
新PyTorch API:几行代码实现不同注意力变体,兼具FlashAttention性能和PyTorch灵活性
新PyTorch API:几行代码实现不同注意力变体,兼具FlashAttention性能和PyTorch灵活性用 FlexAttention 尝试一种新的注意力模式。
来自主题: AI资讯
10269 点击 2024-08-10 18:05
 搜索
搜索
用 FlexAttention 尝试一种新的注意力模式。
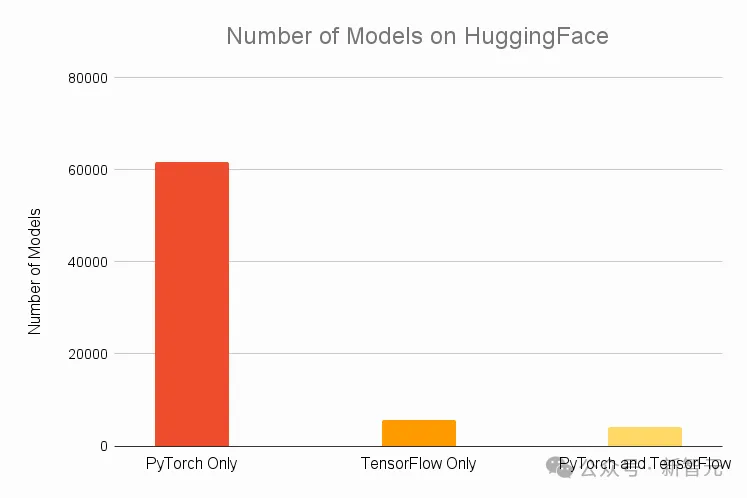
最近,PyTorch团队首次公布了开发路线图,由内部技术文档直接修改而来,披露了这个经典开源库下一步的发展方向。

Moshi 具有彻底改变人机通信的潜力。

一夜之间,微软的AI全宇宙已经成型。

AI 生产力的未来会是什么样子?全世界都在等待微软的答案。

Meta 正在不遗余力地想要在生成式 AI 领域赶上竞争对手,目标是投入数十亿美元用于 AI 研究。这些巨资一部分用于招募 AI 研究员。但更大的一部分用于开发硬件,特别是用于运行和训练 Meta AI 模型的芯片
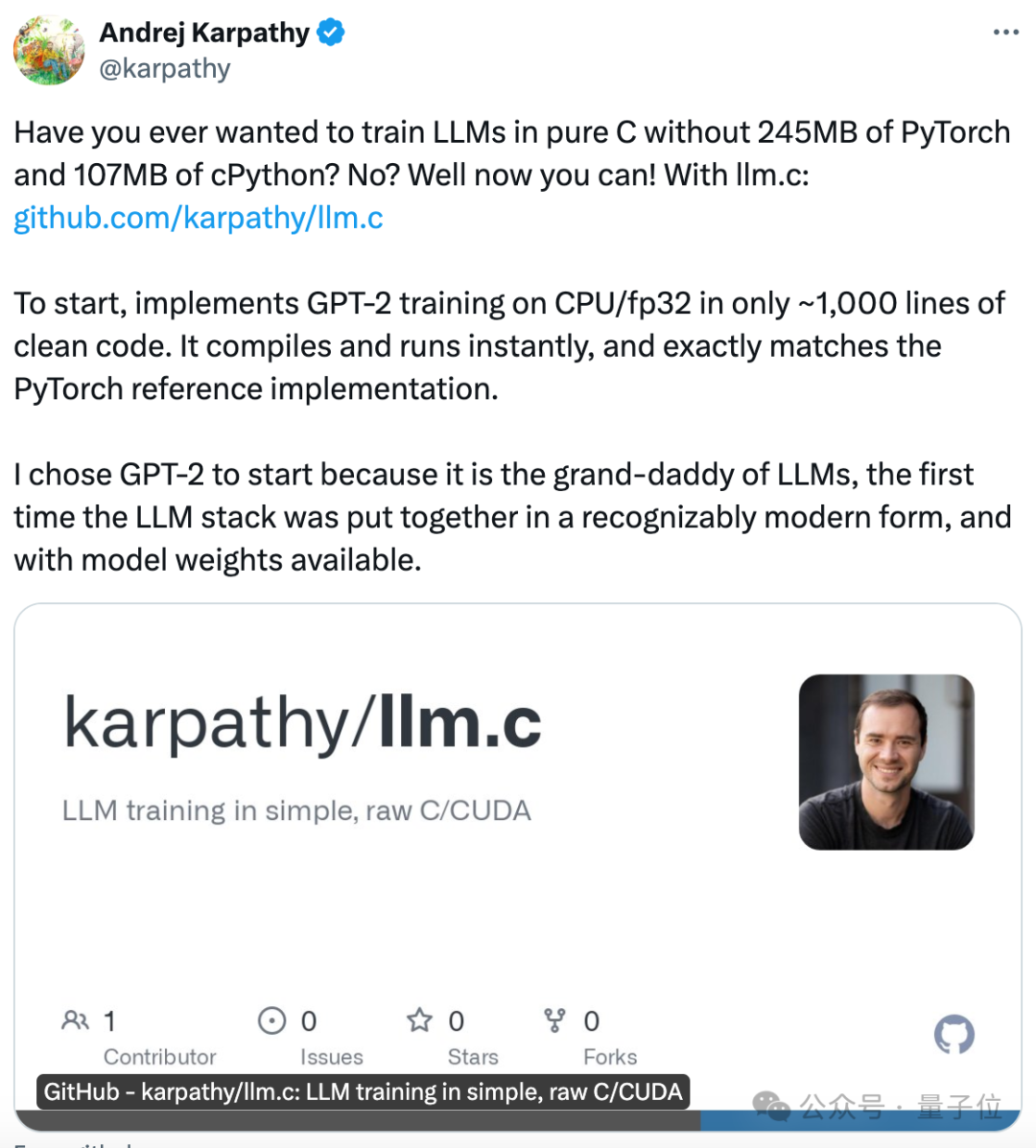
纯C语言训练GPT,1000行代码搞定!,不用现成的深度学习框架,纯手搓。 发布仅几个小时,已经揽星2.3k。

JAX在最近的基准测试中的性能已经不声不响地超过了Pytorch和TensorFlow,也许未来会有更多的大模型诞生在这个平台上。谷歌在背后的默默付出终于得到了回报。

马斯克说到做到开源Grok-1,开源社区一片狂喜。但基于Grok-1做改动or商用,都还有点难题: Grok-1使用Rust+JAX构建,对于习惯Python+PyTorch+HuggingFace等主流软件生态的用户上手门槛高。
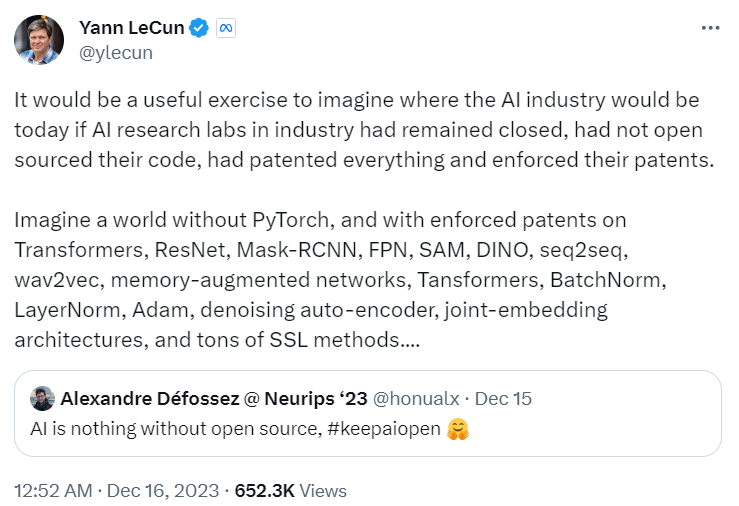
这两天,有关开源的话题又火了起来。有人表示,「没有开源,AI 将一无所有,继续保持 AI 开放。」这个观点得到了很多人的赞同,其中包括图灵奖得主、Meta 首席科学家 Yann LeCun。