
深度揭秘CoT!普林斯顿耶鲁发布最新报告:大模型既有记忆推理、也有概率推理
深度揭秘CoT!普林斯顿耶鲁发布最新报告:大模型既有记忆推理、也有概率推理研究人员通过案例研究,利用大型语言模型(LLMs)如GPT-4、Claude 3和Llama 3.1,探索了思维链(CoT)提示在解码移位密码任务中的表现;CoT提示虽然提升了模型的推理能力,但这种能力并非纯粹的符号推理,而是结合了记忆和概率推理的复杂过程。
来自主题: AI技术研报
4961 点击 2024-11-13 09:07
 搜索
搜索
研究人员通过案例研究,利用大型语言模型(LLMs)如GPT-4、Claude 3和Llama 3.1,探索了思维链(CoT)提示在解码移位密码任务中的表现;CoT提示虽然提升了模型的推理能力,但这种能力并非纯粹的符号推理,而是结合了记忆和概率推理的复杂过程。

第8届CoRL于2024年11月6日至9日在德国慕尼黑举行,展示了机器人学习领域的前沿研究和发展,尤其是在自主系统、机器人控制和多模态人工智能领域。
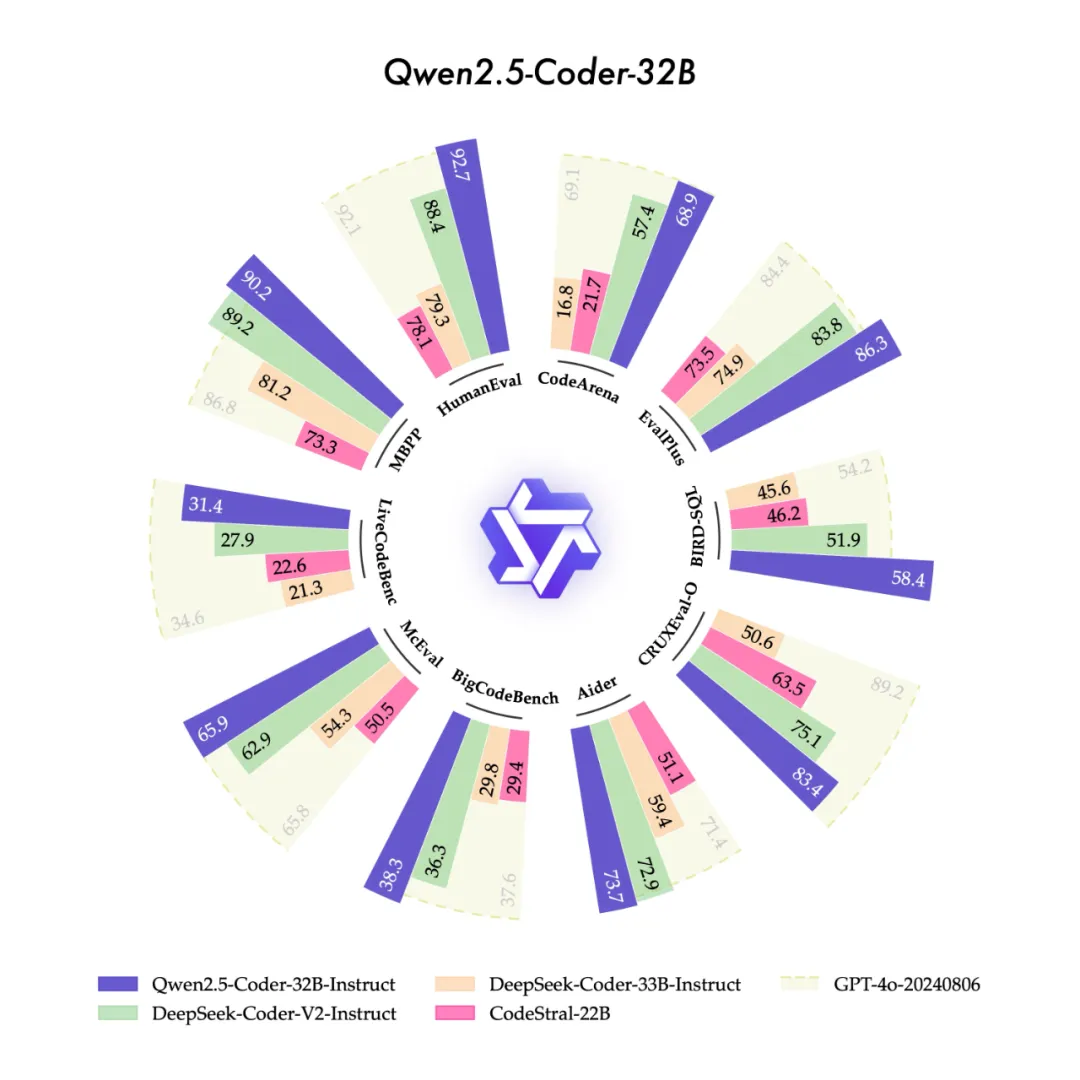
今天,我们很高兴开源“强大”、“多样”、“实用”的Qwen2.5-Coder全系列模型,致力于持续推动Open CodeLLMs的发展。

现在,用LLM一键就能生成百万级领域知识图谱了?! 来自中科大MIRA实验室研究人员提出一种通用的自动化知识图谱构建新框架SAC-KG
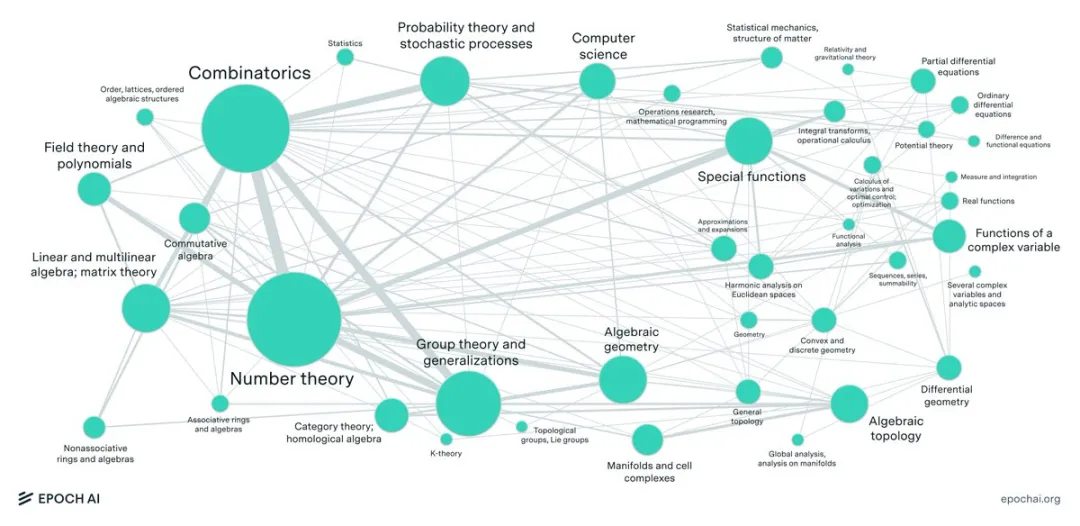
大型语言模型(LLM)最近在各种数学benchmark上疯狂刷分,动辄90%以上的正确率,搞得好像要统治数学界一样。然而,Epoch AI看不下去了,联手60多位顶尖数学家,憋了个大招——FrontierMath,一个专治LLM各种不服的全新数学推理测试!结果惨不忍睹,LLM集体“翻车”,正确率竟然不到2%!
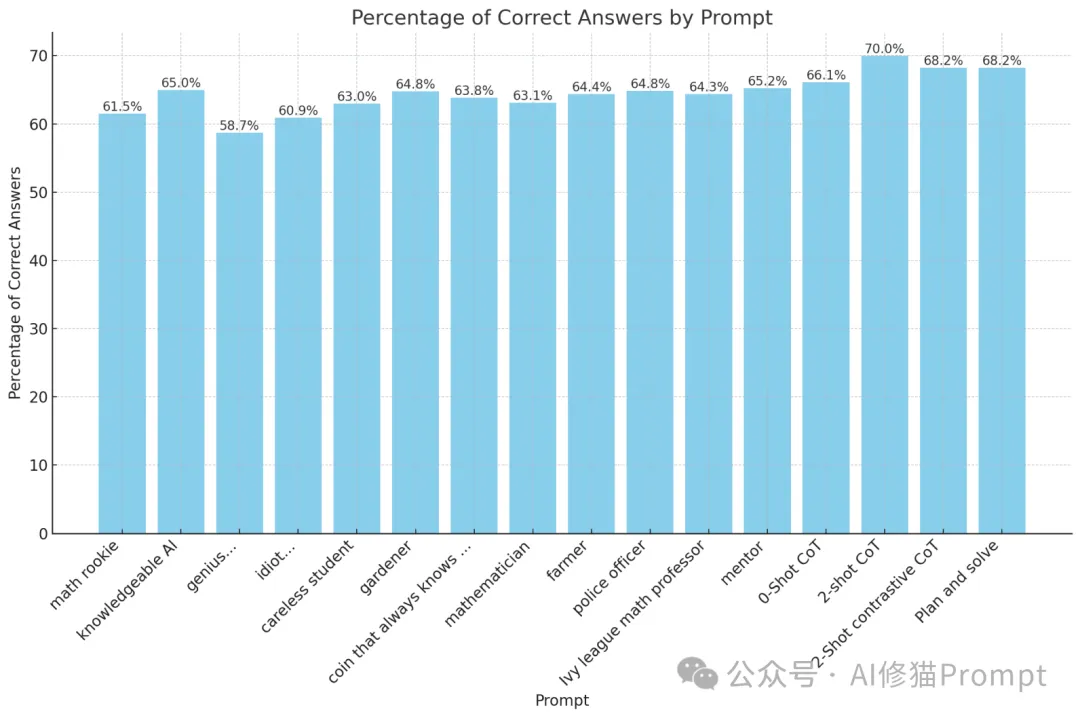
在Prompt工程领域,角色扮演提示是否能够有效提高大型语言模型(LLM)的性能一直是一个备受关注的话题。

生成式人工智能GenAI是否存在泡沫?这个问题日益成为业界热议的焦点。目前,全球对AI基础设施的投资已到了癫狂的成千上万亿美元的规模,然而大模型如何实现盈利却始终没有一个明确的答案。

大模型幻觉,究竟是怎么来的?谷歌、苹果等机构研究人员发现,大模型知道的远比表现的要多。它们能够在内部编码正确答案,却依旧输出了错误内容。

大模型的记忆限制被打破了,变相实现“无限长”上下文。最新成果,来自清华、厦大等联合提出的LLMxMapReduce长本文分帧处理技术。
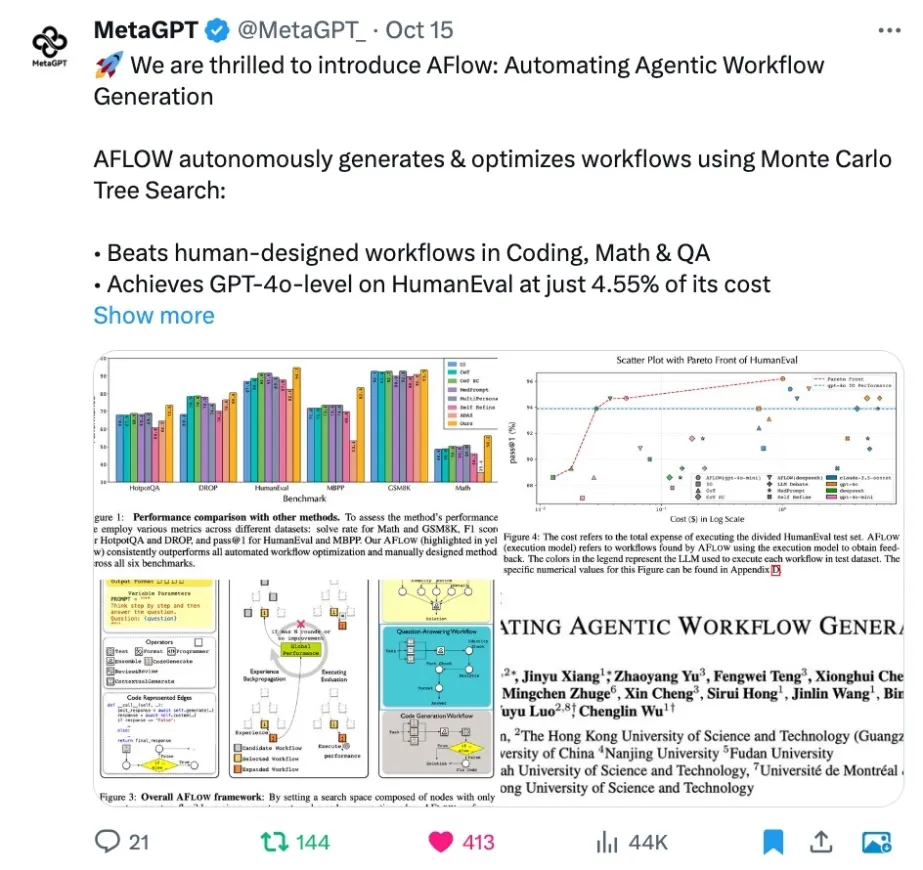
对于 LLM 从业者来说,让 LLM 落地应用并发挥作用需要手动构建并反复调试 Agentic Workflow,这无疑是个繁琐过程,一遍遍修改相似的代码,调试 prompt,手动执行测试并观察效果,并且换个 LLM 可能就会失效,有高昂的人力成本。许多公司甚至专职招聘 Prompt Engineer 来完成这一工作。