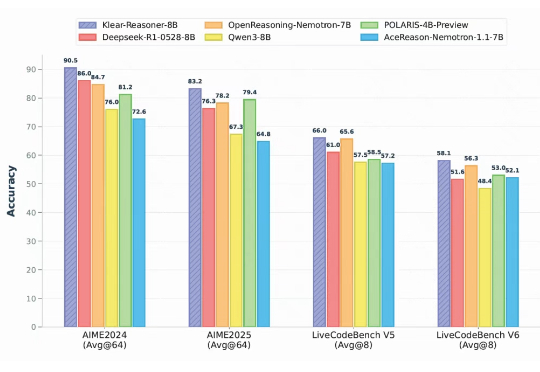
快手Klear-Reasoner登顶8B模型榜首,GPPO算法双效强化稳定性与探索能力! 快手Klear-Reasoner登顶8B模型榜首,GPPO算法双效强化稳定性与探索能力! 关键词: AI新闻,模型训练,Klear-Reasoner,人工智能 在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。 来自主题: AI技术研报 7070 点击 2025-08-22 17:23