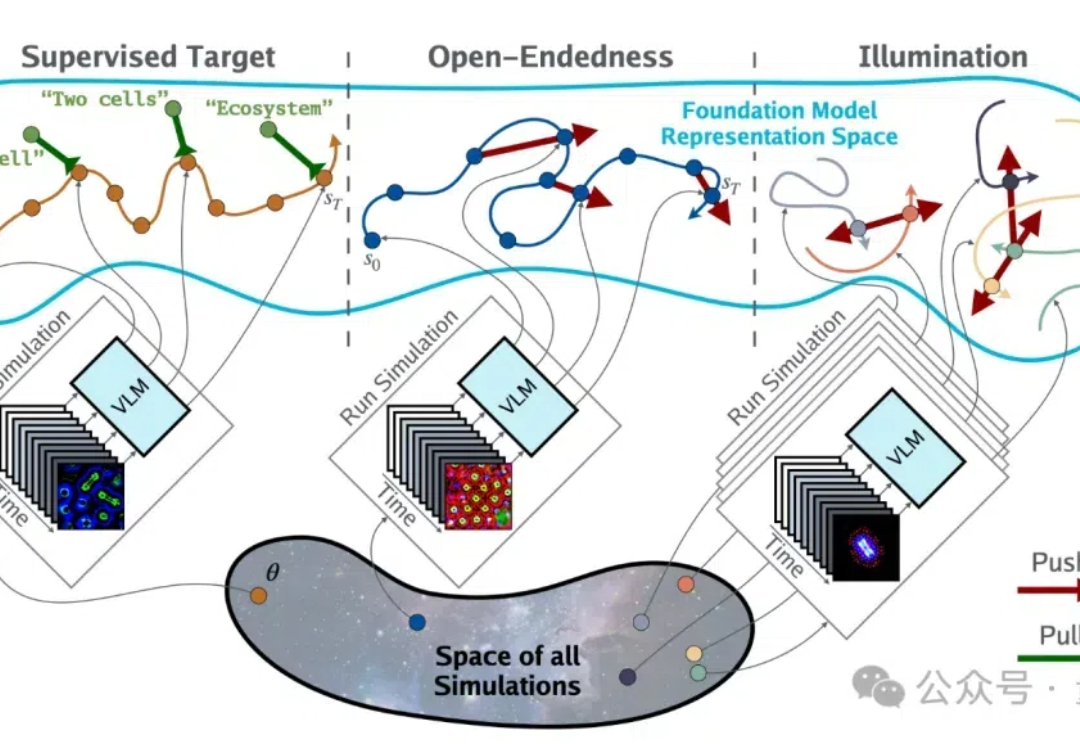
大模型版生命游戏来了!「AI科学家」背后公司联手MIT&OpenAI等打造
大模型版生命游戏来了!「AI科学家」背后公司联手MIT&OpenAI等打造大模型版生命游戏来了。
来自主题: AI技术研报
9468 点击 2024-12-25 14:21
 搜索
搜索
大模型版生命游戏来了。

OpenAI在LangSmith用户群中继续稳居最常使用的大语言模型供应商宝座,其使用率是排名第二的Ollama的六倍以上。开源模型的采用率有了显著增长,特别是Ollama和Groq两家公司,它们支持用户运行开源模型,并在今年成功跻身行业前五。

2024 年 12 月 10-15 日,今年度的 NeurIPS 已在加拿大温哥华成功举办。今年的会议上,我们看到了 Ilya Sutskever 关于预训练即将终结的预测,也看到了引发广泛争议的 MIT 教授 NeurIPS 演讲公开歧视中国学生的事件。

全球最年轻的 95 后亿万富翁、MIT 辍学生以及估值超 1000 亿的 AI 独角兽 Scale AI 创始人 Alexandr Wang 近期在 SPC 对谈时回顾了自己在 YC 创业加速器的经历。

MIT教授侮辱中国学生的言论,彻底掀翻了整个学术圈!在NeurIPS受邀演讲中,她大放厥词「中国学生不诚实」,并在一张PPT明确提到中国国籍。这一恶性事件,引来Jeff Dean等业界大佬怒斥。
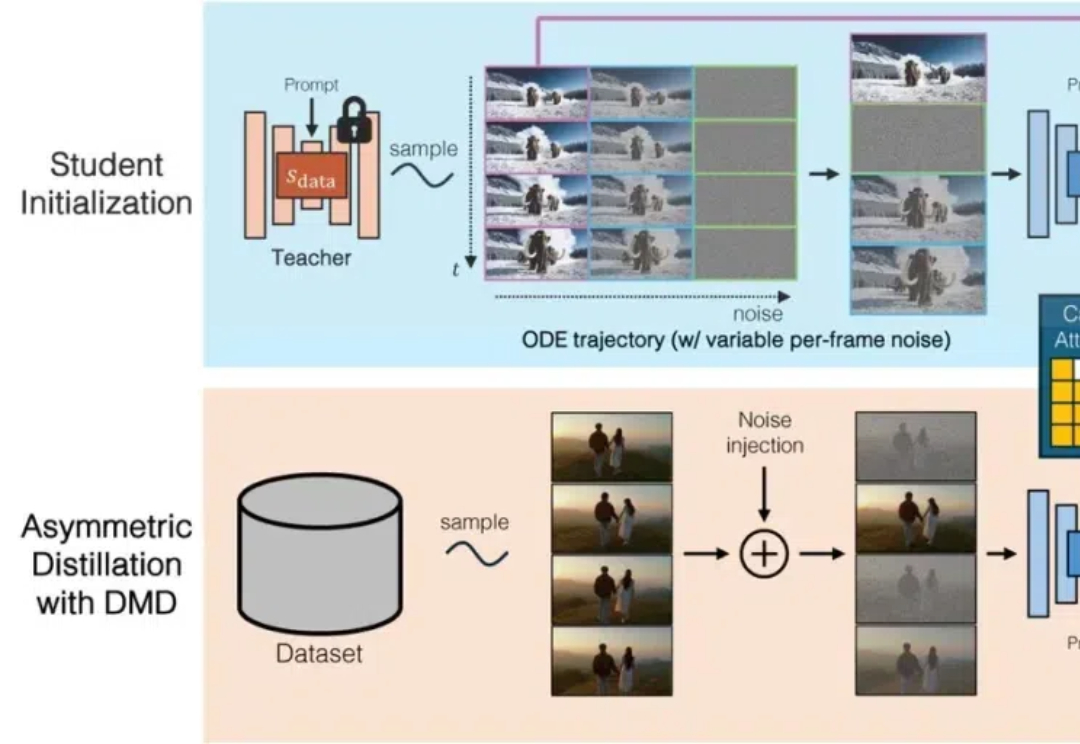
AI生成视频,边生成边实时播放,再不用等了! Adobe与MIT联手推出自回归实时视频生成技术——CausVid。
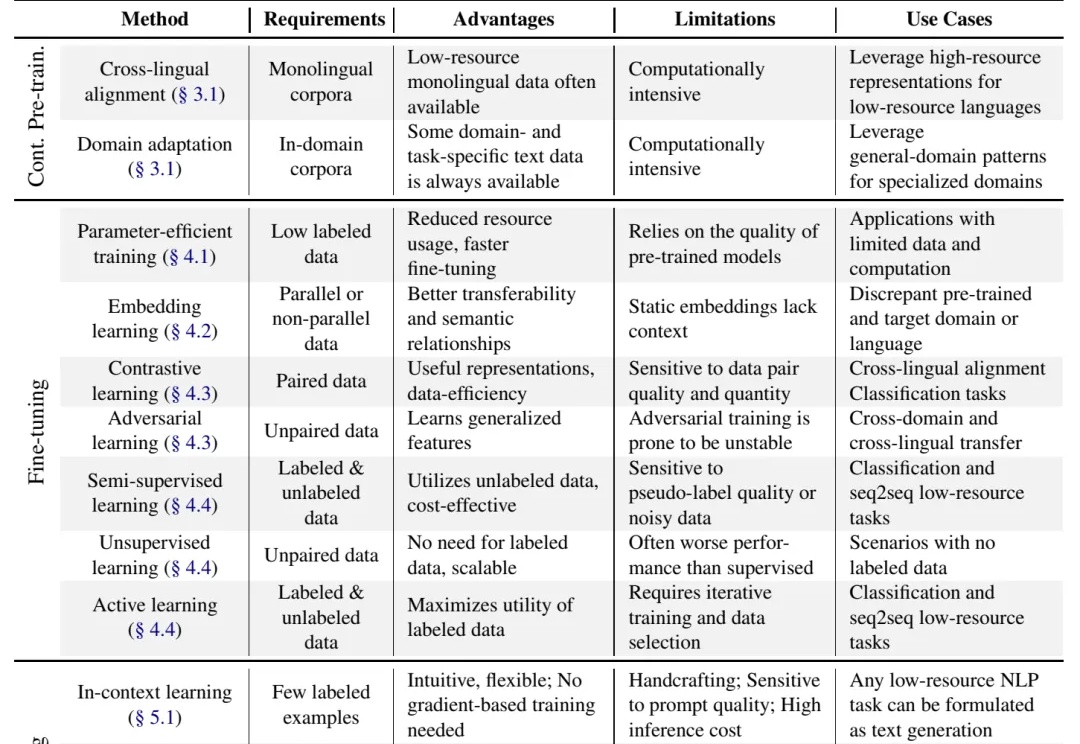
别说什么“没数据就去标注啊,没钱标注就别做大模型啊”这种风凉话,有些人数据不足也能做大模型,是因为有野心,就能想出来稀缺数据场景下的大模型解决方案,或者整理出本文将要介绍的 "Practical Guide to Fine-tuning with Limited Data" 这样的综述。
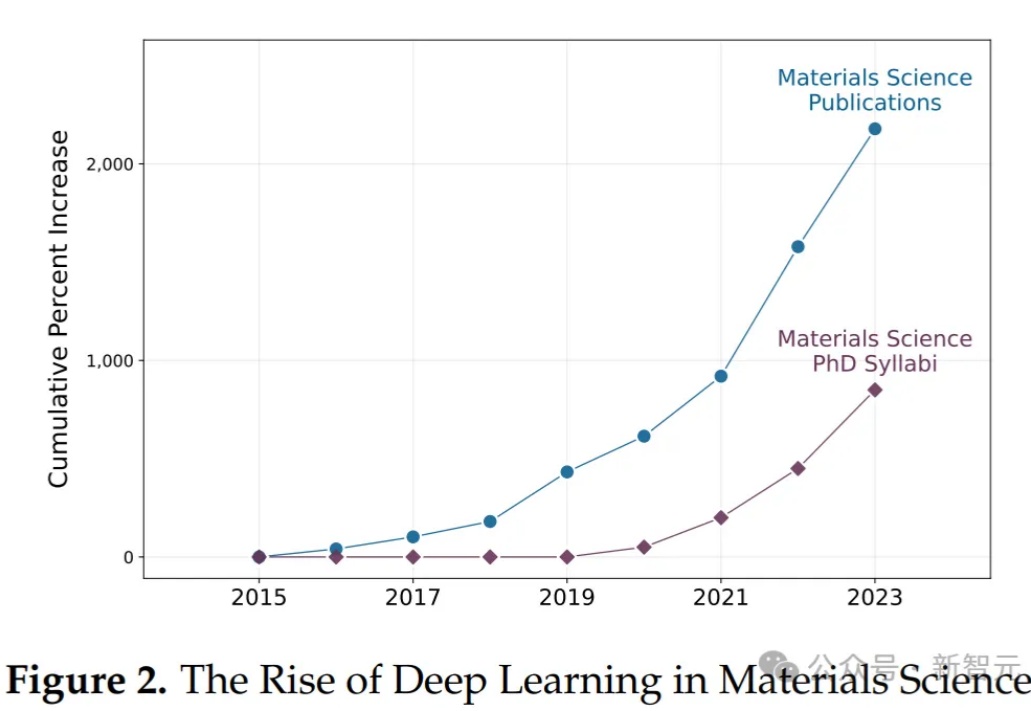
MIT的76页深度报告!AI辅助创新显著增长——这毋庸置疑。但,值得注意的是,AI加剧了不同水平科学家产出的差异,这与科学家的判断力强相关,意味着缺乏判断力的科学家在未来可能会被慢慢淘汰……

近日,来自斯坦福、MIT等机构的研究人员推出了低秩线性转换方法,让传统注意力无缝转移到线性注意力,仅需0.2%的参数更新即可恢复精度,405B大模型两天搞定!

自我纠错(Self Correction)能力,传统上被视为人类特有的特征,正越来越多地在人工智能领域,尤其是大型语言模型(LLMs)中得到广泛应用,最近爆火的OpenAI o1模型[1]和Reflection 70B模型[2]都采取了自我纠正的方法。