
谷歌版两门「小钢炮」开源!2.7亿参数干翻SOTA
谷歌版两门「小钢炮」开源!2.7亿参数干翻SOTA谷歌这波像开了「大小号双修」:前脚用Gemini把大模型战场搅翻,后脚甩出两位端侧「师兄弟」:一个走复古硬核架构回归,一个专职教AI「别光会聊,赶紧去干活」。手机里的智能体中枢,要开始卷起来了。
来自主题: AI资讯
10433 点击 2025-12-19 14:00
 搜索
搜索
谷歌这波像开了「大小号双修」:前脚用Gemini把大模型战场搅翻,后脚甩出两位端侧「师兄弟」:一个走复古硬核架构回归,一个专职教AI「别光会聊,赶紧去干活」。手机里的智能体中枢,要开始卷起来了。

6位前DeepMind成员以元系统重塑大模型调用方式,该系统推出的Gemini 3 Pro优化技术在ARC-AGI-2上以54%的成绩夺得榜首,而成本仅为此前最优方法的一半。

网友吐槽GPT-5.2「不通人性」。 X 上充斥着对 GPT-5.2 的恶评。昨天,OpenAI 十周年之际,拿出了最新的顶级模型 GPT-5.2 系列,官方号称是「迄今为止在专业知识工作上最强大的模型系列」,在众多基准测试中,GPT-5.2 也都刷新了最新的 SOTA 水平。

扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临

今日凌晨,比OpenAI早一个小时,谷歌甩出了3个Agent大招:Deep Research Agent功能更新,并首次向开发者开放;开源新网络研究Agent基准DeepSearchQA,旨在测试Agent在网络研究任务中的全面性;推出新交互API(Interactions API)。

今天我们正式发布 Jina-VLM,这是一款 2.4B 参数量的视觉语言模型(VLM),在同等规模下达到了多语言视觉问答(Multilingual VQA)任务上的 SOTA 基准。Jina-VLM 对硬件需求较低,可在普通消费级显卡或 Macbook 上流畅运行。
今日,美团正式发布并开源图像生成模型LongCat-Image,这是一款在图像编辑能力上达到开源SOTA水准的6B参数模型,重点瞄准文生图与单图编辑两大核心场景。在实际体验中,它在连续改图、风格变化和材质细节上表现较好,但在复杂排版场景下,中文文字渲染仍存在不稳定的情况。

作者在包含 50 多个任务的多个仿真和真实世界场景中评估了 SpatialActor。它在 RLBench 上取得了 87.4% 的成绩,达到 SOTA 水平;在不同噪声条件下,性能提升了 13.9% 至 19.4%,展现出强大的鲁棒性。目前该论文已被收录为 AAAI 2026 Oral,并将于近期开源。

在人工通用智能(AGI)的探索征程中,具身智能 Agents 作为连接数字认知与物理世界的关键载体,其核心价值在于能够在真实物理环境中实现稳健的空间感知、高效的任务规划与自适应的执行闭环。
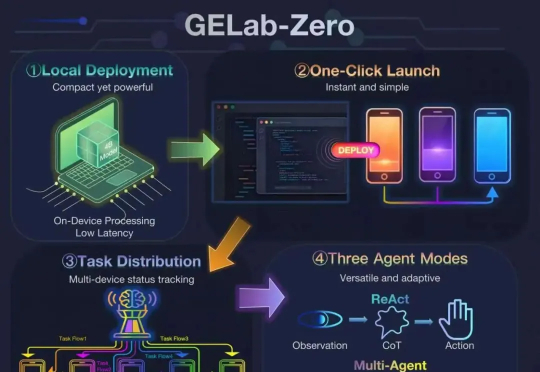
首次将GUI Agent模型与完整配套基建同步开放,支持手搓党一键部署!这就是阶跃星辰刚刚开源的GELab-Zero。其中4B版本的GUI Agent模型在手机端、电脑端等多个GUI榜单上全面刷新同尺寸模型性能纪录,取得SOTA成绩。