

超DeepEP两倍!无问芯穹FUSCO以「空中变阵」突破MoE通信瓶颈,专为Agent爆发设计
超DeepEP两倍!无问芯穹FUSCO以「空中变阵」突破MoE通信瓶颈,专为Agent爆发设计机器之心发布 随着 ChatGPT、Gemini、DeepSeek-V3、Kimi-K2 等主流大模型纷纷采用混合专家架构(Mixture-of-Experts, MoE)及专家并行策略(Expert
来自主题: AI技术研报
8508 点击 2026-01-01 10:14
机器之心发布 随着 ChatGPT、Gemini、DeepSeek-V3、Kimi-K2 等主流大模型纷纷采用混合专家架构(Mixture-of-Experts, MoE)及专家并行策略(Expert

最近,Prime Intellect正式发布了INTELLECT-3。这是一款拥有106B参数的混合专家(Mixture-of-Experts)模型,基于Prime Intellect的强化学习(RL)技术栈训练。在数学、代码、科学与推理的各类基准测试上,它达成了同规模中最强的成绩,甚至超越了不少更大的前沿模型。
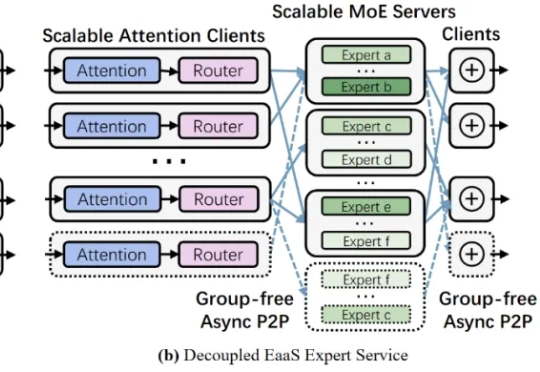
近年来,大型语言模型的参数规模屡创新高,随之而来的推理开销也呈指数级增长。如何降低超大模型的推理成本,成为业界关注的焦点之一。Mixture-of-Experts (MoE,混合专家) 架构通过引入大量 “专家” 子模型,让每个输入仅激活少数专家,从而在参数规模激增的同时避免推理计算量同比增长。

Transformer杀手来了?KAIST、谷歌DeepMind等机构刚刚发布的MoR架构,推理速度翻倍、内存减半,直接重塑了LLM的性能边界,全面碾压了传统的Transformer。网友们直呼炸裂:又一个改变游戏规则的炸弹来了。
如果你正在开发Agent产品,一定听过或用过Mixture-of-Agents(MoA)架构。这个让多个AI模型协作解决复杂问题的框架,理论上能够集众家之长,实际使用中却让人又爱又恨:
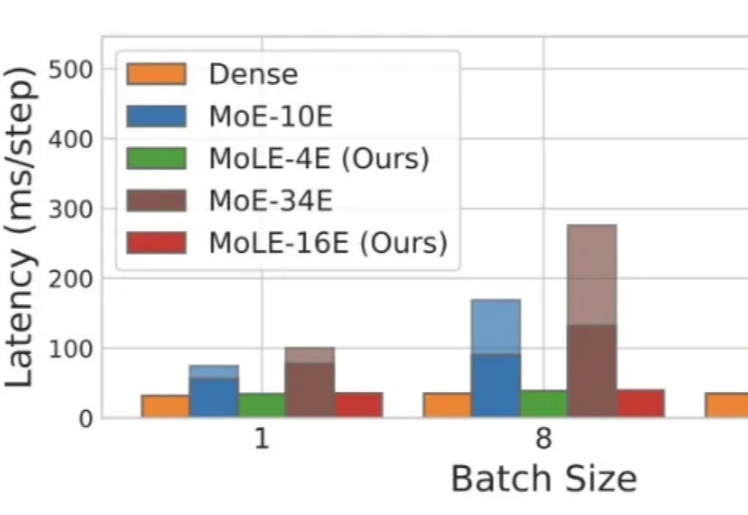
Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。
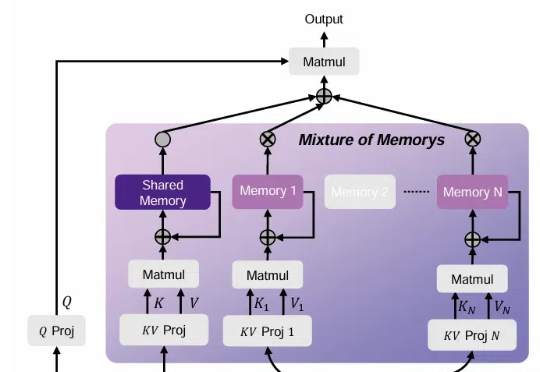
回顾 AGI 的爆发,从最初的 pre-training (model/data) scaling,到 post-training (SFT/RLHF) scaling,再到 reasoning (RL) scaling,找到正确的 scaling 维度始终是问题的本质。

谷歌终于更新了Transformer架构。最新发布的Mixture-of-Depths(MoD),改变了以往Transformer计算模式。它通过动态分配大模型中的计算资源,跳过一些不必要计算,显著提高训练效率和推理速度。