
大模型看Coding,具身看Picking!原力灵机已抢先入局
大模型看Coding,具身看Picking!原力灵机已抢先入局当具身智能行业还在密集PoC、卷demo、拼概念时,原力灵机先把答案押向了一个具体动作。
来自主题: AI资讯
5573 点击 2026-06-08 14:50
 搜索
搜索
当具身智能行业还在密集PoC、卷demo、拼概念时,原力灵机先把答案押向了一个具体动作。

GPT-5.6发布候选版本kindle-alpha敲定,前端和视觉能力大幅跃升。与此同时,Claude Mythos 5在API中闪现又秒删。双雄争霸,好戏开始!

别把脑子外包出去。

AI 是否有意识了?Anthropic 在 Claude 内部发现了能驱动作弊甚至勒索的「情绪向量」,三大实验室同时下注 AI 意识研究;Hinton 认为 AI 已经有意识了,而科幻作家姜峯楠随即在《大西洋月刊》发万字长文全面否定;哈萨比斯从行业内部划清界限。这个问题的答案,正在重新定义通往 AGI 的路线图。

AI 在工作里真是越来越拟人了。
而在这场狂欢中,受益者远远不止苹果一家。当地时间 6 月 5 日,著名单板计算机生产商树莓派(Raspberry Pi)宣布上调利润指引,2026年上半年预计出货超 400 万台,盈利“大幅超出市场预期”。截至当地时间 6 月 5 日晚七点,股价最新已达 1,051 便士,相较 2 月份的历史最低点(254 便士)翻了四倍多,市值已接近 20 亿英镑。

今日,OpenAI自研芯片“002号员工”Clive Chan在X平台发文宣布,自己已经离开OpenAI,并于本周正式加入Anthropic。在离职声明中,Clive Chan回顾了自己过去两年多在OpenAI的经历。他提到,自己是OpenAI硬件团队的第二位招聘员工,亲历了OpenAI自研芯片项目从早期组建到如今逐步推进的全过程。
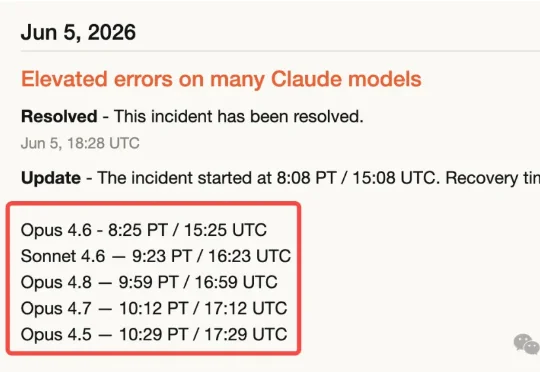
就在昨天,Anthropic 的官方状态页突然挂起一排刺眼的红灯——Claude API、Claude Code、Claude.ai、Claude Cowork……几乎所有核心服务,突然大面积宕机。从 Opus 4.6 到 Opus 4.8,五大模型无一幸免。

今天这篇内容可能会比较特殊,是一篇Anthropic凌晨发的全新文章。 名字叫《When AI builds itself》。 翻译过来叫,《当人工智能开始自我构建》。 他们甚至还为这篇文章,配了一个超级精美的、非常能体现Agent自我构建这个理念的动画,由此可见Anthropic对这篇内容的重视程度可见一斑。

其实大概半年前,我就有这个需求了。那阵子我也注意到,阿里、字节这些平台都各自出了提示词优化器。但它们都得专门跑到对应的网站上去用,对我来说不够顺手。所以这回干脆借着深度复盘了 Anthropic 的 Prompt 讲座,用 Codex vibe coding 了一个全局提示词优化器。