
全新稀疏注意力优化!腾讯最新超轻量视频生成模型HunyuanVideo 1.5核心技术解密
全新稀疏注意力优化!腾讯最新超轻量视频生成模型HunyuanVideo 1.5核心技术解密腾讯混元大模型团队正式发布并开源HunyuanVideo 1.5。
来自主题: AI技术研报
10155 点击 2025-11-27 10:10
 搜索
搜索
腾讯混元大模型团队正式发布并开源HunyuanVideo 1.5。
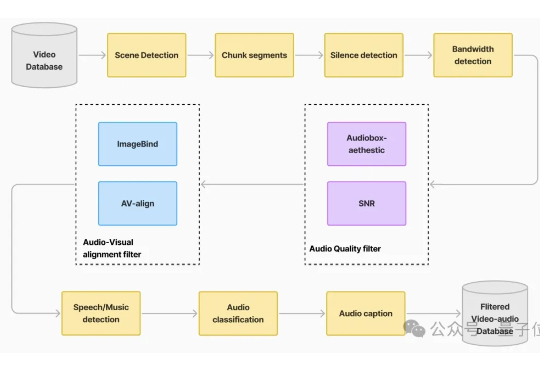
自带声音的视频生成模型,开源版开卷! 最新赶到的是腾讯混元:刚刚正式开源端到端的视频音效生成模型HunyuanVideo-Foley。
近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。

扩散模型在视频合成任务中取得了显著成果,但其依赖迭代去噪过程,带来了巨大的计算开销。尽管一致性模型(Consistency Models)在加速扩散模型方面取得了重要进展,直接将其应用于视频扩散模型却常常导致时序一致性和外观细节的明显退化。

虽然扩散模型在视频生成领域展现出了卓越的性能,但是视频扩散模型通常需要大量的推理步骤对高斯噪声进行去噪才能生成一个视频。这个过程既耗时又耗计算资源。例如,HunyuanVideo [1] 需要 3234 秒才能在单张 A100 上生成 5 秒、720×1280、24fps 的视频。
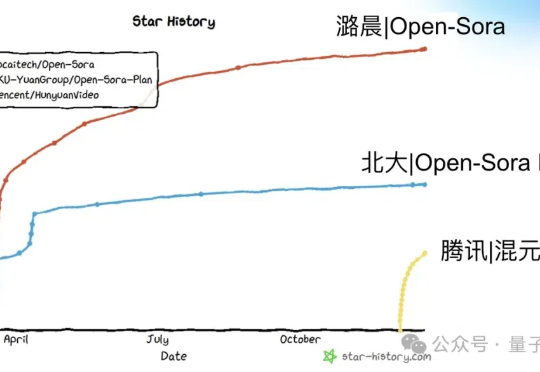
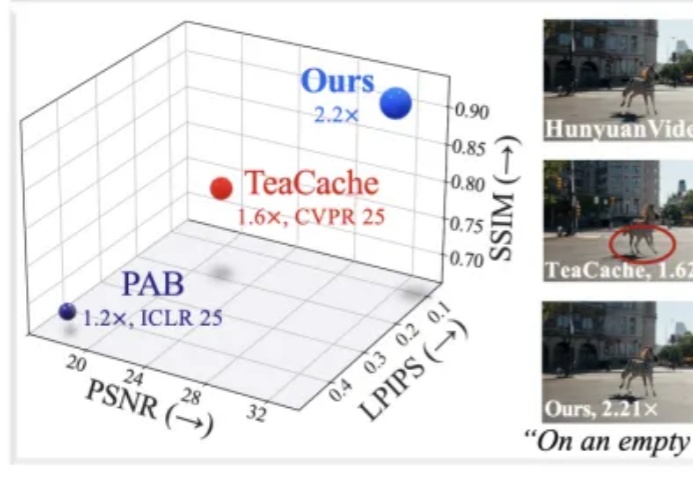
224张GPU,训出开源视频生成新SOTA!Open-Sora 2.0正式发布。 11B参数规模,性能可直追HunyuanVideo和Step-Video(30B)。
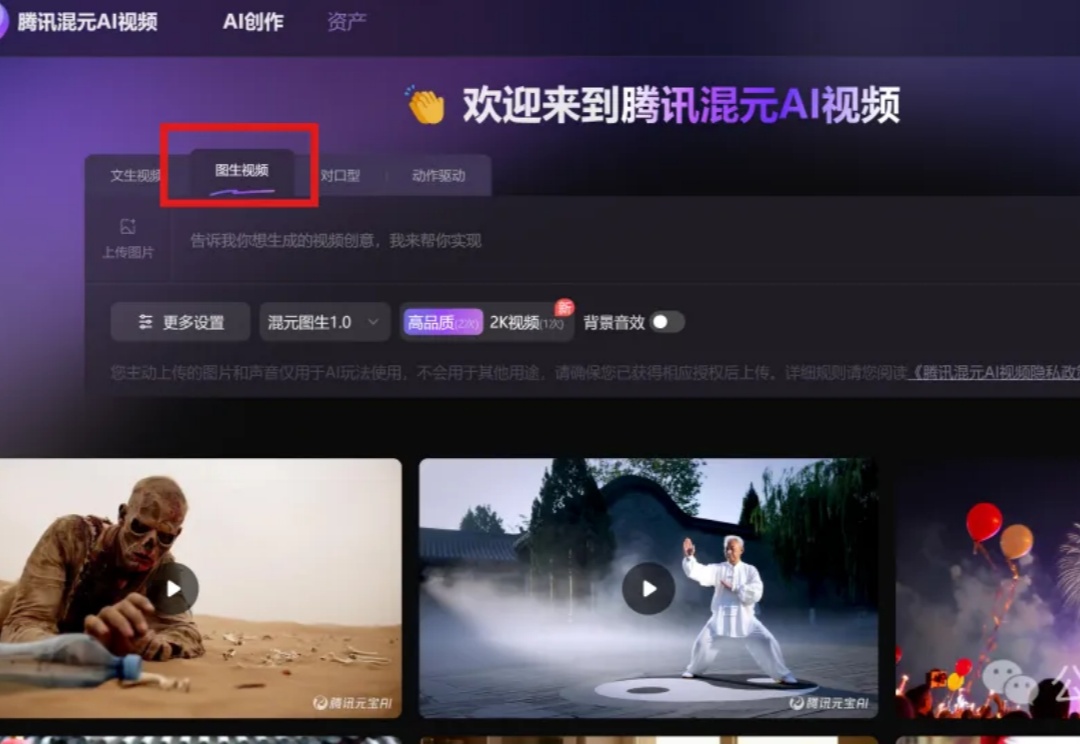
就在刚刚,腾讯版Sora补齐了又一重要拼图——图生视频。
无需额外模型训练、即插即用,全新的视频生成增强算法——Enhance-A-Video来了!