大模型给自己当裁判并不靠谱!上海交通大学新研究揭示LLM-as-a-judge机制缺陷
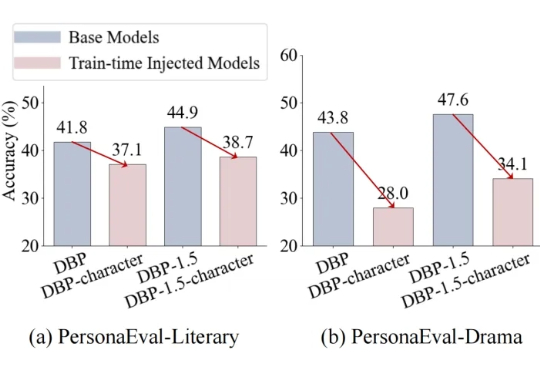
大模型给自己当裁判并不靠谱!上海交通大学新研究揭示LLM-as-a-judge机制缺陷大语言模型(LLM)正从工具进化为“裁判”(LLM-as-a-judge),开始大规模地评判由AI自己生成的内容。这种高效的评估范式,其可靠性与人类判断的一致性,却很少被深入验证。
来自主题: AI技术研报
8048 点击 2025-08-17 13:16
 搜索
搜索
大语言模型(LLM)正从工具进化为“裁判”(LLM-as-a-judge),开始大规模地评判由AI自己生成的内容。这种高效的评估范式,其可靠性与人类判断的一致性,却很少被深入验证。