运行LIama2得8400万元!最快AI推理芯片成本推算引热议
运行LIama2得8400万元!最快AI推理芯片成本推算引热议这两天,Groq惊艳亮相。它以号称“性价比高英伟达100倍”的芯片,实现每秒500tokens大模型生成,感受不到任何延迟。外加谷歌TPU团队这样一个高精尖人才Buff,让不少人直呼:英伟达要被碾压了……
来自主题: AI资讯
5170 点击 2024-02-21 16:39
 搜索
搜索
这两天,Groq惊艳亮相。它以号称“性价比高英伟达100倍”的芯片,实现每秒500tokens大模型生成,感受不到任何延迟。外加谷歌TPU团队这样一个高精尖人才Buff,让不少人直呼:英伟达要被碾压了……

成功从过去的经验中提取知识并将其应用于未来的挑战,这是人类进化之路上重要的里程碑。那么在人工智能时代,AI 智能体是否也可以做到同样的事情呢?

2023 年 12 月,首个开源 MoE 大模型 Mixtral 8×7B 发布,在多种基准测试中,其表现近乎超越了 GPT-3.5 和 LLaMA 2 70B,而推理开销仅相当于 12B 左右的稠密模型。为进一步提升模型性能,稠密 LLM 常由于其参数规模急剧扩张而面临严峻的训练成本。
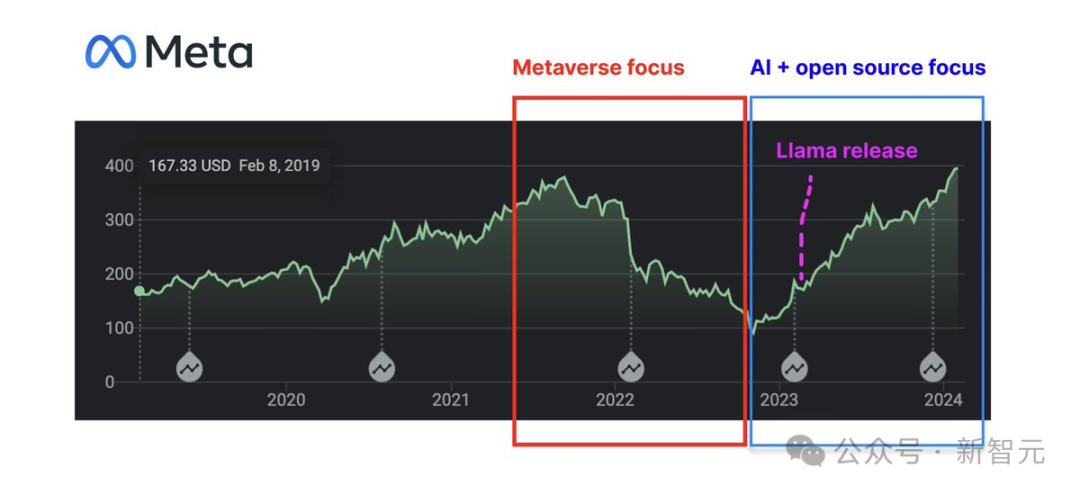
把小扎从元宇宙大坑中拯救出来的,居然是开源AI!市值大涨的Meta,现在能让小扎一年分红7亿美元。股价图一出,LeCun都评论:有意思。

有的大模型对齐方法包括基于示例的监督微调(SFT)和基于分数反馈的强化学习(RLHF)。然而,分数只能反应当前回复的好坏程度,并不能明确指出模型的不足之处。相较之下,我们人类通常是从语言反馈中学习并调整自己的行为模式。

在 AI 赛道中,与动辄上千亿参数的模型相比,最近,小模型开始受到大家的青睐。比如法国 AI 初创公司发布的 Mistral-7B 模型,其在每个基准测试中,都优于 Llama 2 13B,并且在代码、数学和推理方面也优于 LLaMA 1 34B。

2B性能小钢炮来了!刚刚,面壁智能重磅开源了旗舰级端侧多模态模型MiniCPM,2B就能赶超Mistral-7B,还能越级比肩Llama2-13B。成本更是低到炸裂,170万tokens成本仅为1元!
羊驼家族的“最强开源代码模型”,迎来了它的“超大杯”——就在今天凌晨,Meta宣布推出Code Llama的70B版本。

删除权重矩阵的一些行和列,让 LLAMA-2 70B 的参数量减少 25%,模型还能保持 99% 的零样本任务性能,同时计算效率大大提升。这就是微软 SliceGPT 的威力。
Meta 正式发布 Code Llama 70B,这是 Code Llama 系列有史以来最大、性能最好的型号。