LLM已进入「组装」时代,CAIS复合人工智能系统来了
LLM已进入「组装」时代,CAIS复合人工智能系统来了2024年,伯克利人工智能研究中心(BAIR)率先提出了一个新概念——复合人工智能系统(Compound AI Systems,简称CAIS)。这个看似简单的术语背后,蕴含着AI系统架构的根本性改变:不再依赖单一LLM的"超级大脑",而是构建多组件协同的"智能生态系统"。
来自主题: AI技术研报
9580 点击 2025-06-09 11:32
 搜索
搜索
2024年,伯克利人工智能研究中心(BAIR)率先提出了一个新概念——复合人工智能系统(Compound AI Systems,简称CAIS)。这个看似简单的术语背后,蕴含着AI系统架构的根本性改变:不再依赖单一LLM的"超级大脑",而是构建多组件协同的"智能生态系统"。

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。

通过这份全面指南探索大语言模型(LLMs)的关键概念、技术和挑战,专为AI爱好者和准备面试的专业人士精心打造。
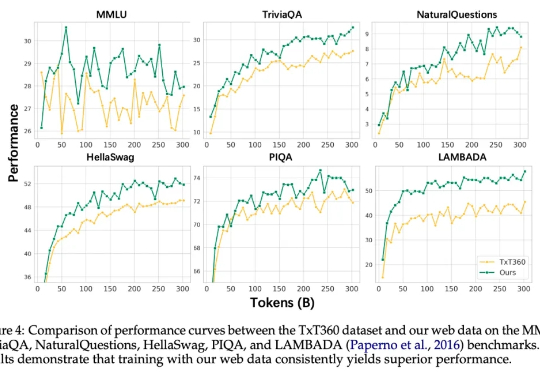
迄今为止行业最大的开源力度。在大模型上向来低调的小红书,昨天开源了首个自研大模型。
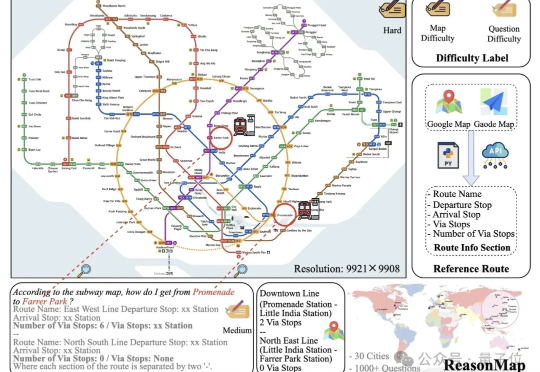
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。

6 月 6 日,小红书 hi lab(Humane Intelligence Lab,人文智能实验室)团队首次开源了文本大模型 dots.llm1,采用 MIT 许可证。
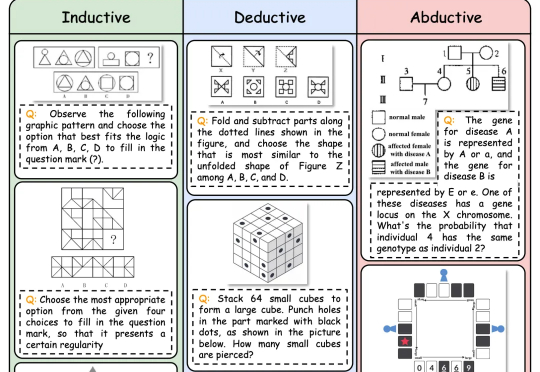
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)
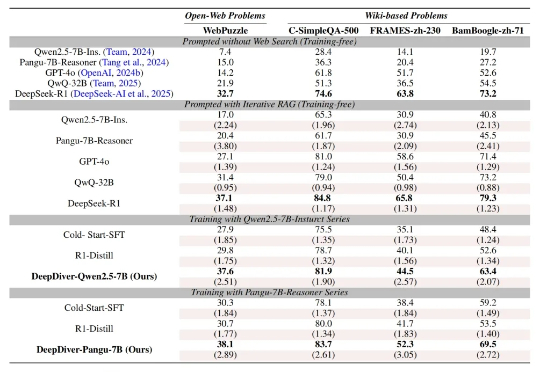
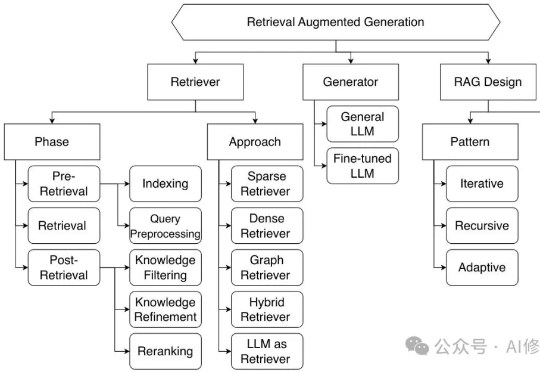
大型语言模型 (LLM) 的发展日新月异,但实时「内化」与时俱进的知识仍然是一项挑战。如何让模型在面对复杂的知识密集型问题时,能够自主决策获取外部知识的策略?

World Labs 是由著名 AI 专家、斯坦福大学教授李飞飞于 2024 年创办的初创公司,致力于开发具备“空间智能”的下一代 AI 系统。
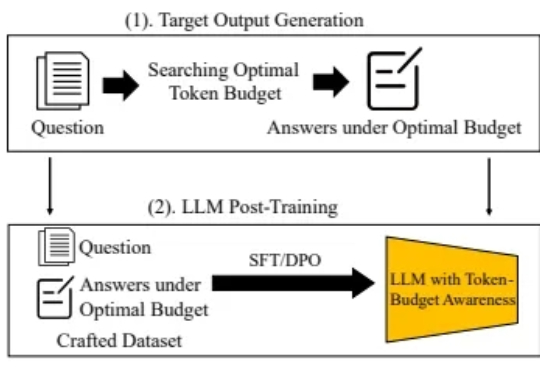
随着大型语言模型(LLM)技术的不断发展,Chain-of-Thought(CoT) 等推理增强方法被提出,以期提升模型在数学题解、逻辑问答等复杂任务中的表现,并通过引导模型逐步思考,有效提高了模型准确率。