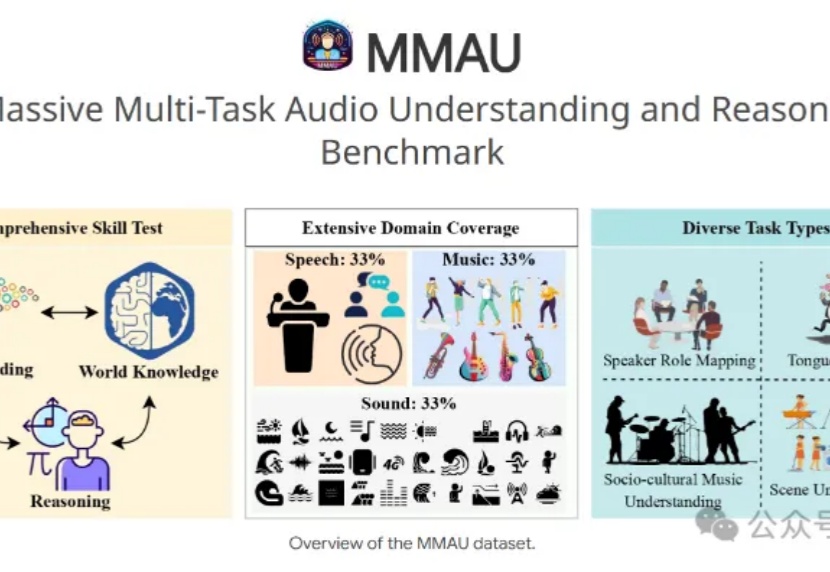
迁移DeepSeek-R1同款算法,小米让7B模型登顶音频理解推断MMAU榜单
迁移DeepSeek-R1同款算法,小米让7B模型登顶音频理解推断MMAU榜单7B小模型+3.8万条训练数据,就能让音频理解和推断评测基准MMAU榜单王座易主?
来自主题: AI技术研报
4922 点击 2025-03-17 10:52
 搜索
搜索
7B小模型+3.8万条训练数据,就能让音频理解和推断评测基准MMAU榜单王座易主?

日前,阿里国际站总裁张阔在接受《南华早报》等多家外媒专访时透露,面向海外买家推出的AI搜索引擎Accio企业用户已超百万。2月,阿里国际站的全线AI产品相继接入Qwen2.5、DeepSeek等先进推理模型,尤其是原生AI应用Accio的推出,让阿里国际站的AI应用引发全球高度关注。

见识过32B的QwQ追平671的DeepSeek R1后——刚刚,7B的DeepSeek蒸馏Qwen模型超越o1又是怎么一回事?新方法LADDER,通过递归问题分解实现AI模型的自我改进,同时不需要人工标注数据。
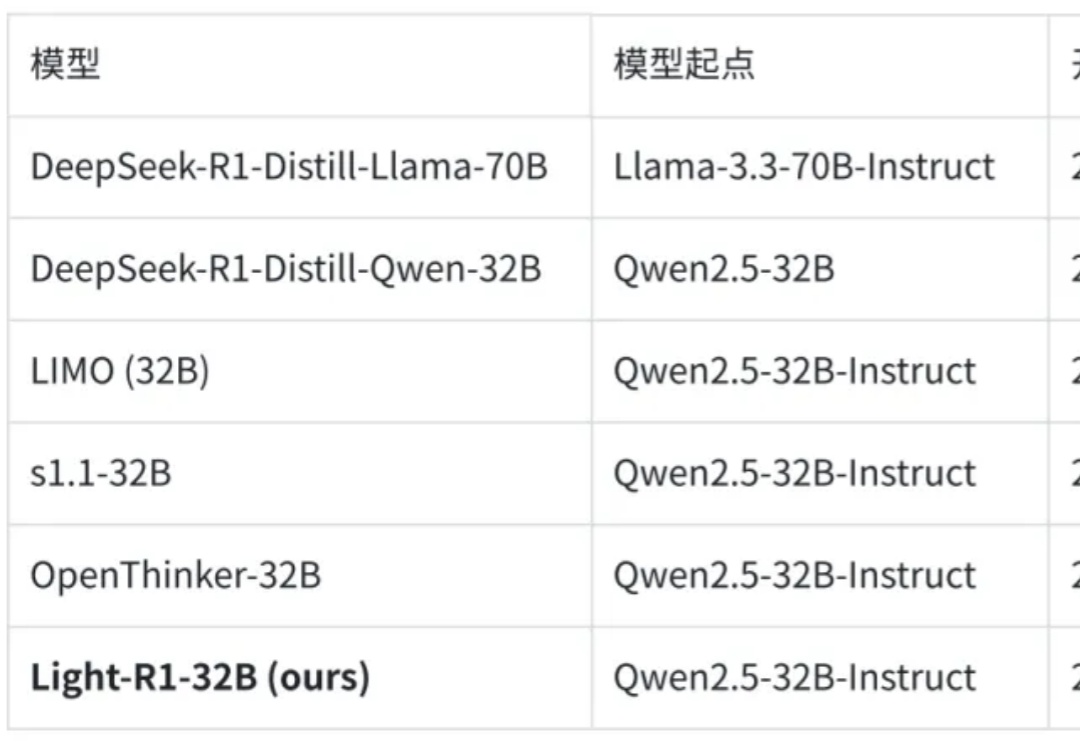
2025 年 3 月 4 日,360 智脑开源了 Light-R1-32B 模型,以及全部训练数据、代码。仅需 12 台 H800 上 6 小时即可训练完成,从没有长思维链的 Qwen2.5-32B-Instruct 出发,仅使用 7 万条数学数据训练,得到 Light-R1-32B

虽然 Qwen「天生」就会检查自己的答案并修正错误。但找到原理之后,我们也能让 Llama 学会自我改进。
给DeepSeek-R1推理指导,它的数学推理能力就开始暴涨。更令人吃惊是,Qwen2.5-14B居然给出了此前从未见过的希尔伯特问题的反例!而人类为此耗费了27年。研究者预言:LLM离破解NP-hard问题,已经又近了一步。
上周DeepSeek连续5天开源硬核技术,阿里开源万相2.1,Qwen的推理模型推出预览版,但是肯定马上也要开源。而今天,智谱这个曾经的开源之光,在昨天官宣拿了杭州10亿融资之后,在官宣文章里如此写道:
在大语言模型 (LLM) 的研究中,与以 Chain-of-Thought 为代表的逻辑思维能力相比,LLM 中同等重要的 Leap-of-Thought 能力,也称为创造力,目前的讨论和分析仍然较少。这可能会严重阻碍 LLM 在创造力上的发展。造成这种困局的一个主要原因是,面对「创造力」,我们很难构建一个合适且自动化的评估流程。
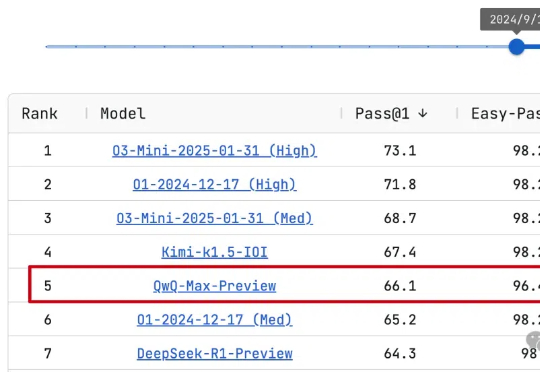
阿里通义Qwen团队熬夜通宵,推理模型Max旗舰版来了!QwQ-Max-Preview预览版,已在LiveCodeBench编程测试中排名第5,小超o1中档推理和DeepSeek-R1-Preview预览版。
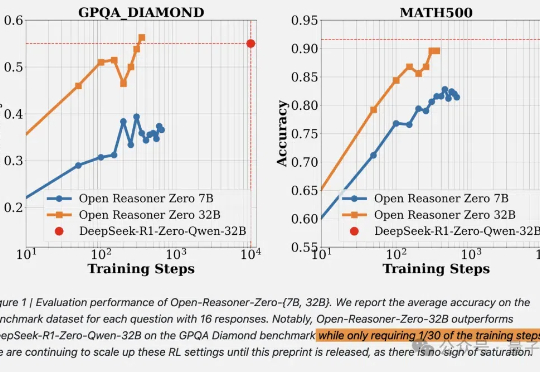
DeepSeek啥都开源了,就是没有开源训练代码和数据。现在,开源RL训练方法只需要用1/30的训练步骤就能赶上相同尺寸的DeepSeek-R1-Zero蒸馏Qwen。