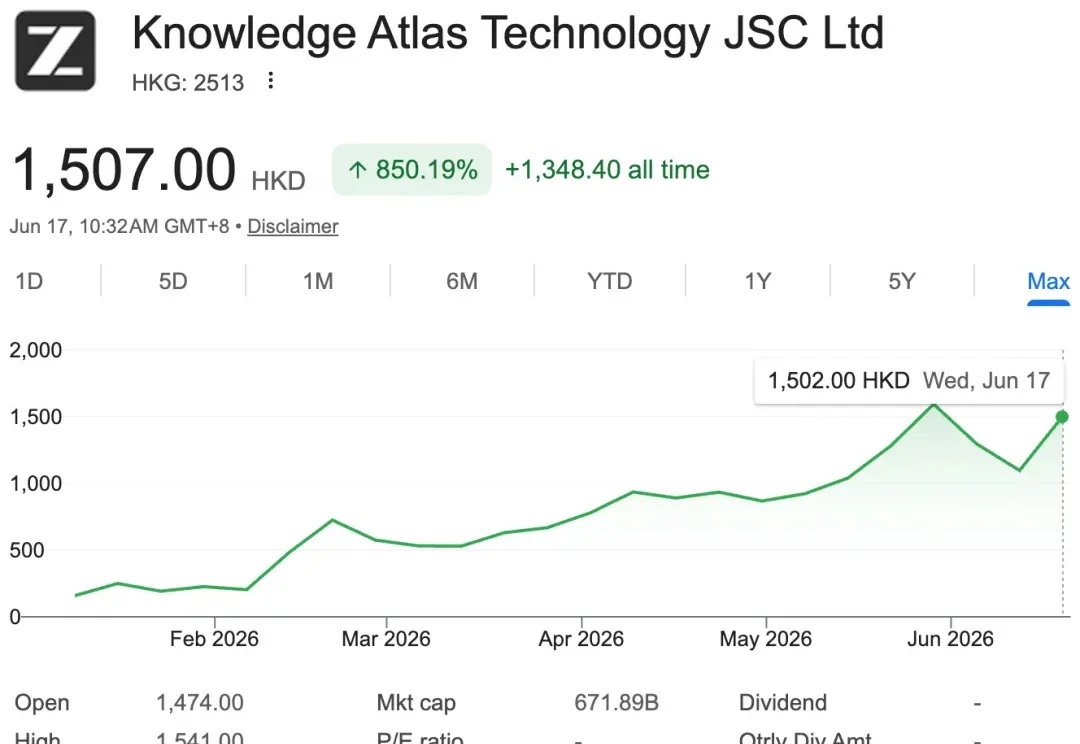
实测 GLM-5.2 :Claude 5 关停后,它真能稳稳接住这波用户
实测 GLM-5.2 :Claude 5 关停后,它真能稳稳接住这波用户前几天 Fable 5 对海外用户关停的时候,智谱突然宣布向 GLM Coding Plan 全量用户开放了 GLM-5.2,并表示「前沿智能不应只属于少数人,也不应被少数规则随手收回。」
来自主题: AI产品测评
6726 点击 2026-06-17 14:28
 搜索
搜索
前几天 Fable 5 对海外用户关停的时候,智谱突然宣布向 GLM Coding Plan 全量用户开放了 GLM-5.2,并表示「前沿智能不应只属于少数人,也不应被少数规则随手收回。」

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。

最近追《歌手》的同事说,胡彦斌已经跟咱是「同行」了——除了编歌,就是天天在办公室玩 Vibe Coding。
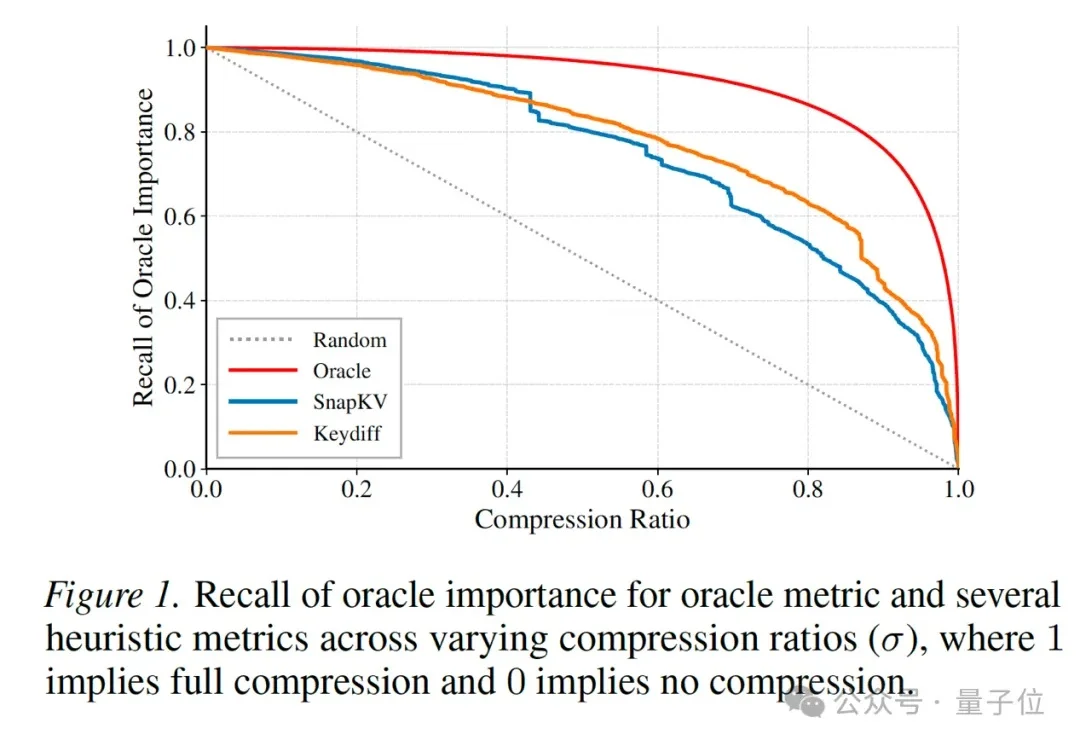
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。

最近整个世界的魔幻程度,真的让人唏嘘。 今天早上,Anthropic收到了美国商务部的一封信。 信的内容很简单,以国家安全为由,要求Anthropic立刻暂停所有外国公民对Fable 5和Mythos

GLM-5.2 是智谱迄今能力最强的开源模型,支持真正可用的 1M 上下文,并在长程任务中继续保持领先。它也依旧是我们心中最强的国产 Coding 模型。

全球大模型的军备竞赛,正在“智商”之外开辟新的战场—— 推理速度。

过去两年,大模型写代码已经不再新鲜。从代码补全到 GitHub issue 修复,从竞赛编程到仓库级软件工程,人们习惯用一个简单标准评估 coding agent:代码能不能写对?测试能不能通过?
当前,Coding Agents 在软件工程领域一路高歌猛进,科学家们看到此场景,也不禁寄予厚望:AI 智能体何时能以同样的速度,帮人类攻克药物设计、病毒监控与生物学建模的重重难关?

一年前,行业还在为“从自动补全到 Agent”的进化感到兴奋。然而一年过去,我们不难发现单纯靠“Vibe Coding”和“Prompt 调优”,面对非确定性模型带来的风险和成本问题,显然无法撑起企业级软件开发。