
前OpenAI CTO押注的赛道,被中国团队抢先跑通,AI「下半场」入场券人人有份
前OpenAI CTO押注的赛道,被中国团队抢先跑通,AI「下半场」入场券人人有份在大公司一路高歌猛进的 AI 浪潮里,小创业者和高校研究者正变得越来越迷茫。就连前段时间谷歌创始人谢尔盖・布林回斯坦福,都要回答「大学该何去何从」「从学术到产业的传统路径是否依然重要」这类问题。
来自主题: AI技术研报
6001 点击 2026-01-04 16:56
在大公司一路高歌猛进的 AI 浪潮里,小创业者和高校研究者正变得越来越迷茫。就连前段时间谷歌创始人谢尔盖・布林回斯坦福,都要回答「大学该何去何从」「从学术到产业的传统路径是否依然重要」这类问题。

最近,APPSO 终于拿到了这台来自黄仁勋倾情推荐的个人超算,英伟达 DGX Spark;到手的第一感觉,就是「小而美」。这电脑也太小了,没有 Mac Studio 那般笨重,可能就和 Mac Mini 差不多大;然后是银色的亮和用来散热的金属丝网又让它有点不一样,是专属的硬核美感。

马斯克“巨硬计划”新消息,第三栋专属厂房已经买下来了,代号MACROHARDRR。果然更硬核,老马透露,其将具备2GW供电规模。若参照此前曝光的(200MW支持11万台GB200)的功耗密度与架构效率推算,可支持约110万台英伟达GB200 NVL72 GPU。

你知道吗,DeepSeekTwitter、Mac、Qwen,最初都只是副项目?真正改变世界的产品,可能根本不在公司的PPT路线图上。
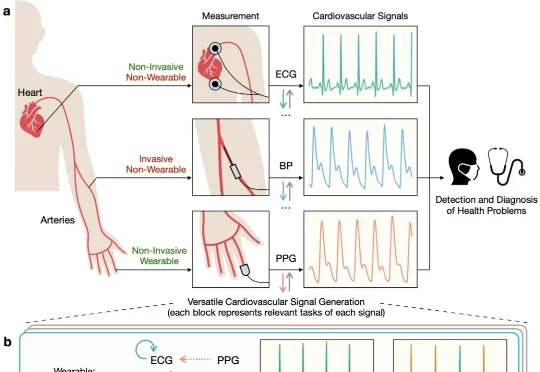
近日,清华朱军等团队提出了一种统一的多模态生成框架 UniCardio,在单扩散模型中同时实现了心血管信号的去噪、插补与跨模态生成,为真实场景下的人工智能辅助医疗提供了一种新的解决思路。

近日,刚刚 IPO 的国产 GPU 公司沐曦股份,完成了自上市后的首个重大技术发布。

霍尔特计划收购老东家新山资本旗下最成功的五家医疗科技公司,并将其合并到其新创立的AI医疗平台——Thoreau。这五家公司分别是:健康数据交换巨头Datavant、AI理赔优化平台Machinify、精准医疗营销商Swoop、医疗流程自动化公司Smarter Technologies 以及电子医疗记录平台Office Ally。

英伟达低调出手收购SchedMD,被业界评价为:悄悄把自家的护城河拓宽了。
当前,AI 领域的研究者与开发者在关注 OpenAI、Google 等领先机构最新进展的同时,也将目光投向了由前 OpenAI CTO Mira Murati 创办的 Thinking Machines Lab。

大家还记得Mira Murati吗?那个曾经主导ChatGPT开发的“AI女王”,OpenAI的前CTO,2024年突然离职后,让整个科技圈炸锅!短短几个月,融资20亿美元,估值飙到120亿美元,现在更传出新一轮融资目标直冲500亿美元!这速度,这手笔,简直是AI界的“神话”!而最近的重磅炸弹来了:他们的首款产品Tinker正式全面开放!不再需要等待名单,人人可用!