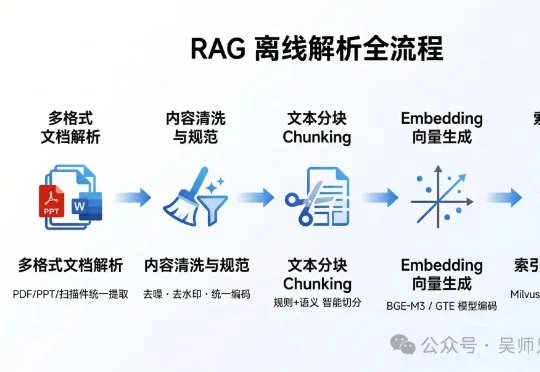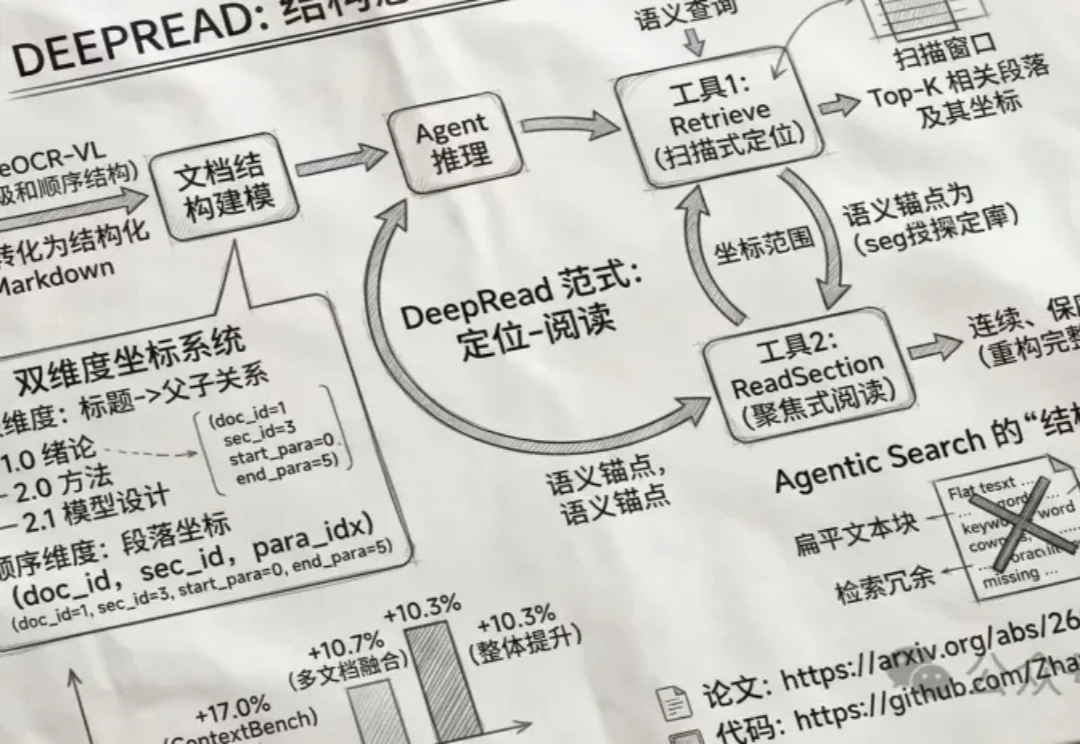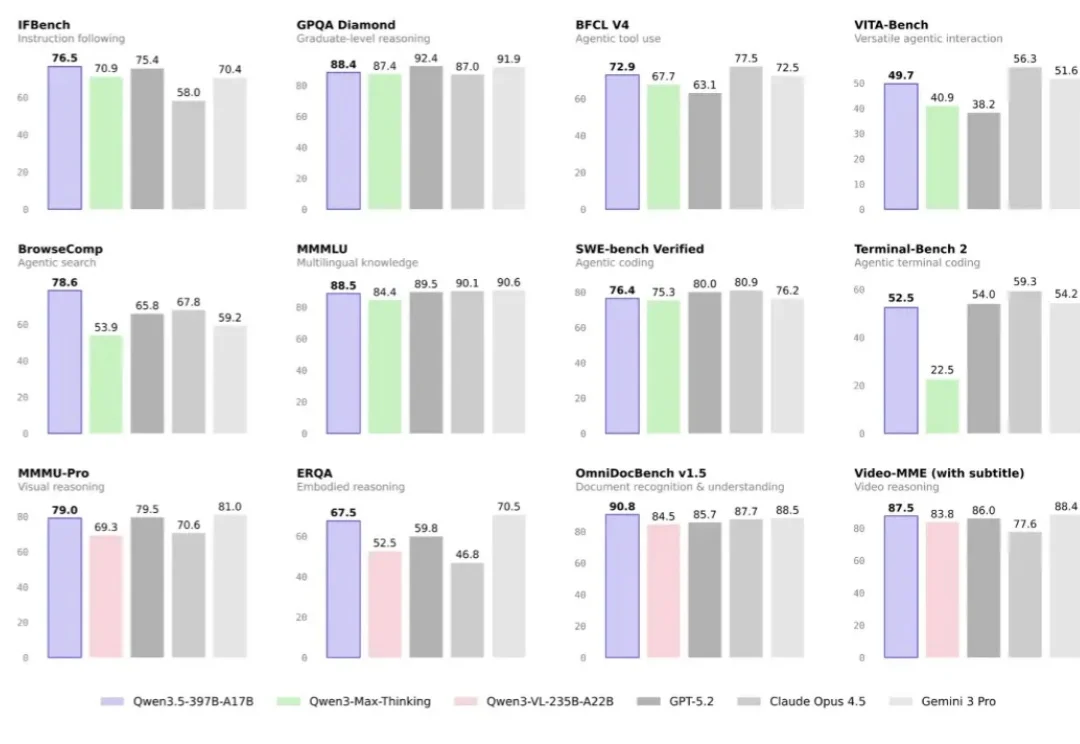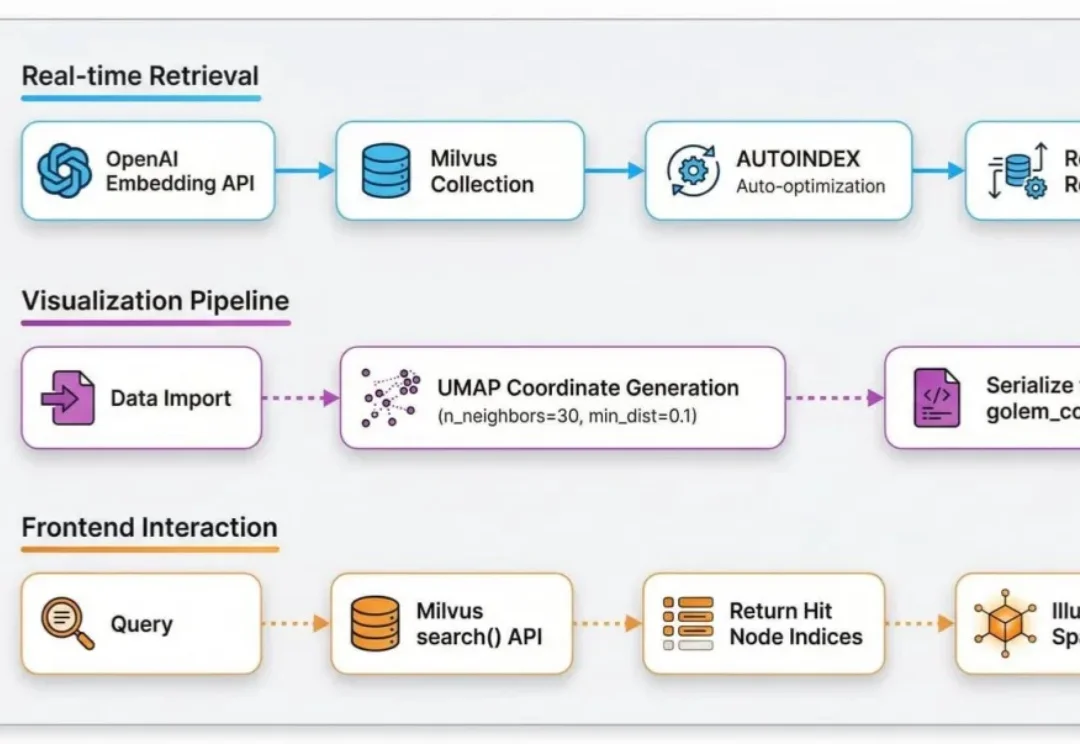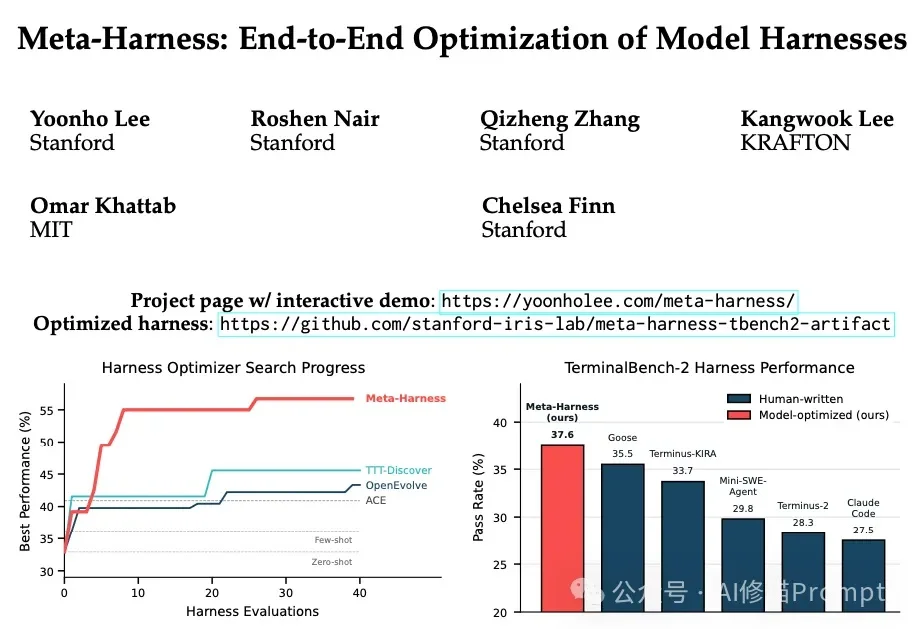
斯坦福MIT联合发布Meta-Harness,Agent端到端自己优化自己,Dspy一作Omar参与研究
斯坦福MIT联合发布Meta-Harness,Agent端到端自己优化自己,Dspy一作Omar参与研究去年讨论Agent落地时,重点往往是Context Engineering。大家都在琢磨怎么放 Few-shot,怎么优化 RAG 检索的文本片段。但随着 Agent 任务复杂度的上升,控制数据流向、工具调度和异常处理的底层脚手架代码,往往比单纯拼接文本对系统性能的影响更大。
来自主题: AI技术研报
8911 点击 2026-04-03 09:26