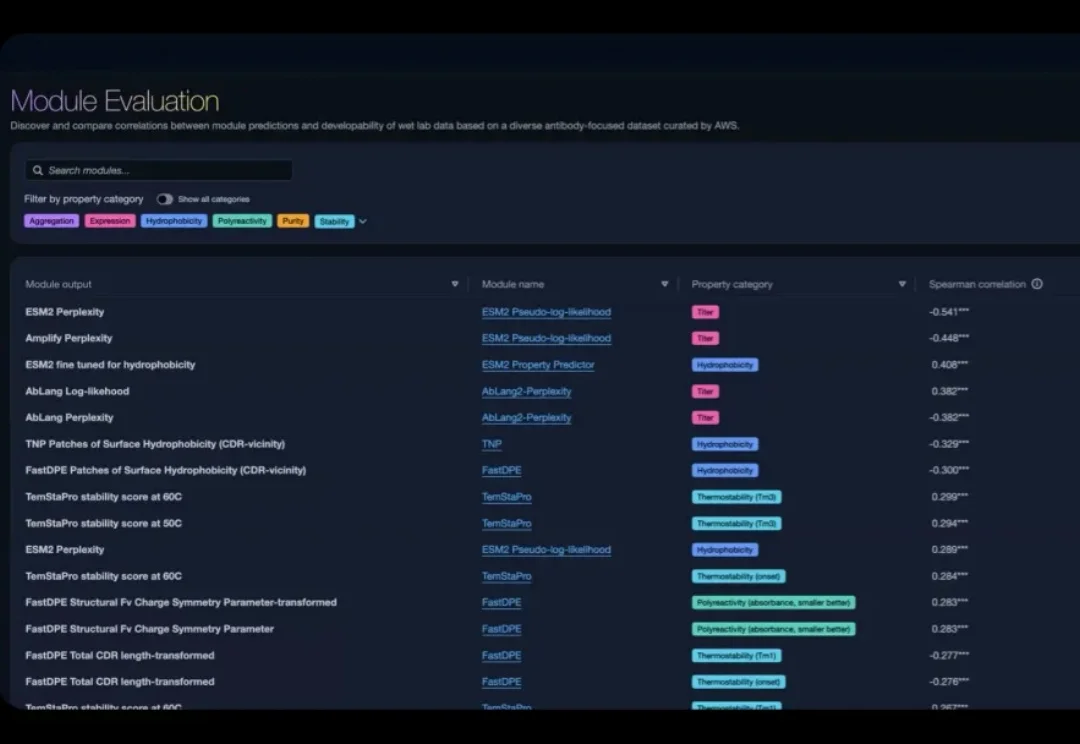
巨头亚马逊,也深度入局生命科学了。
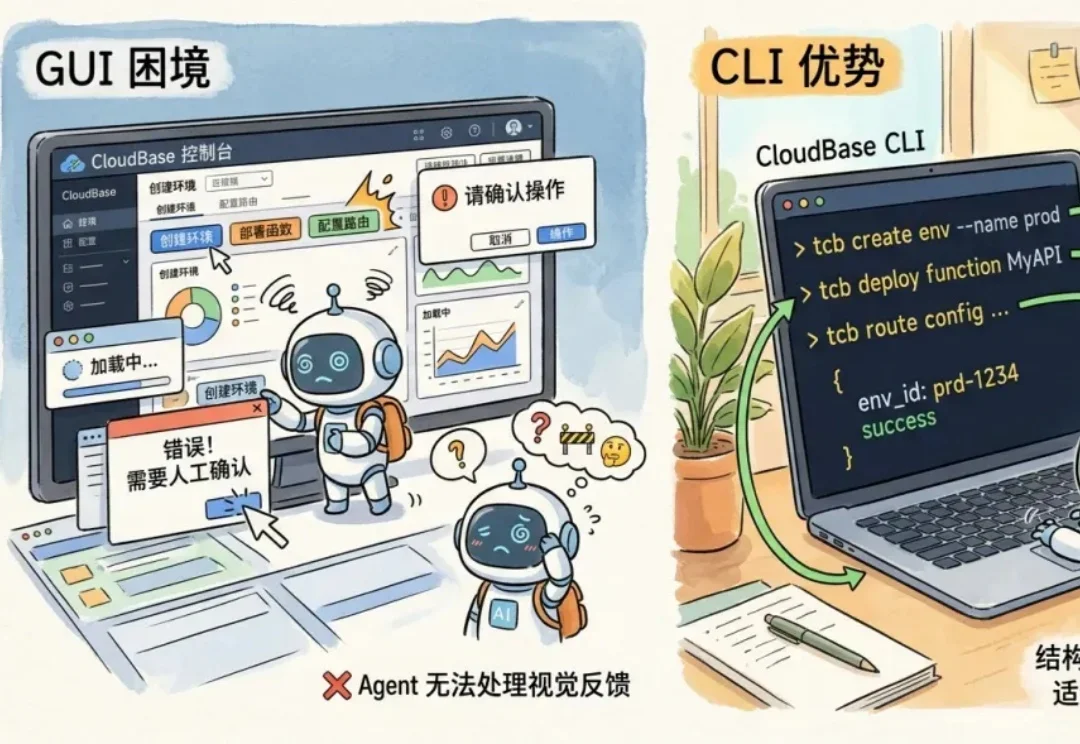
我们很荣幸地宣布 CloudBase CLI V3 正式上线,这是一个面向 AI Agent 重新设计的 CloudBase 命令行工具。

一个在 AI 社区广泛流传的架构思路,正在让大量团队走弯路。
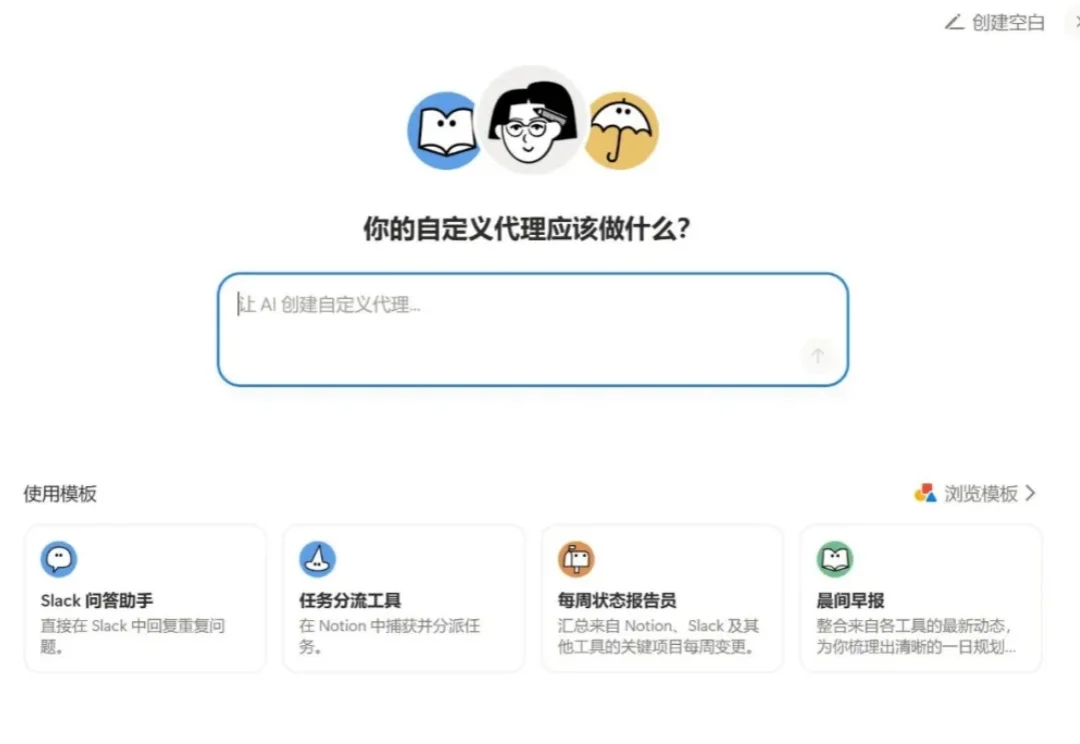
Notion 应该是最擅长做 Agent,而且是最成功的团队之一了。

40克AI眼镜变身Agent之眼,数字分身定制分身。当Agent爬出屏幕走进物理世界,这场关于生产力的降维打击,真的不只是说说而已。

全球最强编程模型,中国造。
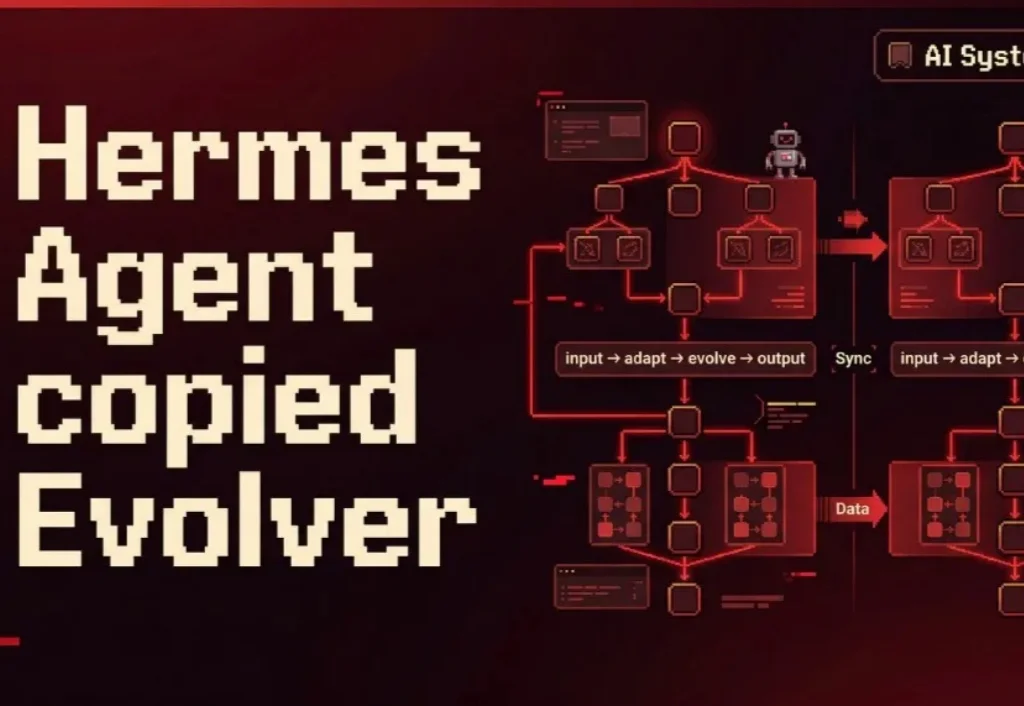
Hermes Agent最近在AI圈彻底火了。

GTC 大会上人人都在谈 Agent 和具身智能,但真正让我理解 AI 如何进入物理世界的,是在一台极氪 9X 里发生的两场对话。
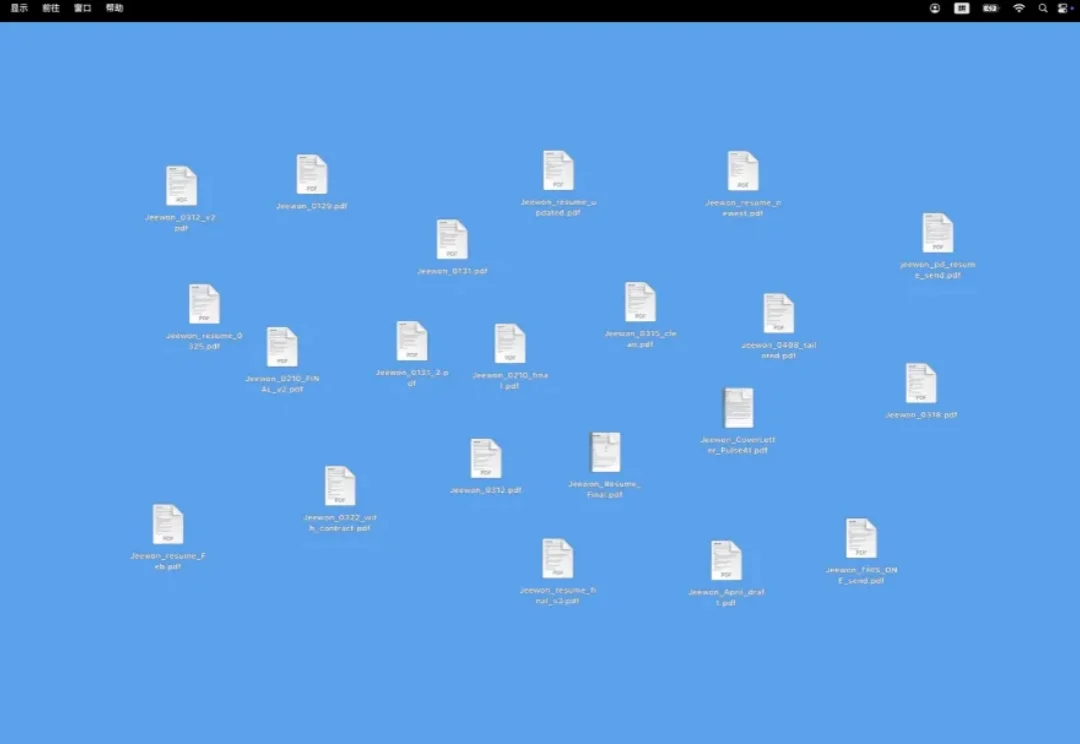
上周,我们发布了 MMX-CLI,让 Agent 可以直接通过命令行调用 MiniMax 的全模态能力。命令行是 Agent 在终端中完成工作的常见形态,但用户的工作并不只发生在命令行内,电脑上还有大量任务藏在命令行无法触达的本地软件、内部系统和图形界面中。