
AMD跑DeepSeek性能超H200!128并发Token间延迟不超50ms,吞吐量达H200五倍
AMD跑DeepSeek性能超H200!128并发Token间延迟不超50ms,吞吐量达H200五倍DeepSeek-R1掀起新一轮购卡潮的同时,AMD的含金量也上升了。
来自主题: AI技术研报
9786 点击 2025-03-25 18:01
 搜索
搜索
DeepSeek-R1掀起新一轮购卡潮的同时,AMD的含金量也上升了。

本文介绍了当前最受科研人员青睐的AI模型,推理出色的o3-mini、全能型DeepSeek-R1、科研常用的Llama、编程利器Claude 3.5 Sonnet和开源明星Olmo 2,它们各有优劣,为科研人员提供了多样选择。

3月24日,从自然资源部获悉,国家海洋环境预报中心联合海洋出版社有限公司和三六零数字安全科技集团有限公司,以360智脑13B和Deepseek-R1-70B大模型为基座成功开发了海洋垂直领域大语言模型——“瀚海智语”(英文名称OceanDS)。
我发现对于 o1、R1 等推理模型们大家是又爱又恨,
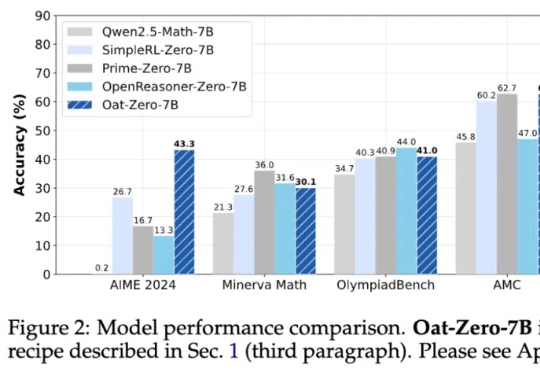
其实大模型在DeepSeek-V3时期就已经「顿悟」了?

首个基于混合Mamba架构的超大型推理模型来了!就在刚刚,腾讯宣布推出自研深度思考模型混元T1正式版,并同步在腾讯云官网上线。对标o1、DeepSeek R1之外,值得关注的是,混元T1正式版采用的是Hybrid-Mamba-Transformer融合模式——
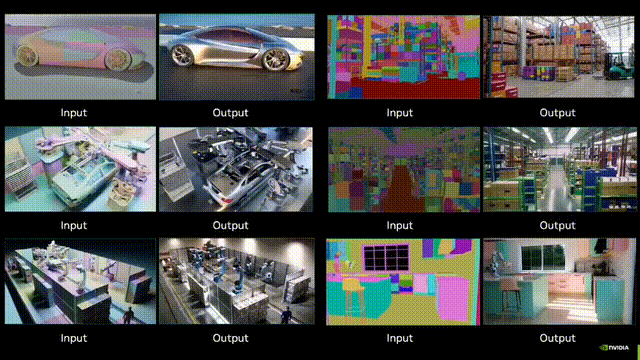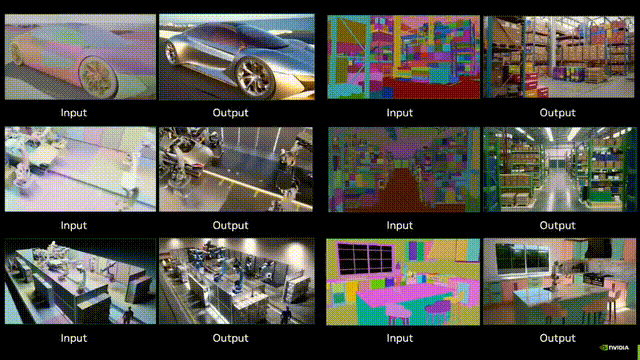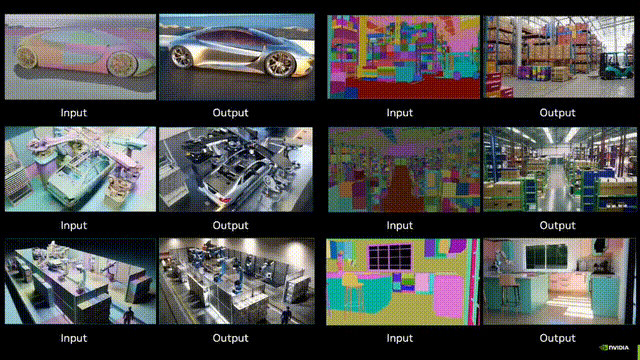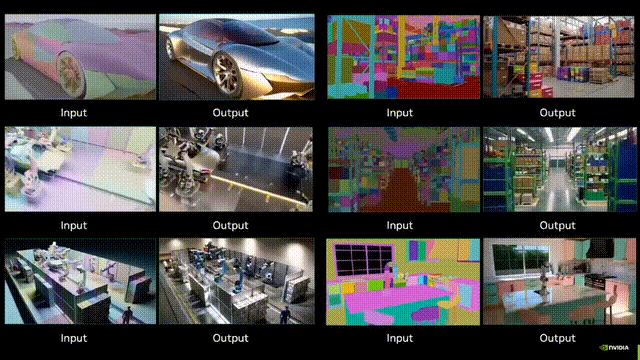
Nvidia刚刚发布了「世界生成」模型Cosmos-Transfer1,可以根据多种模态的空间控制输入(如分割、深度和边缘)生成世界模拟,使得世界生成具有高度可控性。开发者使用模型能够创建高度逼真的模拟环境,用于训练机器人和自动驾驶车辆。
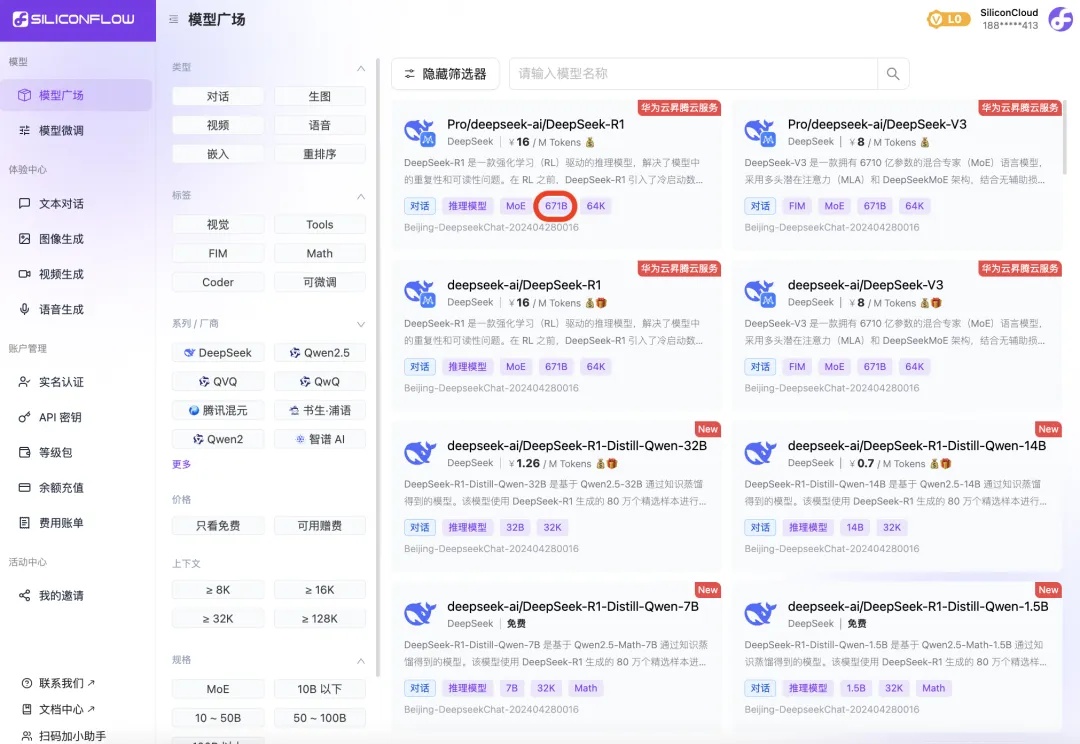
随着硅基流动的 SiliconCloud 等平台上线 DeepSeek-R1,市面上出现了不少测试各大厂商 API 服务的评测文章及反馈,不过,从我们收到的不少内容及反馈来看,其中的对比测试方式多有漏洞,内容质量参差不齐。
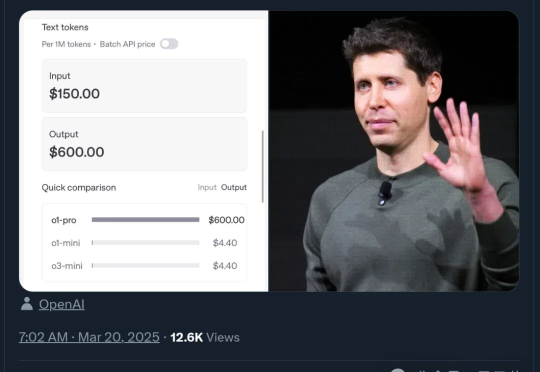
比DeepSeek-R1贵270倍,OpenAI史上最贵模型来了!
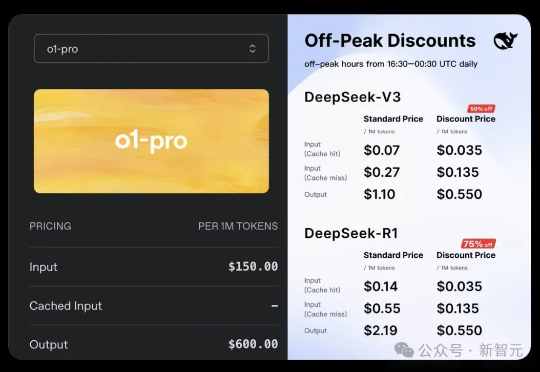
刚刚,OpenAI正式上线史上最贵API——o1-pro,输入/输出价格贵到离谱,最高可达DeepSeek-R1的千倍。OpenAI研究员戏称,大模型界的劳斯莱斯。